February 2009
Volume 24 Number 02
Foundations - Error Handling In Workflows
By Matt Milner | February 2009
Contents
Handling Faults in Workflows
Handling Faults in the Host Process
Handling Faults in Custom Activities
Using Compensation
Retry Activity
Windows Workflow Foundation (WF) provides the tools to define rich business processes and a runtime environment to execute and manage those processes. In any business process, exceptions to the expected flow of execution occur, and developers need to be able to write robust application logic to recover from those exceptions. Most samples of any technology tend to overlook fault handling and proper recovery. In this month's installment, I will show you how to handle exceptions properly at several levels of the WF programming model and how to build rich exception handling capabilities into your workflows and hosts.
Handling Faults in Workflows
Developers building business processes must be able to handle exceptions to the business case to ensure that the process itself is resilient and can continue after failures occur. This is especially important with workflows, as they often define long-running processes, and an unhandled failure, in most cases, means having to restart the process. The default behavior for a workflow is that if an exception happens in the workflow and is not handled, the workflow will be terminated. Thus, it is crucial for workflow developers to correctly scope work, handle errors, and build into the workflows the ability to retry work when failures occur.
Handling faults in workflows has many things in common with handling faults in Microsoft .NET Framework-targeted code and a few new concepts. To handle a fault, the first step is to define a scope of execution. In .NET code, this is accomplished with the try keyword. In workflows, most composite activities can be used to create an exception handling scope. Each composite activity has the main view showing the child activities and also has alternate views. In Figure 1the context menu on a Sequence activity shows how various views can be accessed and the result of selecting the View Fault Handlers option.
.gif)
Figure 1 Alternate Views Menu and Selecting View Fault Handlers
When switching to the Fault Handlers view, a FaultHandlers activity is added to the activities collection of the Sequence activity. Within the FaultHandlers activity, individual FaultHandler activities can be added. Each of the FaultHandler activities has a property to define the fault type and acts like a catch expression in .NET.
The FaultHandler activity is a composite activity that allows workflow developers to add child activities that define how to handle the exception. These activities can provide functionality to log errors, contact administrators, or any other actions that you would normally take when handling exceptions in your code.
The FaultHandler activity also has a Fault property that contains the exception being caught. Child activities can bind to this property to get access to the exception. This is illustrated in Figure 2, where a custom logging activity has its exception property bound to the Fault property on the FaultHandler activity. The logging activity can now write the exception information to a logging API, the Windows Event Log, Windows Management Instrumentation (WMI), or any other destination.
.gif)
Figure 2 Binding to Faults
Like catch blocks, the FaultHandler activities are evaluated based on their fault types. When defining the workflow, the FaultHandler activities should be added to the FaultHandlers in order from the most specific fault to the least specific, left to right.
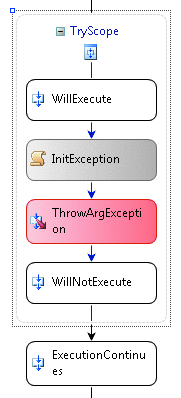
Figure 3 Execution Continues after the Composite
When an exception occurs and is caught in .NET code, after the catch block finishes the execution continues after the try scope. So in a workflow, execution continues with the next activity after the composite activity that handles the exception (see Figure 3).
There are two key concepts about how the FaultHandler activities are evaluated and executed. When the Throw activity executes (as in Figure 3), or another activity throws an exception, the runtime puts the activity in the faulted state and schedules the HandleFault method on the activity to execute. I will go into more detail on how activities implement this method shortly, but for now it is enough to know that this is the chance for the activity to clean up.
When the activity finishes cleaning up and moves to the closed state, the parent activity is put into the faulting state and is likewise given the chance to clean up any child activities and signal that it is ready to move to the closed state. It is at this point, when the composite activity signals that it is ready to move to the closed state, that the runtime checks the status and, when it is Faulting, examines the FaultHandlers collection. If a FaultHandler activity is found with a Fault type that matches the current exception, that FaultHandler is scheduled and the evaluation is halted. Once the FaultHandler closes, execution can then continue to the next activity.
