February 2009
Volume 24 Number 02
Best Practice - An Introduction To Domain-Driven Design
By David Laribee | February 2009
This article discusses:
|
This article uses the following technologies: Visual Studio |
Contents
The Platonic Model
Talk the Talk
Context
Know Your Value Proposition
A System of Single Responsibilities
Entities Have an Identity and a Life
Value Objects Describe Things
Aggregate Roots Combine Entities
Domain Services Model Primary Operations
Repositories Save and Dispense Aggregate Roots
The Thing with Databases
Getting Started with DDD
Domain-Driven Design(DDD) is a collection of principles and patterns that help developers craft elegant object systems. Properly applied it can lead to software abstractions called domain models. These models encapsulate complex business logic, closing the gap between business reality and code.
In this article, I'll cover the basic concepts and design patterns germane to DDD. Think of this article as a gentle introduction to designing and evolving rich domain models. To provide some context to the discussion, I'm using a complex business domain with which I'm familiar: insurance policy management.
If the ideas presented here appeal to you, I highly recommend that you deepen your toolbox by reading the book Domain-Driven Design: Tackling Complexity in the Heart of Software, by Eric Evans. More than simply the original introduction to DDD, it is a treasure trove of information by one of the industry's most seasoned software designers. The patterns and core tenets of DDD that I will discuss in this article are derived from the concepts that are detailed in this book.
Cutting Contexts by Architectural Need
Bounded Contexts needn't be organized solely by the functional area of an application. They're very useful in dividing a system to achieve desired architectural examples. The classic example of this approach is an application that has both a robust transactional footprint and a portfolio of reports.
It's often desirable in such circumstances (which might occur pretty often) to break out the reporting database from the transactional database. You want the freedom to pursue the right degree of normalization for developing reliable reports, and you want to use an Object-Relational Mapper so that you can keep coding transactional business logic in the object-oriented paradigm. You can use a technology such as Microsoft Message Queue (MSMQ) to publish data updates coming from the model and incorporate them into data warehouses optimized for reporting and analysis purposes.
This might come as a shock to some, but it's possible for database administrators and developers to get along. Bounded Contexts give you a glimpse of this promised land. If you're interested in architectural Bounded Contexts, I highly recommend keeping tabs on Greg Young's blog. He's quite experienced with and articulate about this approach and produces a fair amount of content on the subject.
The Platonic Model
Since we're just starting off here, it makes practical sense to define what I mean by model. Answering this question leads us on a short, metaphysical journey. Who better than Plato to guide us?
Plato, that most famous student of Socrates, proposed that the concepts, people, places, and things we intuit and perceive with our senses are merely shadows of the truth. He dubbed this idea of a true thing a Form.
To explain Forms, Plato used what's become known as the allegory of the cave. In this allegory, there exists a people that are bound inside a deep, dark cave. These cave people are chained in such a way that they can only ever see a blank wall of the cave that receives light from the opening. When an animal walks by the opening, a shadow is projected onto the interior wall that the cave dwellers see. To the cave dwellers, these shadows are the real thing. When a lion walks by, they point at the shadow of the lion and exclaim, "Run for cover!" But it is really only a shadow of the real Form, the lion itself.
You can relate Plato's theory of Forms to DDD. Much of its guidance helps us get closer to the ideal model over time. The path to the Form you want to describe with your code is scattered about in the minds of domain experts, the desires of stakeholders, and the requirements of industries in which we're working. These are, in a very real sense, the shadows to Plato's imaginary cave dwellers.
Furthermore, you are often constrained by programming languages and considerations of time and budget in trying to reach that Form. It's not much of a stretch to say these limitations are the equivalent of cave dwellers only ever being able to see the interior wall of shadows.
Good models exhibit a number of attributes independent of their implementation. The fact of the matter is, the mismatch between the model that's in everyone's head and the model you're committing to code is the first thing an aspiring domain modeler should understand.
