May 2009
Volume 24 Number 05
Patterns and Practices - You Can Depend On Patterns and Practices
By Alex Homer | May 2009
Contents
Patterns and Practices
A Guiding Hand
Coping with Abstraction
A Brief History of Dependency at Microsoft
Applying Dependency Inversion
Extending Yourself
Summary
Writing computer code used to be extremely difficult. When I began programming home computers more years ago than I care to remember, the only way to make a program run at more than a desultory crawl was to write it using machine code. Even a simple word processing utility could take several weeks to create as you meticulously planned the memory allocations for variables, wrote routines to perform simple tasks such as drawing characters on the screen and decoding keyboard input, and then typed every individual processor instruction into an assembler.
Today, by comparison, creating powerful code is easy. We take for granted the wealth of tools, high-level languages, runtime frameworks, code libraries, and operating system services that make it possible to build applications quickly and efficiently. However, while creating the code has become much easier, the task of creating applications has not. We expect much more from our modern applications than ever before. They must communicate over networks, interact with other applications and services, expose highly interactive and responsive user interfaces, and support rich media and graphics. And, of course, they must be robust, secure, reliable, and manageable.
In fact, it would be almost impossible to meet the requirements demanded of our modern applications without the continuing growth and evolution of programming languages, operating systems, platform services, and frameworks. The huge increase in complexity of these applications has also forced us to discover ways to simplify and organize the code. Over the years, a number of tried and tested programming and design techniques have evolved, such as componentization, object-orientation, and—more recently—service orientation.
Patterns and Practices
While improvements in tools and frameworks make it easier to write code more quickly, and modern languages and programming styles make it easier to write better code, the one area that has had the most impact on our ability to create applications over the last 10 to 15 years has been the evolution and increasing acceptance of software design patterns.
Design patterns describe common issues that occur repeatedly in application design and development and provide techniques for handling these issues. Patterns also describe the current industry practice for resolving architectural issues and for handling the design complexity demanded of applications. The arrangement of code and solution elements is at the heart of software design today, and patterns provide us with ways to simplify and organize these elements—providing the best opportunity to maximize performance, flexibility, and maintainability for applications.
Since the release of the ground-breaking book by the Gang of Four, Erich Gamma, Richard Helm, Ralph Johnson, and John M. Vlissides, Design Patterns: Elements of Reusable Object-Oriented Software (Addison-Wesley, 1996), which documented many of the basic design patterns we take for granted today, the number of design patterns available to developers and designers has grown at a phenomenal rate. Almost every aspect of the creation of software has associated design and implementation patterns, and simply documenting them all has become an impossible task. Instead, designers and developers tend to fragment into specialties and learn the patterns most applicable to their own area of expertise.
A Guiding Hand
In 2002, the patterns & practices group at Microsoft Corporation published the Application Architecture for .NET: Designing Applications and Services guide, bringing together the basic design guidance and specialist advice to help architects build applications on the Microsoft .NET Framework. However, technologies change over time, and while the fundamentals of design and development described in the guide are equally valid today, the original guide did not cover some of the new capabilities of the .NET Framework or address the design issues arising for new types of applications.
For the last several months, a broad team of industry specialists and subject matter experts, both within and outside of Microsoft, has been collaborating to create a new edition of the guide that provides a comprehensive introduction to architecting and designing solutions on the Microsoft .NET Framework. The Microsoft Application Architecture Guide (2nd Edition) describes high-level architectural principles and patterns and current thinking on accepted design and development practices. It also includes guidance on applying these factors to specific types of applications, and it provides a broad overview of the many platform services and code libraries available to make implementation easier.
Of course, to borrow an often-used phrase, software and system architecture is something that embraces the question of life, the universe, and everything. No single publication can answer every possible question or hope to provide completely comprehensive coverage of every possible scenario. However, the new guide aims to provide the information you need whether you are just starting out designing.NET Framework-based applications, an experienced designer moving to the .NET Framework from another platform, an accomplished architect looking for specific information and advice, or simply interested in learning more about the broad scenarios and opportunities offered by the .NET Framework.