When an exception occurs, the runtime will attempt to find fault-handling activities on the immediate parent composite activity. If no matching handlers are found, that composite is faulted and the exception bubbles up to the next composite activity in the tree. This is similar to how .NET exceptions bubble up the stack to the calling methods when they are unhandled. If the exception bubbles all the way to the root activity of the workflow and no handler is found, then the workflow is terminated.
Note that the workflow itself is a composite activity and, therefore, can have fault-handling logic defined to deal with exceptions that reach the top level. This is the last chance for a workflow developer to catch and handle exceptions in the business process.
Handling Faults in the Host Process
While creating robust workflows is important, having a host that can deal with exceptions is equally important to the stability of your application. Fortunately, the workflow runtime is robust in handling these exceptions out of the box and shields the host process from most exceptions bubbling up.
When an exception occurs in a workflow, bubbles up through the hierarchy, and is uncaught, the workflow will terminate and an event is raised on the runtime. The host of the runtime can register a handler to get notified when these exceptions occur, but the exceptions do not cause the host to crash. To get notified about these terminations, the host process can use code like the following to get information about the exception from the event arguments:
workflowRuntime.WorkflowTerminated += delegate( object sender, WorkflowTerminatedEventArgs e) { Console.WriteLine(e.Exception.Message); };
In addition to dealing with terminated workflows, the host process also has the ability to get notified about exceptions that occur in runtime services. For example, if SqlWorkflowPersistenceService is loaded into the runtime, it will poll the database and may try to load workflows periodically when they have further work to do. When attempting to load a workflow, the persistence service may throw an exception when trying to deserialize the workflow, for example. When this happens, it is again important that the host process not fail, which is why these services don't rethrow these exceptions. Instead, they raise an event to the workflow runtime. The runtime in turn raises a ServicesExceptionNotHandled event that can be handled in code, as shown here:
workflowRuntime.ServicesExceptionNotHandled += delegate( object sender, ServicesExceptionNotHandledEventArgs snhe) { Console.WriteLine(snhe.Exception.Message); };
In general, developers of runtime services have to make a choice when catching an exception about whether the exception is critical. In SqlWorkflowPersistenceService, not being able to load a single workflow does not mean the service cannot function. Therefore, it makes sense in this case to simply raise an event to allow the host process to determine whether further action is needed. However, if the persistence service cannot connect to the SQL Server database, then it cannot function at all. In that case, rather than raise an event, it makes more sense for the service to throw an exception and bring the host to a halt so that the issue can be resolved.
When developing custom runtime services, the recommended approach is to have those services derive from the WorkflowRuntimeService base class. This base class provides both access to the runtime and a protected method to raise a ServicesExceptionNotHandled event. When an exception occurs in the execution of a runtime service, the service should only throw that exception if it is truly an unrecoverable error. If the error is related to a single workflow instance and not the general execution of the service, then an event should be raised instead.
Handling Faults in Custom Activities
For activity authors, exception handling takes on a slightly different meaning. The goal with exception handling in activities is twofold: handle exceptions that occur to keep them, when possible, from bubbling up and disrupting the workflow and clean up properly in cases where an unhandled exception bubbles out of the activity.
Because an activity is simply a class, handling exceptions within the activity is no different than in any other class. You use try/catch blocks when calling other components that may throw errors. However, once you catch an exception in an activity, you must decide whether to rethrow the exception. If the exception is something that will not affect the outcome of the activity, or your activity has a more controlled way of indicating that it was not successful, this is the preferred way to provide that feedback. If, however, the exception means that your activity has failed and cannot complete its processing or provide an indication of the failure, then you should throw an exception so the workflow developer can design the business process to handle the exception.