The software you create is not the true model. It is only a manifestation—a shadow, if you will—of the application Form you set out to achieve. Even though it's an imitation of the perfect solution, you can seek to bring that code closer to the true Form over time.
In DDD, this notion is called model-driven design. Your understanding of the model is evolved in your code. Domain-driven designers would rather not bother with reams of documentation or heavy diagramming tools. They seek, instead, to imbue their sense of domain understanding directly into their code.
The idea of the code capturing the model is core to DDD. By keeping your software focused on the problem at hand and constrained to solving that problem, you end up with software receptive to new insights and moments of enlightenment. I like what Eric Evans calls it: crunching knowledge into models. When you learn something important about the domain, you'll know right where to go.
Talk the Talk
Let's examine some of the techniques DDD provides for achieving this goal. A big part of your job as a developer is working with non-coders to understand what you're meant to deliver. If you're working in an organization with any kind of process, you likely have requirements expressed as a user story, task, or use case. Whatever kind of requirements or specification you receive, is it usually complete?
Typically requirements are somewhat murky or expressed at a high level of understanding. In the course of designing and implementing a solution, it's beneficial when developers have access to the people who bring some expertise in the intended domain. This is exactly the point of user stories, which are typically expressed according to a template like this: as a [role], I want [feature] so that [benefit].
Let's take one example from the domain of insurance policy management: as an underwriter, I want approval control over a policy so that I can write safe exposures and reject risky ones.
Is there anyone who understands what that means? I know I didn't when I saw it written and prioritized. How can you possibly understand everything that will need to go into delivering the supporting software from this abstracted description?
User stories, properly done, are an invitation to have a conversation with their author—the user. This means when you go to work on the approve/deny policy feature, you should ideally have access to an underwriter. Underwriters, for the uninitiated, are domain experts (at least good ones are) who determine whether a certain category of exposure is safe for a carrier to cover.
When you begin discussing the feature with your underwriter (or whomever your project domain expert might be), pay especially close attention to the terminology the underwriter uses. These domain experts use company- or industry-standard terminology. In DDD, this vocabulary is called the Ubiquitous Language. As developers, you want to understand this vocabulary and not only use it when speaking with domain experts but also see the same terminology reflected in your code. If the terms "class code" or "rate sets" or "exposure" are frequently used in conversation, I would expect to find corresponding class names in the code.
This is a pretty fundamental pattern to DDD. At first blush, the Ubiquitous Language seems like an obvious thing, and chances are a good that number of you are already practicing this intuitively. However, it is critical that developers use the business language in code consciously and as a disciplined rule. Doing so reduces the disconnect between business vocabulary and technological jargon. The how becomes subordinate to the what, and you stay closer to the reason for your job: delivering business value.
Context
Developers are, in a sense, organizers. You sling code (hopefully with intent) into abstractions that solve problems. Tools such as design patterns, layered architectures, and object-oriented principles give a framework for applying order to evermore complicated systems.
DDD extends your organizational toolbox and borrows from well-known industry patterns. What I like most about the organizational patterns that DDD lays out is that there are solutions for every level of detail in a system. Bounded Contexts guide you toward thinking of software as a portfolio of models. Modules help you organize a larger single model into smaller chunks. Later, I'll cover aggregate roots as a technique for organizing small collaborations between a few highly related classes.
In most enterprise systems there are course-grained areas of responsibility. DDD calls this top level of organization a Bounded Context.
Workers' compensation insurance policies need to be concerned with elements such as:
- Quoting and sales
- General policy workflow (renewals, terminations)
- Auditing payroll estimation
- Quarterly self-estimates
- Setting and managing rates
- Issuing commissions to agencies and brokers
- Billing customers
- General accounting
- Determining acceptable exposures (underwriting)
Wow. That's a lot of stuff! You could incorporate all of this into a single, monolithic system, but doing so leads you down a foggy, amorphous path. People are talking about two entirely different things when they chat about a policy in the context of a general workflow versus a policy in the context of payroll auditing. If you use the same policy class, you're fattening the profile of that class and getting a long way from tried-and-true best practices such as the Single Responsibility Principle (SRP).
