May 2009
Volume 24 Number 05
Data Services - Access Your Data On Premise Or In The Cloud With ADO.NET Data Services
By Elisa Flasko | May 2009
This article is based on prerelease versions of Azure and ASP.NET MVC.
This article discusses:
|
This article uses the following technologies: Azure, ASP.NET MVC |
Contents
The Application
Consuming an On-Premises Data Service with the ADO.NET Data Services Client Library
Querying Data
Create, Update, and Delete
Consuming an Azure Table Data Service
The Azure Table Data Model
The ADO.NET Data Services Client Library
Defining the Model on the Client
Creating a Table
Querying Data
Create, Update, and Delete
Summing Up
Web Services has beena hot topic for a number of years now, but what, you may wonder, are these Data Services everyone's talking about lately? As the architecture of Web applications has changed and matured (with the popularity of Rich Internet Applications [RIAs], for example), there has been an increased awareness of the value of exposing raw data, minus any interface or formatting, to any service or application that wants to consume it. Data Services are simple data-centric services with a RESTful interface, that do exactly that—expose pure data for consumption by applications. Such services expose data using a uniform interface to be consumed by Web clients across a corporate intranet or the Internet. Data Services can be built and hosted on your premises using the ADO.NET Data Services Server Library to expose data securely as a service, or may be made available by various hosted services such as Azure Table. Azure is the foundation of the Microsoft Cloud Platform. As the "operating system for the cloud" it provides the essential building blocks you need to write scalable and highly available services. A major part of Azure, Azure Table, allows users to persist data in the cloud and expose the data it stores as a Data Service.
Regardless of where the data service is hosted, the ADO.NET Data Services framework provides a set of Client Libraries built for a range of Microsoft Development platforms (.NET, Silverlight, ASP.NET AJAX, and so on) that allow you to easily consume these services in your applications.
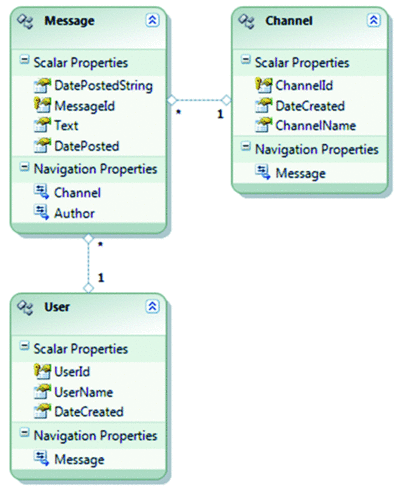
Figure 1 Entity Data Model Exposed by the Micro-Blogging Data Service
The Application
Throughout this article, I will be building a simple Micro-Blogging application using ASP.NET Model View Controller (MVC) (release candidate) and will detail some of the typical scenarios that arise when building such services-based applications. I'll assume a prior understanding of MVC and will therefore not discuss the specifics of this pattern. If you need more information about ASP.NET MVC, see the ASP.NET MVC site. For the purpose of comparison, I will look at two versions of the same basic application—one consuming an on-premises Data Service, and one consuming an Azure Table Data Service. The code for both versions is included in the accompanying code download.
The Micro-Blogging application allows users to post messages to specific channels, create new channels, and view messages on the channels of interest to them. The model that has been exposed by the Data Service for this application consists of three types of entities: Messages, Channels, and Users, with a largely one-to-one mapping to the database. It is worth noting at this point, that with an on-premises data source, this model does contain a first-class notion of relationships between entities. Messages are posted to a particular Channel by an individual User (see Figure 1).
Consuming an On-Premises Data Service with the ADO.NET Data Services Client Library
Let's begin by creating a new ASP.NET MVC Web Application using the Visual Studio template installed with ASP.NET MVC.
There are two primary ways that you could go about defining the classes to represent the model on the client. You could simply define the model by defining the POCO (Plain Old CLR Objects) classes that will be used on the client to represent the entities exposed by the service, which I will do when I develop this application against Azure Table, or you could use the Add Service Reference Wizard in Visual Studio to generate the necessary classes. As when you use Add Service Reference for a Windows Communication Foundation (WCF) service, you simply right-click on the Project and choose Add Service Reference. In the Add Service Reference dialog box, enter the URI for the entry point of the service as the Address, and then click OK. This will generate the associated classes, based on the data service definition, and add them to the project.