Coping with Abstraction
To illustrate industry practices, the guide lists general principles that you should apply when designing almost any type of application. These principles include maintaining separation of concerns, using abstraction to implement loose coupling between layers and components, implementing service location capabilities, and managing crosscutting concerns such as logging and security. While these may seem to be desirable but unrelated aims, one technique can help you to apply several design principles easily. The Dependency Inversion principle implies separation of concerns through abstractions rather than concrete implementations. In terms of design patterns, you can achieve this by applying the Inversion of Control (IoC) pattern and its related pattern, Dependency Injection (DI).
The theory is simple enough. Instead of specifying at design time the actual concrete type that each class or component will use to perform some activity or process, you arrange for these classes or components to retrieve the appropriate object from a container that you previously configured with type maps and registered types. For example, as illustrated in the simple application in Figure 1, your data access component may require the services of a logging component. As you have correctly abstracted your crosscutting code from the task-specific and application-specific code, you may have several logging components from which to choose. Perhaps one is designed for use when debugging the application, another for use when running the application internally on your own network, and a third most suited to running in an enterprise-level system that makes use of a monitoring environment, such as Microsoft System Center.
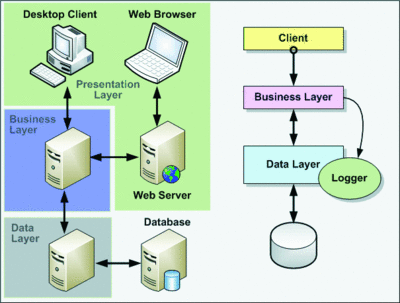
Figure 1 A Simple Application That Makes Use of Layering and a Separate Logging Component
It could even be the case that you have multiple data access components, each designed for use in a specific environment or with a different type of data store. Therefore, your business layer will need to choose the appropriate data layer component depending on the current deployment or runtime environment. In a similar way, you may have services that your application uses repeatedly, such as an e-mail message sending service or a data transformation service. Dependency injection can act as a service location facility to help your application retrieve an instance (either a new instance or an existing instance) of the service at run time.
Each of these examples effectively describes a dependency of one part of the application on another, and resolving these dependencies in a way that does not tightly couple the objects is the aim of the Dependency Inversion principle.
A Brief History of Dependency at Microsoft
Although the principles of Dependency Inversion have been around for a long time, features to help developers implement it in applications running on the Microsoft platform are relatively recent. In fact, there is a story that a renowned developer in the Java world, when visiting the Microsoft campus, remarked that the general belief was that nobody at Microsoft could spell "Dependency Injection." While that is, without doubt, an urban myth, it is the case that tools to help developers implement many of the common patterns have not been a priority in most areas of the company.
However, the patterns & practices group at Microsoft stands out through our unique position of being inside the company but outside of the main product development teams and divisions. The goal of p&p, as illustrated by our tagline "proven practices for predictable results," is to provide developers with guidance, tools, libraries, frameworks, and a myriad of other facilities to help them design and build better applications on the Microsoft platform. A quick glance at our home page on MSDNwill illustrate the broad range of assets we provide.
Among these assets are several products that make use of the Dependency Injection pattern, including Enterprise Library, composite application frameworks, and software factories. During development of these assets, in particular the original Composite Application Block (CAB), it became clear that a reusable and highly configurable dependency injection mechanism was required—and so the team built the original version of Object Builder.
Object Builder is almost completely configurable and is now used in a wide range of products throughout p&p and elsewhere within Microsoft. However, it is quite difficult to use. It requires a great many parameters that take complex objects, and it exposes a range of events that you must handle to apply the configuration you require. Initial attempts to document Object Builder as part of the CAB project soon revealed that this was going to be an uphill task. In addition, Object Builder was rather more than a dependency injection container, and it seemed overkill in terms of the common requirements for implementing the DI and IoC patterns.
During the development of Enterprise Library 4.0, Object Builder was updated—not to simplify it, but to make it faster and more efficient. It was also fine-tuned for use in the first major dependency injection mechanism from Microsoft that is aimed squarely at developers who want to implement the DI and IoC patterns. Object Builder is the foundation for Unity, a lightweight, extensible dependency injection container that supports constructor injection, property injection, and method call injection.
Unity provides capabilities for simplified object creation, especially for hierarchical object structures and dependencies; abstraction of requirements at run time or through configuration; simplified management of crosscutting concerns; and increased flexibility by deferring component configuration to the container. It has a service location capability, and allows clients to store or cache the container—even in ASP.NET Web applications.