Systems that fail to isolate and insulate Bounded Contexts often slip into an architectural style (amusingly) called The Big Ball of Mud. In 1999, Brian Foot and Joseph Yoder defined the architectural style (or anti-architectural style, as the case may be) in their classic paper of the same name (" Big Ball of Mud").
DDD nudges you toward identifying contexts and constraining your modeling effort within particular contexts. You can use a simple diagram, called a context map, to explore the boundaries of our system. I've enumerated the contexts involved in a fully featured, insurance policy management system, and Figure 1takes this from a textual description to a (partial) graphical context map.
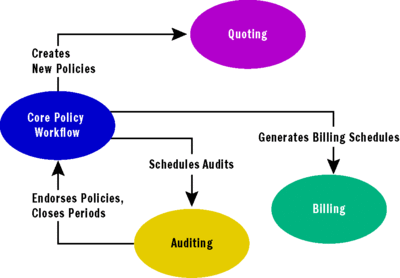
Figure 1 From Bounded Context to Context Map
Did you notice some key relationships among the various Bounded Contexts? This is valuable intelligence because you can start making informed business and architectural decisions such as packaging and deployment design; choice of technology used to marshal messages between models; and, perhaps most important, where you choose to set milestones and deploy effort, time, and talent.
One last but very important thought about Bounded Contexts: each context owns its own Ubiquitous Language. It's important to differentiate between the notion of a policy in the auditing subsystem versus the policy in core workflow because they're different things. While they may have the same identity, the value objects and child entities (more on these in a bit) are often radically different. Since you're modeling within context, you also want the language to provide precision within that context so you can have productive communication with domain experts and within your teams.
Some areas inside models group more closely together than others. Modules are a means of organizing these groups within a particular context, serving as mini-boundaries where you want to stop and think about associations to other modules. They are also another organization technique that leads you away from "Small Balls of Mud." Technologically, modules are easy to create; in the Microsoft .NET Framework they are simply namespaces. But the art of identifying modules involves spending a little time with your code. Eventually you may see a few things emerge as a mini-model within a model, at which time you may consider dividing things into namespaces.
Teasing apart models into cohesive modules has a nice effect in your IDE. Namely, since you need to use multiple using statements to include modules explicitly, you get a much cleaner IntelliSense experience. They also give you a way of looking at associations between larger conceptual chunks of your system with a static analysis tool such as NDepend.
Introducing an organizational change to your model should prompt you to engage in some pragmatic, cost-benefit thinking. When you use modules (or namespaces) to divide up your model, you really want to question whether you're dealing with a separate context. The cost of cleaving out another context is usually much higher: now you have two models, likely in two assemblies, that you need to connect with application services, controllers, and so on.
Anti-Corruption Layers
An Anti-Corruption Layer (ACL) is another DDD pattern that encourages you to create gatekeepers that work to prevent non-domain concepts from leaking into your model. They keep the model clean.
At their heart, repositories are actually a type of ACL. They keep SQL or object-relational mapping (ORM) constructs outside of your model.
ACLs are a great technique for introducing what Michael Feathers calls, in his book Working Effectively With Legacy Code, a seam. A seam is an area where you can start to cleave off some legacy code and begin to introduce changes.Finding seams, along with isolating your core domain, can be extremely valuable when using DDD techniques to refactor and tighten the highest value parts of your code.
Know Your Value Proposition
Most development shops have a handful of both seasoned businesspeople and top developers who are capable of isolating and describing a problem and building an elegant, maintainable object-oriented solution. To get the biggest bang for your customer's buck, you want to be sure to understand the core domain of your application. The core domain is the Bounded Context that brings the most value to applying DDD.