The other facet of handling exceptions in activities is dealing with cleaning up activity resources. Unlike in a workflow, where fault handling is focused on the business process, logging, and notification, handling faults in activities is primarily focused on cleaning up the resources used in the activity execution.
The way you handle faults will also depend on whether you are writing a leaf activity or a composite activity. In a leaf activity, the HandleFault method is called when an unhandled exception is caught by the runtime in order to allow the activity to free up any resources that might be in use and clean up any execution that has begun. For example, if the activity is using a database during execution, in the HandleFault method it should make sure to close the connection if it isn't already closed and dispose of any other resources that might be in use. If the activity has begun any asynchronous work, this would be the time to cancel that work and free up the resources being used for that processing.
For a composite activity, when the HandleFault method occurs, it might be because of a logic error in the activity itself, or it may be because a child activity has faulted. In either case, the intent in calling the HandleFault method on a composite activity is to allow the activity to clean up its child activities. This cleanup involves making sure the composite doesn't request any more activities be executed and canceling any activities that are executing. Fortunately, the default implementation of the HandleFault method, defined in the CompositeActivity base class, is to call the Cancel method on the composite activity.
Cancellation is another mechanism that allows activities that have started some work asynchronously and are currently waiting for that work to complete to be notified that they should cancel the work they have started and clean up their resources so they can close. An activity may be canceled if another activity has thrown a fault, or under normal circumstances if the control flow logic of the parent composite activity decides to cancel the work.
When an activity is to be canceled, the runtime sets the status of that activity to Canceling and calls the Cancel method on the activity. For example, the Replicator activity can start several iterations of a child activity, one for each piece of data supplied, and schedule those activities to run in parallel. It also has an UntilCondition property that will be evaluated as each child activity closes. It is possible, and likely, that evaluation of the UntilCondition will cause the activity to determine that it should complete.
In order for the Replicator to close, it must first close all child activities. Since each of those activities has already been scheduled and is potentially executing, the Replicator activity checks the current value of the ExecutionStatus property and, if it is Executing, makes a request for the runtime to cancel that activity.
Using Compensation
Handling faults in workflows allows developers to deal with immediate exception conditions. The use of transactions also provides the ability to scope work together to ensure consistency. However, in long running workflows, it is possible that two units of work require consistency, but cannot use a transaction.
For example, once a workflow starts it may update the data in a line-of-business application, perhaps adding a customer into the CRM system. This work may even be part of a transaction to provide consistency across several operations in the CRM and with the state of the workflow. Then, after waiting for further input from a user, which may takes days to happen, the workflow updates an accounting system with the customer information. It is important that both the accounting system and the CRM system have consistent data, but it is not possible to use an atomic transaction for those resources across such a large time span. So the question becomes, how do handle exceptions that occur when updating the second system to ensure consistency with the changes already committed to the first system?
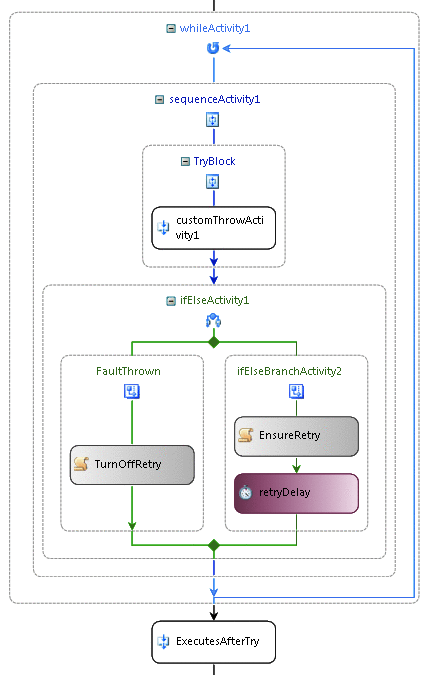
Figure 4 While Activity as Retry Logic
Because the work in the two systems cannot be made consistent with a transaction, what you need is a mechanism to detect errors that occur when updating the second system and provide an opportunity to go back and undo the work applied in the initial system, or otherwise make changes to ensure consistency. While the act of detecting this change and initiating this process can be automatic, the work of fixing the initial system obviously has to be specified by the developer.