Since the release of the first version Unity in early 2008, it has found a home in many p&p assets as the default mechanism for implementing Dependency Inversion. Unity has also continued to evolve while remaining backward compatible; you can use it to enable features within Enterprise Library, as well as use it as a stand-alone DI container. In the most recent release, it offers facilities to implement instance and type interception (through a plug-in extension) that allow implementations of Aspect Oriented Programming techniques such as policy injection.
Unity has also spawned other DI container implementations aimed at specific tasks and requirements, such as an extremely lightweight implementation designed for use in mobile devices and smart phones. Meanwhile, planned future developments in the Unity and Enterprise Library arena include features to open up Enterprise Library to other third party container mechanisms, while providing additional extensions that enable new capabilities for Unity.
Applying Dependency Inversion
Leaving this historical distraction and returning to the hypothetical application, how can you apply the Dependency Inversion principle to achieve the aims, discussed earlier, of separation of concerns, abstraction, and loose coupling? The answer is to configure a dependency injection container, such as Unity, with the appropriate types and type mappings and allow the application to retrieve and inject instances of the appropriate objects at run time. Figure 2illustrates how you can use the Unity application block to implement this container. In this case, you populate the container with type mappings between interface definitions for the data components and logging components, and the specific concrete implementations of these interfaces that you want the application to use.
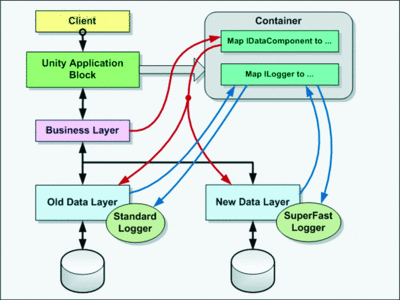
Figure 2 Dependency injection can select the appropriate components at run time based on configuration of the container.
At run time, the business layer will query the container to retrieve an instance of the correct data layer component, depending on its current mapping. The data layer will then query the container to obtain an instance of the appropriate logging component, depending on the mapping stored for that interface type. As an alternative, the data and logging components may inherit from respective base classes, and registrations in the container can map between these base types and the inheriting concrete types.
This container-driven approach to resolving types and instances means that the developer is free to change the implementations for the data and logging components, as long as these implementations provide the required functionality and expose the appropriate interface (for example, by implementing the mapped interface or inheriting from the mapped base class). The container configuration may be set in code at run time using methods of the container that register types, type mappings, or existing instances of objects. Alternatively, you can populate the container by loading the registrations from a configuration source or a file, such as the web.config or app.config file.
When you want to register more than one instance of a type, you can use a name to define each one and then resolve the different types by specifying the name. The registration can also specify the lifetime of the object, making it easy to achieve service location-style capabilities by registering the service object as a singleton or with a specific lifetime, such as per-thread. The following code example shows some examples of registering type mappings with the container:
C# // Register a mapping for the CustomerService class to the IMyService interface. myContainer.RegisterType<IMyService, CustomerService>(); // Register the same mapping using a mapping name. myContainer.RegisterType<IMyService, CustomerService>("Data"); // Register the first mapping, but as a singleton. myContainer.RegisterType<IMyService, CustomerService>( new ContainerControlledLifetimeManager());
Note: The code examples reference classes and types using just the class name. You can use type alias definitions within the configuration file to alias the fully qualified type names of classes, which simplifies container registration when you're using a configuration file.
To retrieve instance of an object, you simply query the container by specifying the type, the interface type, or the base class type (and the name, if you registered the type using a name), as shown in the next example. The container resolves the type, if it is registered, and creates or returns an instance of the appropriate object. If it is not registered, the container simply creates a new instance of that type and hands it back. Why would you resolve items through the container when there is no registration for that type? The idea is to take advantage of the additional and very useful features that Unity, and many other DI container mechanisms, provides—the ability to inject objects using constructor, property setter, and method call injection.
C# // Retrieve an instance of the mapped IMyService concrete class. IMyService result = myContainer.Resolve<IMyService>(); // Retrieve an instance by specifying the mapping name. IMyService result = myContainer.Resolve<IMyService>("Data");
For example, when you create an instance of an object through the container, Unity examines the constructors and will automatically inject instances of the appropriate type into the constructor parameters. Going back to our earlier simple application example, the data access component may have a constructor that takes a reference to a logging component as a parameter. If this parameter type is the interface or base class for logging components registered with the container, Unity will resolve the mapped type, create an instance, and pass it to the constructor of the data component (as shown in Figure 3). You do nothing except register the mappings.