In any given enterprise system, there are some areas that are more important than others. The more important areas tend to fall into alignment with the core competencies of the client. It's rare that a business will be running custom general ledger software. But if that business is in insurance (going with my previous example) and their money-making offering is managing risk pools where liability is spread among all members, then they had better be darned good at rejecting bad risks and identifying trends. Or perhaps you have a client that's a medical claims processor, and their strategy is to flank their competition on pricing by automating payments to amplify the efforts of their bill payor workforce.
Whatever the industry, your employer or client has some edge in the market, and this edge is usually where you find the custom software. That custom software is where you're likely to find and model the core domain.
We can measure our investment in value on another dimension, namely where we invest our intellectual capital in reaching technical excellence. Too many times senior developers are the kind of people who get obsessed with new technologies. A certain amount of this is to be expected—the industry innovates at a relentless pace, and vendors are compelled to frequently release new technology offerings to satisfy their customers' demands and stay competitive. The challenge, as I see it, is for senior developers to master the fundamental principles and patterns that contribute value to the heart of a system. It's tempting to get wrapped up in a new framework or platform, but we need to remember the reason vendors produce these things is so we can just trust that they work.
A System of Single Responsibilities
I've mentioned that DDD provides a pattern language for structuring rich domain models. By implementing these patterns, you get a certain level of adherence to the SRP for free, and that's certainly valuable.
The SRP encourages getting at the core purpose of an interface or class. It guides you toward high cohesion—a very good thing, as it makes code easier to discover, reuse, and maintain.
DDD identifies certain types of class responsibilities in a core collection of patterns. I'll cover a few of the more primary ones now, but it's worth mentioning that there are many patterns described by Eric Evans in the original book ranging from class level to architectural. For introductory purposes, I'll stay at the class level covering entities, value objects, aggregate roots, domain services, and repositories. Because this is an introduction, I'll only cover the responsibility of each pattern with one to two code examples or tips each.
Entities Have an Identity and a Life
An entity is a "thing" in your system. It's often helpful to think about these in terms of nouns: people, places, and, well, things.
Entities have both an identity and a lifecycle. For example, If I want to access a particular customer in my system, I can ask for her by a number. When I complete a trading order, it's then dead to my system and can go to long-term storage (the historical reporting system).
Think of entities as units of behavior rather than as units of data. Try to put your logic in the entities that own them. Most times there's an entity that should receive some operation you're trying to add to your model, or a new entity is begging to be created or extracted. In more anemic code, you find a lot of service or manager classes that validate entities from the outside. In general, I much prefer to do that from within the entity—you get all the benefits associated with the fundamental principle of encapsulation, and you're making your entities behavioral.
Some developers are bothered by having dependencies in their entities. Obviously you need to create associations between the various entities in your system. For example, you might need to obtain a Product entity from the Policy entity so you can determine sensible defaults on the policy. Where people seem to fall down is when you need some outside service to perform behavior intrinsic to an entity.
I, for one, am not disturbed by the need to involve other, non-entity classes, and I would try to avoid lifting the central behavior outside of my entity. You should always remember that entities are intrinsically behavioral units. Often that behavior will be implemented as a kind of state machine—when you invoke a command on an entity, it is responsible for changing its internal state—but sometimes it's necessary for you to obtain additional data or impose side-effects upon the outside world. My preferred technique for accomplishing this is to provide the dependency to the command method:
public class Policy { public void Renew(IAuditNotifier notifier) { // do a bunch of internal state-related things, // some validation, etc. ... // now notify the audit system that there's // a new policy period that needs auditing notifier.ScheduleAuditFor(this); } }
The benefit of this approach is that you don't need an inversion of control (IOC) container to create an entity for you. Another perfectly acceptable approach, in my opinion, would be to use a Service Locator to resolve the IAuditNotifier inside the method. This technique has the benefit of keeping the interface clean, but I find the former strategy tells me a lot more about my dependencies at a higher level.
Value Objects Describe Things
Value objects are descriptors or properties important in the domain you are modeling. Unlike entities, they do not have an identity; they simply describe the things that do have identities. Are you changing an entity called "Thirty-Five Dollars" or are you incrementing the balance of an account?