As seen in Figure 2, the Add Service Reference Wizard has generated a class for each of my Entities: Channel, Message, and User, as well as a class representing the service as a whole—microblogEntities. The class microblogEntities inherits from DataServiceContext and will be used as the starting point for access to the data service.
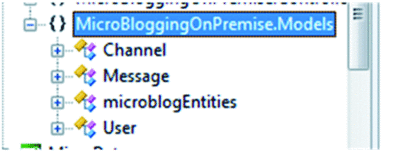
Figure 2 Classes Representing Micro-Blogging Model
Querying Data
With the app now set up to access the data service, I can start developing the remainder of my application. On the homepage, the application will provide a listing of the available Channels and allow the user to view today's messages by selecting a Channel. The user will also be able to filter within that Channel based on Author. To create the homepage, I will need to create an ActionResult in the Home controller that will map to the Index view (the Home controller and Index view are created by default in the MVC template). On the homepage, I will need to retrieve a listing of all available Channels from the data service, as well query the service for today's messages, filtering based on user input (see Figure 3).
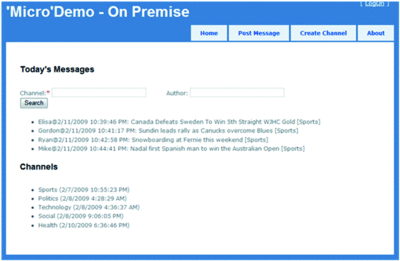
Figure 3 Site HomePage
The ADO.NET Data Service Client Library allows you to easily query data with the use of language integrated query (LINQ), as you see in Figure 4.
The Index action of the homepage controller is called by the MVC application when the homepage is accessed by the browser and returns the data that will be used to render the Index.aspx view. In Figure 4, inside the Index action, I instantiate a new instance of the DataServiceContext microblogEntities, like so:
microblogEntities svc = new microblogEntities(new Uri("https://localhost:50396/MicroData.svc"));
Figure 4 Accessing Data as .NET Objects Using LINQ
public ActionResult Index(string channel, string author) { microblogEntities svc = new microblogEntities(new Uri("https://localhost:50396/MicroData.svc")); ViewData["channels"] = svc.Channels; int y = DateTime.Now.Year; int mm = DateTime.Now.Month; int d = DateTime.Now.Day; var q = from m in svc.Messages.Expand("Author").Expand("Channel") where m.Channel.ChannelName == channel && (m.DatePosted.Year == y && m.DatePosted.Month == mm && m.DatePosted.Day == d) select m; if (!string.IsNullOrEmpty(author)) { q = from m in q where m.Author.UserName == author select m; } ViewData["msg"] = q; return View(); }
This is the object that I will use every time I want to hit the service. The first query that will be executed against the Data Service accesses all of the Channels available. The second, a LINQ query, retrieves all of the Messages in the channel that was requested when the user hit the page and filters by author if a name was provided. Note that in the provided sample code, messages are viewed by entering the Channel Name and, if desired, the Author name into the text box and then clicking View. It is also worth noting that the queries require a ChannelName; and a search cannot be executed by author name alone. I place both of the aforementioned queries into ViewData to be executed as the page is rendered and then return.
Now, in the view for the homepage, Index.aspx, I will actually enumerate over the queries, effectively executing the query against the store at this point, and will then print the results to the page (see Figure 5).
Figure 5 Homepage View (On-Premises Service)
<h2>Today's Messages</h2> <form action="./"> Channel:<span style="color: #FF0000">*</span> <input type="text" name="channel" /> Author: <input type="text" name="author" /><br /> <input type="submit" value="Search" /> </form> <ul> <!-- Execute query placed in ViewData["msg"] - enumerates over results and prints resulting message data to the screen --> <% foreach (var m in (Ienumerable <MicroBloggingOnPremise.Models.Message>) ViewData["msg"]) { %> <li><%=m.Author.UserName%>@<%=m.DatePosted %>: <%=m.Text%> [<%=m.Channel.ChannelName %>]</li> <%} %> </ul> <h2>Channels</h2> <ul> <!-- Execute query placed in ViewData["channels"] - enumerates over results and prints resulting channel data to the screen --> <% foreach (var channel in (IEnumerable<MicroBloggingOnPremise.Models.Channel>) ViewData["channels"]) { %> <li><%=channel.ChannelName %> (<%=channel.DateCreated %>)</li> <% } %> </ul>
Create, Update, and Delete
To create a new entity instance in the data service using the ADO.NET Data Service Client Library, I create a new instance of the .NET object that represents the entity set and call the AddTo… method for the Entity Set on the DataServiceContext instance that I'm using, passing the new object and the entity set that I am adding it to.