In WF this process is referred to as Compensation and several activities are provided to help develop workflows that use compensation. For more information on compensation and how to use the compensation related activities, see Dino Esposito's Cutting Edge column on transactional workflows in the June 2007 issue of MSDN Magazine(" Transactional Workflows").
Retry Activity
One of the problems with dealing with exceptions in workflows is that, when an exception occurs, even if you catch it, the execution moves on to the next step in the process. In many business processes, execution really should not continue until the business logic defined in the workflows executes successfully. Developers often deal with this by using a While activity to provide retry logic and defining the condition of the activity to indicate that the activity should continue to execute as long as an error has occurred. Further, a Delay activity is often used to keep the retry logic from happening immediately.
To enable this retry model, you can employ a Sequence activity as the child of a While activity. Further, a specific unit of work in the sequence is often wrapped in another sequence or composite activity to handle the exceptions, acting as the fault-handling scope with all fault handlers defined in the Fault Handlers view. Then an IfElse activity is usually used to modify the state of the workflow to influence the condition on the While activity.
In the case where no exception occurs, the logic sets a property or flag of some sort so the While activity can close. If an exception did occur, then the flag is set to cause the while activity to execute again, and a Delay activity is used to pause before making the next attempt. Figure 4shows one example of using the While activity to retry activities in a workflow.
While this particular pattern works in many scenarios, imagine a workflow with 5 or 10 different operations that need to be retried. You will quickly realize that it is a lot of work to build the retry logic for each activity. Fortunately, WF enables developers to write custom activities, including custom composite activities. That means I can write my own Retry activity to encapsulate executing the child activities again when an exception occurs. For this to be valuable, I want to provide two key inputs for users: a delay interval between retries, and a maximum number of times to retry the work before letting the exception bubble up and be handled.
In the remainder of this column, I will detail the logic in the Retry activity. For background information on creating custom activities, see my previous article (" Windows Workflow: Build Custom Activities to Extend the Reach of your Workflows", and for more information on using the ActivityExecutionContext to create activities that can iterate over a child activity, see the June 2007 installment of this column (" ActivityExecutionContext in Workflows").
To manage the child activity correctly, it is important to be able to monitor the activity to know when errors occur. Thus, when executing the child activity, the retry activity not only registers to get notified when the child activity closes, but also registers to get notified when the child activity is put into a Faulting state. Figure 5shows the BeginIteration method used to start each iteration of the child activity. Before scheduling the activity, the Closed and Faulting events have handlers registered.
Figure 5 Executing Child Activities and Registering for Faults
Activity child = EnabledActivities[0]; ActivityExecutionContext newContext = executionContext.ExecutionContextManager.CreateExecutionContext(child); newContext.Activity.Closed += new EventHandler<ActivityExecutionStatusChangedEventArgs>(child_Closed); newContext.Activity.Faulting += new EventHandler<ActivityExecutionStatusChangedEventArgs>(Activity_Faulting); newContext.ExecuteActivity(newContext.Activity);
Normally if a child activity faults, the parent activity would also be put in the faulting state. In order to avoid that situation, when the child activity faults, the Retry activity checks to see whether the activity has already been retried the maximum number of times. If the retry count has not been reached, then this code nulls out the current exception on the child activity, thus suppressing the exception:
void Activity_Faulting(object sender, ActivityExecutionStatusChangedEventArgs e) { e.Activity.Faulting -= Activity_Faulting; if(CurrentRetryAttempt < RetryCount) e.Activity.SetValue( ActivityExecutionContext.CurrentExceptionProperty, null); }
When the child activity closes, the logic must determine how the activity got to the closed state and uses the ExecutionResult property to do so. Since all activities end in the Closed state, the ExecutionStatus does not provide the information needed to determine the actual outcome, but the ExecutionResult indicates whether the activity faulted, succeeded, or was canceled. If the child activity succeeded, then no retry is needed and the Retry activity simply closes:
if (e.ExecutionResult == ActivityExecutionResult.Succeeded) { this.SetValue(ActivityExecutionContext.CurrentExceptionProperty, null); thisContext.CloseActivity(); return; }
If the result from the closing activity is not success, and the retry count hasn't been reached, then the activity must be executed again, but not before the retry interval has expired. In Figure 6, instead of beginning another iteration directly, a timer subscription is created using the interval configured on the activity.