Part of the beauty of value objects is that they describe the properties of entities in a much more elegant and intention-revealing way. Money, a common value object, looks a lot better as a function parameter on a funds transfer API than a decimal does. When you spot it in an interface or entity method, you know what you're dealing with right away.
Value objects are immutable. They are incapable of change once they are created. Why is it important that they be immutable? With value objects, you're seeking side-effect-free functions, yet another concept borrowed by DDD. When you add $20 to $20, are you changing $20? No, you are creating a new money descriptor of $40. In C# you can use the read-only keyword on public fields to enforce immutability and side-effect-free functions, as shown in Figure 2.
Figure 2 Using Read-Only to Enforce Immutability
public class Money { public readonly Currency Currency; public readonly decimal Amount; public Money(decimal amount, Currency currency) { Amount = amount; Currency = currency; } public Money AddFunds(Money fundsToAdd) { // because the money we're adding might // be in a different currency, we'll service // locate a money exchange Domain Service. var exchange = ServiceLocator.Find<IMoneyExchange>(); var normalizedMoney = exchange.CurrentValueFor(fundsToAdd, this.Currency); var newAmount = this.Amount + normalizedMoney.Amount; return new Money(newAmount, this.Currency); } } public enum Currency { USD, GBP, EUR, JPY }
Aggregate Roots Combine Entities
An aggregate root is a special kind of entity that consumers refer to directly. Identifying aggregate roots allows you to avoid over-coupling the objects that comprise your model by imposing a few simple rules. You should note that aggregate roots guard their sub-entities zealously.
The biggest rule to keep in mind is that aggregate roots are the only kind of entity to which your software may hold a reference. This helps avoid The Big Ball of Mud because you now have a constraint that prevents you from creating a tightly coupled system where everything has an association to everything else.
Let's assume I have an entity called Policy. Well, policies get renewed on an annual term, so there's likely an entity called Period. Since a Period cannot exist without a Policy and you can act on Periods through Policy, Policy is said to be an aggregate root and Period is a child of the same.
I like my aggregate roots to just figure it out for me. Consider this consumer code accessing a Policy aggregate root:
Policy.CurrentPeriod().Renew()
I'm trying to renew an insurance policy—recall the class diagram of the core domain of insurance policy management. Note how I'm dotting my way to the behavior I want to invoke?
There are a couple of problems with this approach. First, I'm clearly violating the Law of Demeter. A method M of an object O should invoke only the methods of the following kinds of objects: itself, its parameters, any objects it creates or instantiates, or its direct component objects.
Isn't deep dotting kind of convenient? IntelliSense is one of the coolest, most useful features of Visual Studio and other modern IDEs, but when you start dotting your way to the function you actually want to invoke, you're introducing unnecessary coupling into the system. In the previous example, I'm now dependent upon the Policy class and the Period class.
For further reading, Brad Appleton has an excellent article available on his site that explains the deeper implications, theories, tooling and caveats around the Law of Demeter.
The cliche "death by a thousand cuts" is a good description of the potential maintenance nightmare of an overly coupled system. When you create unnecessary references all over the place, you also create a rigid model where changes in one place result in a cascade of changes all over consumer code. You could accomplish the same goal with, as far as I'm concerned, a much more expressive bit of code:
Policy.Renew()
See how the aggregate just figures it out? Internally it can find the current period and whether or not there's already a renewal period and whatever else you need it to do.
I find that when I'm unit testing my aggregate roots using a technique such as Behavior-Driven Development (BDD), my tests trend toward the more black-box and state-testing paradigm. Aggregate roots and entities often end up as state machines, and the behavior matches accordingly. I end up with state validation, addition, and subtraction. There's quite a bit of behavior going on in the renewal example in Figure 3, and it's pretty clear how you can express this in a BDD style of test.