For example, let's look at the PostMessage action of the homepage controller, in Figure 6, which is called when I attempt to post a message by clicking the Send button.
Figure 6 (On-Premises) Create a New Message and Push to Data Store
[AcceptVerbs("POST")] public ActionResult PostMessage(string channel, string author, string msg) { microblogEntities svc = new microblogEntities(new Uri("https://localhost:50396/MicroData.svc")); Channel chan = (from c in svc.Channels where c.ChannelName == channel select c).FirstOrDefault(); if (chan == null) throw new ArgumentException("Invalid channel"); User u = (from auth in svc.Users where auth.UserName == author select auth).FirstOrDefault(); if (u == null) //throw new ArgumentException("Invalid Author"); { //To simplify this example we will create a new user, //if the user was null when we queried. //It is possible that another client creates //the same UserName //before we call SaveChanges() //and we end up with 2 Users with the same name var user = new User(); user.UserName = author; user.DateCreated = DateTime.UtcNow; svc.AddToUsers(user); u = user; } var m = new Message(); m.DatePosted = DateTime.UtcNow; m.Text = msg; svc.AddToMessages(m); svc.SetLink(m, "Channel", chan); svc.SetLink(m, "Author", u); try { svc.SaveChanges(); } catch (Exception e) { throw (e); } return this.RedirectToAction("Index"); }
Notice that the method is decorated with the AcceptVerbs("POST") attribute, since we're using it for a form post. Again I start by instantiating a new DataServiceContext as the entry point to my service and then I query for the specified channel to check that it exists. If the channel does not exist, I throw an exception; otherwise, I create a new Message passing in the data entered by the user. Once the Message has been created, I need to tell the context that I have a new object to be added by calling svc.AddToMessages(m); passing in the new Message object, m. I also set links representing the relationships attached to this new message, in this case svc.SetLink(m, "Channel", chan); associating the message with the specified Channel and svc.SetLink(m, "Author", u); associating the message with the specified Author. Finally, I want to push the changes to the service and into the database by calling svc.SaveChanges();.
If I were modifying an existing instance rather than creating a new one, I would first query for the object that I want to update, make the desired changes, and rather than AddToMessages, I would call the UpdateObject method to indicate to the context that it needs to send an update for that object the next time I call SaveChanges(). Similarly, if I were deleting an instance, once I had the object, I would call the Delete method to indicate to the context that I want to delete that object.
In this example, and so far in this article, you have seen a single operation on the client map to a single HTTP request being sent to the service. In many scenarios, it is also beneficial for the client to be able to batch a group of operations and send them to the service in a single HTTP request. This reduces the number of round trips to the service and enables a logical scope of atomicity for sets of operations. The ADO.NET Data Service Client Library supports sending a group of Insert, Update, and/or Delete operations to a service in a single HTTP request via a call to the SaveChanges() method, passing SaveChangesOptions.Batch as the only parameter. This parameter value instructs the client to batch all pending changes into a single HTTP request sent to the service. By sending changes as a batch, you ensure that either all the changes will complete successfully or none of the changes will be applied.
Consuming an Azure Table Data Service
When you are developing a .NET application using Azure Table, the data is accessed using the ADO.NET Data Services client libraries. In this section, I will walk through the development of the same simple application used above, but this time I will be accessing and manipulating data stored in Azure Table. For the remainder of this article, I assume that a Azure Storage account has already been set up and is available for your use. For more information on getting started with Azure Table, see the Azure Services Platform Developer Center.