Figure 6 Creating a Timer Subscription
if (CurrentRetryAttempt++ < RetryCount && this.ExecutionStatus == ActivityExecutionStatus.Executing) { this.SetValue(ActivityExecutionContext.CurrentExceptionProperty, null); DateTime expires = DateTime.UtcNow.Add(RetryInterval); SubscriptionID = Guid.NewGuid(); WorkflowQueuingService qSvc = thisContext.GetService<WorkflowQueuingService>(); WorkflowQueue q = qSvc.CreateWorkflowQueue(SubscriptionID, false); q.QueueItemAvailable += new EventHandler<QueueEventArgs>(TimerExpired); TimerEventSubscription subscription = new TimerEventSubscription( SubscriptionID, WorkflowInstanceId, expires); TimerEventSubscriptionCollection timers = GetTimerSubscriptionCollection(); timers.Add(subscription); return; }
When the timer expires, the TimerExpired method will be invoked, as shown here:
void TimerExpired(object sender, QueueEventArgs e) { ActivityExecutionContext ctx = sender as ActivityExecutionContext; CleanupSubscription(ctx); BeginIteration(ctx); }
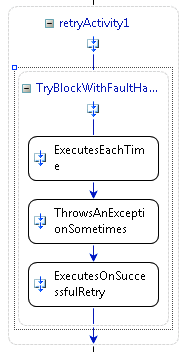
Figure 7 The Retry Activity in a Workflow
This will begin the next iteration of the child activity. By using the TimerEventSubscription class and adding the timer to the workflow's timer collection, the activity is able to correctly participate in persistence and resumption with whatever persistence service is currently configured in the runtime. If the retry interval is long, the entire workflow can be taken out of memory until the timer expires.
The key behavior of the workflow activity has been met at this point. If a child activity faults, the retry activity will not fault. Instead it will pause for the retry interval, then attempt to execute the child activity again.
The final step is to deal with the case where the activity has reached the retry count and the child activity has continued to fail. In this case, the Activity_Faulting method does not clear the exception on the child activity, as the goal is to let that activity fault as normal. And when the child activity closes, the Retry activity also closes.
When the Retry closes after all retry attempts have failed, the result is the same as if the original work had failed in a sequence. The Retry activity can have FaultHandler activities defined and those fault handlers will only execute after all retries have been executed. Using this model simplifies the development of workflows with actions that may need to be retried, yet maintains the same development experience for workflow developers in regard to handling faults as shown in Figure 7.
In addition, the fault handlers will be executed for the child activity when the retry attempts have failed, so workflow developers can choose to handle the faults on either activity. The HandleFault method gets called on the child activity for each failure, ensuring that the activity has a chance to clean up on each iteration.
Send your questions and comments to mmnet30@microsoft.com.
Matt Milner is a member of the technical staff at Pluralsight, where he focuses on connected systems technologies. Matt is also an independent consultant specializing in Microsoft .NET technologies with a focus on Windows Workflow Foundation, BizTalk Server, ASP.NET, and Windows Communication Foundation. Matt lives in Minnesota with his wife, Kristen, and his two sons.