June 2009
Volume 24 Number 06
CLR Inside Out - Memory Usage Auditing For .NET Applications
By Subramanian Ramaswamy | June 2009
Contents
When Memory Usage Affects Speed
What Can Be Done?
Task Manager
Shared Versus Unshared Memory
Application Size
VADump: A More Detailed View
The .NET Garbage Collector
PerfMon
Conclusion
Performance optimization is about one thing: making computer programs run faster. The execution of instructions is cheap for modern computer hardware while the fetching of instruction operands is expensive. Thus, memory usage can have a direct impact on how fast an application executes and is an important metric to optimize. In this article, we discuss the basics of memory optimization for .NET programs. First, we outline the cases where memory access is a bottleneck and is useful to optimize. Next, we discuss the general breakdown of how memory is used in a typical .NET program. Lastly, we discuss tools and strategies to determine the memory consumption of your .NET application and reduce it.
When Memory Usage Affects Speed
The first case of when memory consumption matters is a CPU-intensive application that is manipulating a large amount of data. A typical PC can execute an instruction in less than half a nanosecond (0.5 ns). However, that speed is limited by how long it takes to fetch the operands from memory. Modern processors have a hierarchy of caches to optimize the cost of hardware. The level-1 (L1) cache is the fastest memory, but is relatively small. Next in the hierarchy is the level-2 cache, followed by the main memory (RAM), and finally the hard disk drive. Figure 1 shows the access time and sizes of the various parts of the memory hierarchy for a typical PC. At every step deeper into the memory hierarchy, the access time (and size) increases by an order of magnitude or more (hard drives are a 10,000 times slower than RAM) while the cost (per byte) decreases.
Figure 1 Size and Access Times with Non-local Storage
| L1 Cache | L2 Cache | Memory (RAM) | Disk | |
| Size | 64K | 512K | 2000M | 100,000M |
| Access Time | .4 ns | 4 ns | 40 ns | 4,000,000 ns |
If hot data paths access more memory, then the operands will frequently need to be fetched from slower memory. Since the slower memory is slower by an order of magnitude, a few Level-2 cache misses can have a significant performance impact.
The second case of when (some) memory consumption matters is during an application's cold startup. As Figure 1 shows, hard disk access is much slower than main memory access. The operating system tries to mitigate this by caching data from the disk in main memory. This is the reason that an application is faster when launched the second time, during what is called warm startup (the data was cached in faster memory). For the first (cold) startup, caching has not yet happened and data has to be fetched from disk. The only way to improve this is to load less data from the disk. Only memory fetched from the disk (such as the program instructions) affects cold startup; memory initialized by the program itself, including all data on the heap and stack, does not affect cold startup.
The final case when memory consumption matters is during application switching. When your application is reasonably large (larger than 50MB), and a user switches to other applications, these applications steal the physical memory of your application. When the user returns to your app, these stolen pages need to be fetched back from the disk, which makes your app very slow. This is similar to the cold startup case except that it affects not just program instructions, but all memory—including memory that was initialized by your application. Since servers run many unrelated programs simultaneously and continuously, servers are application switching constantly; this means that memory is almost always an issue for servers.
What Can Be Done?
If code could be magically rearranged to ensure all memory requests were satisfied in the fast caches, the program would speed up substantially. In practice, this is only possible in unusual circumstances because ordinarily the program's algorithms dictate the order of memory accesses. A more feasible technique is to minimize the amount of memory used. This reduces the load on the fast caches and makes the program faster. For data structures having frequently accessed (hot) parts that do not fit in CPU caches (typically they would be larger than several megabytes), a 30 percent reduction in the memory size of hot data typically results in a 10 percent improvement in CPU speed.
Memory can be reduced in three ways. First, you can execute less code (which helps cold startup). This applies to obvious cases where something was computed inefficiently in the first place. Second, you can touch less data. This is similar to the first strategy, but it applies to the data structures involved. Finally (and perhaps most commonly), the data structure can be encoded in a different way, making it smaller, or by physically separating the (small) commonly accessed data from the (large) uncommonly accessed part.
These techniques typically require a change in the representation of the data and require changes to a large number of code sites to implement. Thus, it is much easier to make these changes early in the development cycle, so it pays to think about memory early!
Task Manager
The first step in reducing the memory consumption of your application is to understand how much of it is currently used. For that you can use the Windows built-in Task Manager application.
Most users are already familiar with task manager. You can invoke it by typing taskmgr in your run command window (Winkey+R), or by pressing Ctrl+Alt+Del and selecting "Start Task Manager". On the "Processes" tab, you will find information on all the system's currently running processes. If the columns don't include PID, Memory-Working Set and Memory-Private Working Set, use the View | Select Columns' menu option to add them to the display.
Shared Versus Unshared Memory
The working set is the physical memory currently being used by the process. However, the operating system performs optimizations to ensure that all memory is not equally expensive. Much of the memory a process uses holds read-only data (for example, the actual instructions to execute). Because this data is read-only it can be shared among all processes that need it. Since all processes make extensive use of shared, read-only operating system code, a substantial amount of every process's working set is shared. Thus, total working set tends to significantly overestimate the true cost of the memory used by a process.