The Azure Table Data Model
Before getting started on an application, there are a couple things that you must know about the Azure Table Data Model for best performance. An application may choose to create many tables within a storage account where each table contains a set of Entities (rows) and each Entity contains a set of Properties (columns). Each Entity is able to have up to 255 properties, stored as <Name, TypedValue> pairs and is identified using two key properties that together become the unique ID. This first key property is the PartitionKey (type string), enabling partitioning for scalability, and the other is the RowKey (also type string), uniquely identifying the entity within the partition. Beyond the two key properties, there is no fixed schema for the remaining properties, meaning that the application is responsible for enforcing any schema that must be maintained.
One of the important differences when developing against Azure Table compared to local database storage surrounds partitioning. With Azure Table, the application controls the granularity of partitions, and partitioning becomes very important to both the performance and scalability of the application. This means that the choice of the PartitionKey property is very important, and impacts performance because the table clusters entities (Entity Locality) with the same partition key value. To choose the best PartitionKey possible, you should choose the key such that it is common to the majority (or all) of the queries used in the application. Performance and scalability can also be impacted similarly by the number of partitions used by the application (number of different values in the PartitionKey); having more partitions allows the server to better balance the load across nodes.
The ADO.NET Data Services Client Library
Now I will build the same Micro-Blogging application, using ASP.NET Mode View Controller (MVC), and this time I will detail some of the questions that typically arise when building applications against data stored in Azure Table.
Similar to my on-premises database, this will require three Entities in my model, which I will translate into three Tables: a Messages table, a Channels table, and a Users table, all set up in my storage account.
Throughout the application I will make use of the StorageClient sample that ships within the Microsoft Azure SDK. The StorageClient sample implements a library you can use to access the Azure blob storage service, queue service, and the table storage service. I will use the library to help me access the table storage service. The Microsoft Azure SDK can be downloaded from the Azure Services Platform Developer Center cited earlier.
To begin, I will create a new ASP.NET MVC Web Application using the Visual Studio template installed with ASP.NET MVC, and add the StorageClient project from the Microsoft Azure SDK to the solution.
Defining the Model on the Client
The first step in building the application is to define the classes that will be used on the client to represent the entities exposed by the service. Since Azure Table does not have a fixed schema, I cannot use the Add Service Reference Wizard as I did with the on-premises service. However, as I mentioned above, I can create my own POCO classes. These classes will effectively be used to define the schema for the application, as Azure Table does not enforce any schema on the server side. I will define a Message class, a Channel class, and a User class to align with the EntityTypes exposed by the service. To begin, I add a new code file, MicroData.cs, to the Models folder where I will define my classes. These classes will be defined in the MicroBloggingAzure.Models namespace.
If you take a look at the Messages class shown in Figure 7, you can see that I have defined both a PartitionKey and a RowKey, as required by Azure Table. This is a departure from what you saw in the on-premises service because they are specific to Azure Table. It is worth noting that the best practices for key determination are not recommended across Relational and Cloud storage, and in my sample applications I have used the most appropriate key determination for each data source rather than trying to align the two in any way. The PartitionKey and RowKey are simply defined as type string and identified using naming conventions (that is, calling them PartitionKey and RowKey). In the case of this application, the PartitionKey is made up of the name of the Channel to which the message is posted, concatenated with an "@" and the date the message was posted in the format "yyyy-mm-dd". The RowKey is a string representation of the date that the message was posted. This PartitionKey was chosen such that the application can efficiently retrieve messages that were recently posted to a particular channel. To begin with, I have chosen to show only today's posts when a channel is accessed; however, if my application becomes very popular and receives thousands of posts a day, this key can be easily modified to partition more granularly— for example, by adding in a time component (hour perhaps). Similarly, if my application is not as busy as anticipated, I could modify the PartitionKey to partition by month rather than by day. I have then identified the two key properties as a uniquely identifying DataServiceKey, which is done by adding the DataServiceKey attribute to the class. The Messages class also defines a number of other properties containing information about the message, a part of the required keys. All of the properties associated with the Message entity will be stored in Azure Table. The User and Channel classes are created following the same principles as the Message class.