Figure 3 Testing Aggregate Roots
public class When_renewing_an_active_policy_that_needs_renewal { Policy ThePolicy; DateTime OriginalEndingOn; [SetUp] public void Context() { ThePolicy = new Policy(new DateTime(1/1/2009)); var somePayroll = new CompanyPayroll(); ThePolicy.Covers(somePayroll); ThePolicy.Write(); OriginalEndingOn = ThePolicy.EndingOn; } [Test] public void Should_create_a_new_period() { ThePolicy.EndingOn.ShouldEqual(OriginalEndingOn.AddYears(1)); } }
Domain Services Model Primary Operations
Sometimes you have operations or processes that do not have an identity or lifecycle in your domain. Domain services give you a tool for modeling these concepts. They're typically stateless and highly cohesive, often providing a single public method and sometimes an overload for acting on sets.
I like to use services for a few reasons. When there are a number of dependencies involved in a behavior and I can't find a natural place on an entity to place that behavior, I'll use a service. When my Ubiquitous Language talks about a process or operation as a first-order concept, I'll question whether a service makes sense as a central point of orchestration for the model.
You could use a domain service in the case of renewal. This is an alternative style. Rather than method injecting an IAuditNotifier directly into the method of the Policy entity's Renew method, you might choose to extract a domain service to handle dependency resolution for us; it's more natural for us to resolve a domain service from an IOC container than an entity. This strategy makes a lot more sense to me when there are multiple dependencies, but I'll present the alternative anyway.
Here is a short example of a domain service:
public class PolicyRenewalProcesor { private readonly IAuditNotifier _notifier; public PolicyRenewalProcessor(IAuditNotifier notifier) { _notifier = notifier; } public void Renew(Policy policy) { policy.Renew(); _notifier.ScheduleAuditFor(policy); } }
The word service is a highly overloaded term in the developer world. Sometimes I think of service as in service-oriented architecture (SOA). Other times I think of services as little classes that don't represent a particular person, place, or thing in my application, but that tend to embody processes. Domain services usually fall in this latter category. They tend to be named after verbs or business activities that domain experts introduce into the Ubiquitous Language.
Application services, on the other hand, are a great way to introduce a layered architecture. They can be used for mapping data inside the domain model to a shape required by a client application. For example, maybe you need to display tabular data in a DataGrid, but you want to maintain a granular and jagged object graph in your model.
Application services are also quite useful for integrating multiple models—for example, translating between policy auditing and core policy workflow. Similarly, I use them to bring infrastructure dependencies into the mix. Imagine a common scenario where you want to expose your domain model with Windows Communication Foundation (WCF). I'd use an application service decorated with the WCF attributes to make this happen rather than letting WCF leak into my pure domain model.
Application services tend to be very broad and shallow, embodying cohesive functionality. Consider the interface and partial implementation you see in the code in Figure 4as a good example of an application service.
Figure 4 A Simple Application Service
public IPolicyService { void Renew(PolicyRenewalDTO renewal); void Terminate(PolicyTerminationDTO termination); void Write(QuoteDTO quote); } public PolicyService : Service { private readonly ILogger _logger; public PolicyService(ILogger logger, IPolicyRepository policies) { _logger = logger; _policies = policies; } public void Renew(PolicyRenewalDTO renewal) { var policy = _policies.Find(renewal.PolicyID); policy.Renew(); var logMessage = string.Format( "Policy {0} was successfully renewed by {1}.", Policy.Number, renewal.RequestedBy); _logger.Log(logMessage); } }
Repositories Save and Dispense Aggregate Roots
Where do you go to retrieve entities? How do you store them? These questions are answered by the Repository pattern. Repositories represent an in-memory collection, and the conventional wisdom is that you end up with one repository per aggregate root.