The operating system also keeps track of unshared (Private) memory. This includes all read-write memory used by the process. While private working set underestimates the true cost of memory used by a process (we will see how when we discuss the tool VADump), it tends to be a better metric to optimize, because unlike optimizing shared memory, any gains in private memory will reduce the total memory pressure on the machine.
Finally, both total and private memory counts miss an important memory used by a process: the file system cache. Because hard disk access is so expensive, even when a file's data is not mapped directly into memory, it is cached by the operating system. This memory use increases memory pressure on the system, and is not included in either of the working set metrics (it is owned by the operating system). There is not much that can be done about file access (if your program needs a file, it can't be avoided), so it can be considered a cost that can't be optimized.
Application Size
An application may be categorized as small, medium, or large depending on its memory usage. A small application has a 20MB or smaller working set size with a smaller than 5MB private working set; a medium application has a working set size of approximately 50MB with about 20MB private working set; a large application typically has working set sizes greater than 100MB, with private working set sizes exceeding 50MB. The larger your application, the more valuable optimizing your application's memory usage is likely to be.
A simple and quick way to monitor memory usage and check for leaks is by running a sniff test on your application. Run the application for a while and monitor its working set usage; if the working set grows unbounded, that can mean a memory leak or other issues.
VADump: A More Detailed View
Task Manager provides only a summary of the memory usage of an application. To get more detail you need a tool called VADump (see the Resources sidebar). This is invoked by typing VADump –sop ProcessID in the command prompt under the directory in which VADump is installed. It prints a breakdown of memory within a single process down to DLL level of granularity. A typical dump is shown in Figure 2.
.gif)
Figure 2 VADump Output Opened in Notepad
To read the dump, start with grand total working set. This number should agree with the number in Task Manager. This number is then broken down into eight categories. The most interesting of these categories are:
- Code/Static Data, which represents DLLs that were loaded by the process.
- Heap, which represents native (not GC) heap memory used.
- Other Data, which represents memory allocated using the OS VirtualAlloc function. For managed code this is important because it includes the entire garbage-collected heap.
Performance Resources
CLR Perf Team Blog (Instructions on investigating suspicious DLL loads):
VS Profiler Team Blog:
Improving .NET Application Performance and Scalability:
msdn.microsoft.com/library/ms998530
Windows performance blog: Investigations using Xperf:
Vance Morrison's Blog:
Rico Mariani's Blog:
Lutz Roeder .NET Reflector for inspecting code:
CLR Inside Out - Investigating Memory Issues:
msdn.microsoft.com/magazine/cc163528
The memory used by DLLs is further broken down by VADump after the summary table. For each DLL, it shows the number of pages (a page is always 4K) that each DLL uses. Thus, one can determine the memory cost of all the code that is loaded.
In Figure 2, there is a row labeled "Grand Total Working Set." The total working set in Kilobytes and Pages is in the first column. Columns 2, 3 and 4 (Private Kbytes, Shareable Kbytes and SharedKBytes) add up to the Total Working Set column. It is Column 2, the Private Kbytes value, that is depicted as Private Working Set in TaskManager, whereas Column 1 is shown as Total Working Set in TaskManager. Thus, VADump allows you to see the separation between private and total working sets, including shareable and shared working sets. This is a more complete picture than what is available through TaskManager.
When .NET applications are large, they are typically large either because they run a lot of code or they use a lot of data.
In this case, you will see a large number of DLLs loaded and the Code/Static Data contribution tends to dominate the total working set. For managed applications, this data is in the GC heap and thus shows up as Other Data dominating the working set.
In the lower part of Figure 2, you see module working sets (in pages) listed. This tells you which modules contribute to the working set of the application and how much working set each module is consuming. Thus, you can very quickly determine how much working set a particular DLL contributes in terms of the DLL's private, shared, and shareable working set. This view unambiguously shows whether a DLL load can be eliminated and how many bytes of private working set can be shaved off the application's working set.
Once a DLL that may not be pay for play is identified (for example, a DLL may be loaded even if it is not used in a particular execution), the next step is to identify why the particular DLL gets loaded and seek to eliminate an unwanted load. Steps for investigating suspicious DLL loads can be found in the CLR and Framework Perf Blog.
The heap data that is shown by the VADump output is for the unmanaged heap—this is memory that will not be managed by the .NET GC. It is important to keep this number small so the GC can manage most of your memory by cleaning up as necessary.
The Other Data category represents calls to a primitive OS memory allocation function (VirtualAlloc) that VADump cannot categorize in any other way. For .NET applications, typically the most important component of Other Data is the garbage-collected heap that holds all user-defined objects.
The .NET Garbage Collector
The .NET runtime supports automatic memory management. It tracks every memory allocation made by the managed program and periodically calls a GC that finds memory that is no longer in use and reuses it for new allocations. An important optimization that the garbage collector performs is that it does not search the whole heap every time, but partitions the heap into three generations (0, 1, and 2).