Figure 7 Message Entity Definition
[DataServiceKey("PartitionKey", "RowKey")] public class Message { // ParitionKey is channel name [+ day] public string PartitionKey { get; set; } // Date/Time when the message was created public string RowKey { get; set; } public string Text { get; set; } public string Author { get; set; } public string Channel { get; set; } public DateTime DatePosted { get; set; } public int Rating { get; set; } public Message() { } public Message(string channel, string author, string text) { this.Text = text; this.Author = author; this.Channel = channel; this.DatePosted = DateTime.UtcNow; this.PartitionKey = MakeKey(this.Channel, this.DatePosted); this.RowKey = System.Xml.XmlConvert.ToString( this.DatePosted); } public static string MakeKey(string channel, DateTime dt) { return channel + "@" + dt.ToString("yyyy-MM-dd"); } }
Creating a Table
Once my entity classes have been defined, I can begin really developing the application. But first, I need to add my Azure Table Account access information to Web.config, as seen here:
<appSettings> <add key="TableStorageEndpoint" value="https://table.core.windows.net/"/> <add key="AccountName" value="<MyAccountName>"/> <add key="AccountSharedKey" value="<MyAccountSharedKey-Provided when you register for Azure Tables>"/> </appSettings>
Although this is not the only way of passing account information when developing against Azure Table, this will allow me to use the Azure SDK to automatically pick up my account settings and deal with connections to the data source.
Often in applications written against Azure Table, the creation of tables required by the app is done programmatically within the application. This is a little different from how one would normally do things with an on-premises data store, where the tables are created separately in the database and the application simply interacts with them.
One way of creating the required tables programmatically would be to simply create a new Entity in the master table called Tables. Every table that you create in your storage account must be represented as an entity in the master table, which is predefined when you register your account. For this application, however, I will use the StorageClient, which provides functionality to check, upon application initialization, that the required Tables exist in the storage account, and if they do not exist, will create them.
By creating the tables programmatically within the application, I simplify the process by which I can reflect updates to the model in the data store. For example, if down the road I add the ability for a user to subscribe to a channel, and add a subscription entity to the model, the associated table will automatically be added to the data store the next time the application starts. This choice also ensures that if the app is distributed for use with different Azure Tables accounts, all the user needs to do is to enter his or her account access information and the tables are correctly set up and ready for use when the application is run.
If you have existing data already in Azure Table, or if you do not have control over the tables in Azure, you may skip the step of creating tables altogether and simply program against your existing tables.
To check and create the tables in my application, I will use the TableStorage.CreateTablesFromModel() method that is a part of the StorageClient library, as seen here:
protected void Application_Start() { RegisterRoutes(RouteTable.Routes); //MVC Routing Rules TableStorage.CreateTablesFromModel (typeof(Models.MicroData)); }
Querying Data
With my app set up to access my account in Azure Tables, the remainder of it works just as if I were accessing an on-premises service. Just as with my on-premises service, since I'm using the ADO.NET Data Service Client Library, I am able to easily work with my data as .NET objects and to query it using LINQ (see Figure 8).
Figure 8 Accessing Data as .NET Objects Using LINQ Again
public ActionResult Index(string channel, string author) { var svc = new Models.MicroData(); ViewData["channels"] = svc.Channels; var q = from m in svc.Messages where m.PartitionKey == Models.Message. MakeKey(channel, DateTime.UtcNow) select m; if (!string.IsNullOrEmpty(author)) { q = from m in q where m.Author == author select m; } ViewData["msg"] = q; return View(); }
In Figure 8, you see the Index action of the homepage controller. Inside this action, I instantiate a new instance of my DataServiceContext (MicroData inherits from TableStorageDataServiceContext), the object I use to access the service, and write the queries to be executed against the Data Service. I then retrieve a listing of all available Channels from the data service and write the LINQ query to retrieve all of Today's Messages, filtering based on user input (Channel and possibly Author if provided). I place both queries into ViewData to be executed as the page is rendered and then return. Notice that the pattern here is the same as when I accessed the on-premises data source; I instantiate a new DataServiceContext instance and query using simple LINQ queries against my model.
In the view for my homepage (Index.aspx in Figure 9), I enumerate over my queries, executing the queries against the store, and print the results to the page.