Repositories are a good candidate for a super class or what Martin Fowler refers to as the Layer Supertype pattern. Using generics to derive a base repository interface from the previous example is a simple matter:
public interface IRepository<T> where T : IEntity { Find<T>(int id); Find<T>(Query<T> query); Save(T entity); Delete(T entity); }
Repositories prevent database or persistence concepts, such as SQL statements or stored procedures, from commingling with your model and distracting you from the mission at hand: capturing the domain. This separation of model code from infrastructure is a good attribute. See the sidebar "Anti-Corruption Layers" for a more detailed discussion.
At this point, you have likely noticed that I am not talking about how aggregate roots, their subordinate entities, and the attached value objects actually get persisted to disk. This is intentional. Saving the data required to perform behavior in your model is a concern orthogonal to the model itself. Persistence is infrastructure.
A survey of these technologies is far beyond the scope of an introduction to DDD. Suffice it to say there are a number of suitable and mature options for storing your model's data from Object-Relational Mapping (ORM) frameworks to document-oriented databases to "roll-your-own" data mappers for simple scenarios.
DDD Resources
Dan North on How to Structure User Stories
The Big Ball of Mud Architectural Style
Robert C. Martin's Paper on Single Responsibility Principle
Brad Appleton on Law of Demeter
Martin Fowler Describes the Layer Supertype Pattern
Robert C. Martin on the S.O.L.I.D. Principles
The Thing with Databases
By this point, I'm sure you've thought, "This is all well and good, Dave. But where do I save my entities?" Yes, you have to deal with this important detail, but how or where you persist your models is mostly tangential to an overview of DDD.
A number of developers or database admins will make the assertion that the database is the model. In a lot of cases, that's partially true. Databases, when highly normalized and visualized with a diagramming tool, can convey a lot about the information and relationships in your domain.
Data modeling as a primary technique leaves something to be desired, however. When you want to understand the behaviors inherent in the same domain, data-only techniques such as entity-relationship diagrams (ERDs) or entity-relationship models and class diagrams break down. You need to see the application's parts in motion and how types collaborate to get work done.
When I am modeling, I often reach for sequence diagrams on a whiteboard as a communications tool. This approach captures much of the essence of communicating a behavioral design or problem without the ceremony of Unified Modeling Language (UML) or model-driven architecture. I like to avoid unnecessary ceremony, especially when I'm going to erase the diagrams I put on the whiteboard. I don't worry about 100% UML adherence in my diagrams, preferring simple boxes, arrows, and swim lanes that I can sketch quickly.
If you don't already use sequence diagrams on your team, I highly recommend learning the technique. I've observed the powerful effect they have on getting team members to think through issues around the SRP, layered architecture, behavior design over data modeling, and architectural thinking in general.
Getting Started with DDD
Becoming proficient with object-oriented programming is no trivial undertaking. I believe competence is within the reach of most professional developers, but it takes dedication, book learning, and practice, practice, and more practice. It also helps if you adopt an attitude of craftsmanship and continual learning.
How do you get started? Simply put: do your homework. Learn about things like the S.O.L.I.D. principles and study Eric Evans' book. Your time investment will more than make up for itself. InfoQ has produced a smaller version of the DDD book that introduces a few key concepts. If you're on a financial or temporal budget or simply in investigation mode, I recommend starting there. Once you get a solid footing, wander over to the Yahoo! DDD group to see what issues your fellow designers are struggling with and get involved in the conversation.
DDD is not a new doctrine or methodology. It's a collection of time-tested strategies. When you get ready to practice, try adapting those philosophies, techniques, and patterns that make the most sense in your situation. Some elements of DDD apply more universally than others. Understanding the reason for your core domain's existence by uncovering and using the Ubiquitous Language and identifying the contexts in which we're modeling are way more important than nailing that perfectly opaque and one-size-fits-all repository.
When you're designing your solutions, design for value. If designers produce art and developers are a kind of designer, then our medium has to be business value. Value consciousness trumps considerations such as adherence to dogma and choice of persistence technology, as important as these choices sometimes seem.
Dave Laribee coaches the product development team at VersionOne. He is a frequent speaker at local and national developer events and was awarded a Microsoft Architecture MVP for 2007 and 2008.