Generation 0 is the smallest of these, and typically takes only 1/10th of a millisecond to complete but only looks to clean up the allocations that happened after the last GC (and obviously, are not being used). Ideally, the size of a generation is less than the L2 cache size. Generation 1 GCs tackle the allocations that survived one GC; it takes longer to run than Gen 0 GCs, taking about 1 millisecond. Ideally, there should be 10 Gen 0 GCs for every Gen 1 GC.
Gen 2 GCs tackle all objects. Thus, the time taken can be significant. For example, it can take about 160 milliseconds for a 20MB heap, which is a noticeable amount of time. The time grows roughly linearly with the size of the heap (about 8 milliseconds per MB as a very rough estimate). The true cost depends on the amount of memory surviving, the number of GC pointers in surviving memory, and how fragmented the heap is. Ideally, there should be 10 Gen 1 GCs for every Gen 2 GC.
Taken in its entirety, the .NET GC heap looks like a sawtooth with the troughs corresponding to Gen 2 collections, as shown in Figure 3. The typical Gen 2 heap-to-trough ratio is about 1.6, with the ratio being largely independent of heap size (with no fragmentation). In the presence of fragmentation, this number can vary significantly.
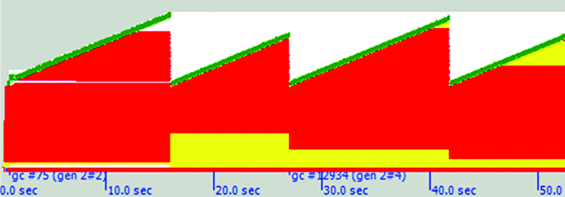
Figure 3 GC Heap Sawtooth Waveform
Perfmon
VADump gives the first level of breakdown of memory usage in the process. However, it does not precisely tell us how much GC memory we are using (the Other Data category can include memory other than the GC heap), and it does not tell whether we have a healthy ratio of GC generations. For that we need to use the Windows PerfMon application. You can start it by typing PerfMon in the run command window which should bring up the window shown in Figure 4. PerfMon is able to gather a wealth of performance data, but here we focus in on its use for monitoring the GC heap.
.gif)
Figure 4 PerfMon Startup Screen
.gif)
Figure 5 Selecting Counters to Monitor in PerfMon
After PerfMon comes up, we need to configure it to display information about the GC. We do this by first clicking on the Performance Monitor item in the tree control in the left pane. This changes the right pane to display performance counter data. Now click the + sign for adding new counters. Next, select the counters you want to monitor as well as the processes you'd like to watch, as shown in Figure 5.
When you select a few counters, you will notice names of all the applications using the runtime. You may select one or two or however many applications you wish to monitor. In addition, there is an instance named All instances which is to enable monitoring data across all instances shown but the data will be displayed separately. In addition, there is a _Global_ instance, which sums up the data from the different instances.
If an application was started after PerfMon was being used to monitor other applications already, one can add more applications by clicking the + sign and adding counters for the new application (only adding the new instance is required; the other instances will continue to display in PerfMon).
Finally, by default the data is shown graphically, but it is more useful to display it numerically. This can be done by clicking on the report-type toolbar (Figure 6). In one test, it showed us that 7.3MB out of the total 8.6MB of private working set was take up by the GC heap and about 11 percent of time was spent in GC. A healthy number for the time in GC is less than 10 percent of total application time, so this particular application would be on the borderline. Finally, it also tells us the number of Gen0, Gen1 and Gen2 collections. Ideally, we want the number of Gen0 collections to be at least 10 times that of Gen1 collections, and the number of Gen1 collections to be at least 10 times that of Gen2 collections.
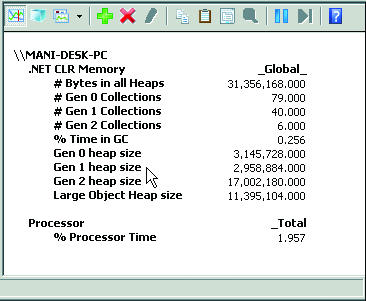
Figure 6 PerfMon Report Display
Conclusion
Memory issues are notoriously difficult to debug. If your application is large enough to care about memory, the key is to limit memory usage in the early stages of development. Understanding how application memory is broken down is the first step in this process; monitoring application memory usage is next. Follow that with identifying opportunities by asking questions about which DLLs contribute the most to memory consumption, why Gen2 GC's are happening so frequently, are your memory allocations pay for play, and so forth. Then optimize memory usage appropriately. If you take away only one lesson, it should be that the time spent early in the development cycle on memory issues pays for itself later, so it really pays to think about memory early!
Send your questions and comments to clrinout@microsoft.com.
Subramanian Ramaswamy is the Program Manager for CLR Performance at Microsoft. He holds a PhD in Electrical and Computer Engineering from the Georgia Institute of Technology.
Vance Morrison is the Partner Architect and the Group Manager for CLR Performance at Microsoft. He drove the design of the .NET Intermediate Language (IL) and he has been involved with .NET since its inception.