Figure 9 Homepage View
<h2>Today's Messages</h2> <form action="./"> Channel:<span style="color: #FF0000">*</span> <input type="text" name="channel" /><br /> Author: <input type="text" name="author" /><br /> <input type="submit" value="View" /> </form> <ul> <!-- Execute query placed in ViewData["msg"] - enumerates over results and prints resulting message data to the screen --> <% foreach (var m in (IEnumerable<MicroBloggingAzure.Models.Message>) ViewData["msg"]) { %> <li><%=m.Author%>@<%=m.DatePosted %>: <%=m.Text%> [<%=m.Channel %>] </li> <%} %> </ul> <h2>Channels</h2> <ul> <!-- Execute query placed in ViewData["channels"] - enumerates over Results and prints resulting channel data to the screen --> <% foreach (var channel in (IEnumerable<MicroBloggingAzure.Models.Channel>) ViewData["channels"]) { %> <li><%=channel.PartitionKey %> (<%=channel.DateCreated %>)</li> <% } %> </ul>
Create, Update, and Delete
Creating a new entity in the table service using the ADO.NET Data Service Client Library, just as if I were working against an on-premises store, is done by creating a new instance of the .NET object that represents the entity set and calling AddObject().
Let's look at the PostMessage action of my homepage controller, in Figure 10.
Figure 10 Create New Message and Push to Data Store
[AcceptVerbs("POST")] public ActionResult PostMessage(string channel, string author, string msg) { var svc = new Models.MicroData(); var q = from c in svc.Channels where c.PartitionKey == channel select c; if (q.FirstOrDefault() == null) throw new ArgumentException("Invalid channel"); User u = (from auth in svc.Users where auth.UserName == author select auth).FirstOrDefault(); if (u == null) //throw new ArgumentException("Invalid Author"); { var user = new User(); user.UserName = author; user.DateCreated = DateTime.UtcNow; user.PartitionKey = user.UserName; user.RowKey = string.Empty; svc.AddObject("Users", user); u = user; } var m = new Models.Message(channel, author, msg); svc.AddObject("Messages", m); svc.SaveChanges(); return this.RedirectToAction("Index"); }
Just as I did to query the data service, I instantiate a new DataServiceContext as the entry point and query for the specified channel to check that it exists, throwing an exception if it is not found. I create a new Message, passing in the user input. Once the Message has been created, I tell the context that I have a new object to be added by calling svc.AddObject("Messages", m); passing in the EntitySet name that I am adding to, "Messages", and new Message object, m. Finally, I want to push the changes into the Table service by calling svc.SaveChanges();.
There are a couple of differences that you may notice here. The first is due to the lack of a fixed schema in Azure Table. This lack of schema means that I do not have strongly typed data and must call the untyped AddObject() on the DataServiceContext instance, passing the new object and the entity set that I am adding it to, rather than the typed AddTo…() methods that I used against my on-premises store. It is worth noting here that the more generic AddObject() method is still available in the on-premises scenario; however, in my example I use the strongly typed methods to take advantage of compile-time checking and so forth.
The second difference, also somewhat attributed to the lack of fixed schema, is the lack of a first-class relationship concept. You first notice this in the differences between how I structure the data in Azure Table compared to my on-premises data source. In the PostMessage action you'll notice that I am not setting links on my new object; rather, any relationship information is stored directly as properties in my Entities.
If I were modifying an existing instance rather than creating a new one, I would first query for the object that I want to update, make the desired changes and, finally, rather than AddObject, I would call the UpdateObject method to indicate to the context that it needs to send an update for that object the next time I call SaveChanges(), just as I would with an on-premises data service. Similarly, deleting an instance by calling the Delete method to indicate to the context that I want to delete that object, is also the same whether I am accessing an Azure Table service or my own on-premises service.
Summing Up
Looking at these two examples together, you can see how simple the move between developing against an on-premise service and an Azure Table service is made by the use of the same simple ADO.NET Data Services Client Library. The learning curve involved is rather flat if you are also responsible for managing each data source and mostly consists of a shift in thinking between the relational storage model and the more unstructured Azure Table model, as well as an awareness of the Azure Table PartitionKey and RowKey model. If you are focused primarily on the application development against these services, the skills you build up developing against one service are transferable to development against any other data service.
Elisa Flasko is a Program Manager in the Data Programmability team at Microsoft, including the ADO.NET technologies, XML technologies, and SQL Server Connectivity technologies. She can be reached at blogs.msdn.com/elisaj.