Figure 3 Injecting Objects into Constructor Parameters
C# // In main or startup code: // Register a mapping for a logging component to the ILogger interface. // Alternatively, you can specify this mapping in a configuration file. myContainer.RegisterType<ILogger, MyLogger>(); ... // In data access component: // Variable to hold reference to logger. private ILogger _logger = null; // Class constructor. Unity will populate the ILogger type parameter. public DataAccessRoutines(ILogger myLogger) { // store reference to logger _logger = myLogger; _logger.WriteToLog("Instantiated DataAccessRoutines component"); }
This means that you can change the actual concrete type that the application uses simply by changing the configuration of the container—either at design time, at run time by editing the configuration, or dynamically based on some value that your code gathers from the environment and uses to create or update the mapping in the container. You can plug in your debug logging component when required, or plug in a new "super fast" logging component when you find that the old one is too slow. Meanwhile, the system administrator can update the configuration as required to monitor, manage, and adapt the application behavior at run time to suit changing environments and operational issues.
Likewise, if you have a dependency between two objects, such as the dependency of a view on its presenter when you implement the Model-View-Presenter (MVP) pattern, you can use dependency injection to loosen the coupling between these classes. Simply define a property of the view class as the presenter type or base class type, and mark the property with a Dependency attribute, as shown in the next example:
C# // Variable to hold reference to controller. private IPresenter _presenter; // Property that exposes the presenter in the view class. Unity will inject // this automatically because it carries the Dependency attribute. [Dependency] public IPresenter MyViewPresenter { get { return _presenter; } set { _presenter = value; } }
Note: Attributes are the quickest way to specify properties to inject. If you do not want to use attributes (to avoid coupling your classes to the container) you can instead use a configuration file or the Unity API to specify which properties should be injected.
When you create the view by resolving it through the container, Unity will detect the Dependency attribute, automatically resolve an instance of the appropriate concrete presenter class, and set it as the value of that property of the view class. The Quick Start example included with Unity demonstrates this approach in a Windows Forms application. It actually resolves the main Form for the application through the container, which causes Unity to create and populate several dependencies throughout the entire application, using both constructor and property setter injection.
Extending Yourself
Unity provides a wealth of DI-related functionality, but there is always something extra you want to achieve. The challenge with Unity was to keep it generic enough to satisfy the maximum number of requirements, while being extensible so that you can adapt it to your own specific requirements. This is achieved by using container extensions, which allow you to do almost anything in terms of managing object creation and retrieval.
As an example, the Quick Starts included with Unity demonstrate a container extension that implements a simple attribute-driven Publish\Subscribe mechanism. As Unity creates instances of objects, it wires up event handlers for them based on attributes in the class files. Another example generates detailed logging information as it creates or retrieves each type through the container, which helps when you're debugging complex applications.
This huge flexibility comes about because Unity allows you to interact with the underlying Object Builder mechanism through your container extension. Ah, you may say, but Object Builder is extremely difficult to use and is not fully documented. In fact, the Unity documentation does contain information about Object Builder in terms of how you interact with it from a container extension, and the Quick Start examples provide plenty of sample code you can use and modify.
Summary
There are many views on application architecture and design. The ISO/IEC standard 42010:2007/IEEE 1471 "Recommended Practice for Architecture Description of Software-Intensive Systems" describes software architecture as "the fundamental organization of a system embodied in its components, their relationships to each other and to the environment, and the principles guiding its design and evolution". However, in his book Patterns of Enterprise Application Architecture (Addison-Wesley, 2002), Martin Fowler says that "...in the end, architecture boils down to whatever the important stuff is," which is a much simpler way to capture the spirit of software architecture!
The Microsoft Application Architecture Guide (2nd Edition) will help you understand what the important stuff is so that you can build better, higher quality applications more quickly and more efficiently. As you have seen in this article, one specific area—taking advantage of the Dependency Injection and Inversion of Control patterns—can help you achieve many of the design goals promoted by the guide. This includes separation of concerns, the use of abstraction to implement loose coupling between layers, service location, and implementation of features for improved management of crosscutting concerns.
Alex Homer is a documentation engineer working with the Microsoft patterns & practices team. His random ravings about life, technology, and the world in general can be found at https://blogs.msdn.com/alexhomer/.