Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article gives an introduction on Microsoft Cosmos DB, features available in them and options to integrate with application.
Introduction:
CosmosDB is the next Generation of Azure DB,its a enhanced version of document db.
Document DB customers, with their data, are automatically Azure Cosmos DB customers.
The transition is seamless and we now have access to all capabilities offered by Azure Cosmos DB.
Cosmos DB is a planet scale database.It is a good choice for any server less application that needs low order-of-millisecond response times, and needs to scale rapidly and globally. They are more transparent to our application and the config does not need to change.
How It was derived:
Microsoft Cosmos DB isn’t entirely new: It grew out of a Microsoft development initiative called Project Florence that began in 2010. Project Florence is a speculative glimpse into our Future where both our Natural and Digital worlds could co-exist in harmony through enhanced communication.
https://exchangequery.files.wordpress.com/2018/04/picture1.png?w=600
{kind=link}
- It was first commercialized in 2015 with the release of a NoSQL database called Azure DocumentDB
- Cosmos DB was introduced in 2017.
- Cosmos DB expands on it by adding multi-model support, global distribution capabilities and relational-like guarantees for latency, throughput, consistency and availability.
Why Cosmos DB?
- It has no Data Scheme and schema-free. indexes all the data without requiring us to deal with schema and index management.
- It’s also multi-model, natively supporting document, key-value, graph, and column-family data models.
- Industry first Globally distributed, horizontally scalable, multi-model database service. Azure Cosmos DB guarantees single-digit-millisecond latencies at the 99th percentile anywhere in the world, offers multiple well-defined consistency models to fine-tune performance, and guarantees high availability.
- No need to worry about instances, servers, CPU , Memory. Just select the throughput , required storage and create collections. CosmosDB works based only on throughputs. It has integrations with Azure functions. Serverless event driven solution.
- API’s and Access Methods- Document DB API,Graph API (Gremlin),MongoDB API,RESTful HTTP API & Table API. This gives more flexibility to the developer.
- They are elastic Globally scalable and with HA , Automatically indexes all our data.
- 5 Consistency concepts – Bounded Staleness, Consistent Prefix,Session Consistency,Eventual Consistency,Immediate Consistency. Application owner has now more options to choose between consistency and performance.
Summary on Cosmos DB:
https://exchangequery.files.wordpress.com/2018/04/picture2.png?w=600
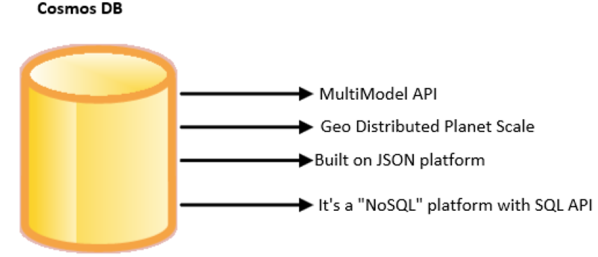{kind=link}
Example without Cosmos DB:
- Data Geo replication might be a challenge for the developer.
- Users from remote locations might experience latency and inconsistency in their data’s.
- Providing an automatic failover is a real challenge.
https://exchangequery.files.wordpress.com/2018/04/picture3.png?w=600
{kind=link}
Example with Cosmos DB:
- Data Can be Geo-Distributed in few Clicks.
- Developer do not need to worry about the data replication.
- Strong consistency can be given to the end users across geo-distributed location.
- Web-Tier application can be changed anytime between primary and secondary in few clicks.
- Failover can be initiated any time manually and automatic failover is present.
https://exchangequery.files.wordpress.com/2018/04/picture5.png?w=600
{kind=link}
Data Replication Methods:
- Replicate Data with a single click – we can add/remove them by a single click.
- Failover can be customized any time in few clicks(automatic/manual).
- Application does not need to change.
- Easily move web tier and it will automatically find the nearest DB.
- Write/Read Regions can be modified any time.
- New Regions can be added/removed any time.
- Can be accessed with different API’s.
Existing data can be migrated:
- For Example if we already have a mongo app we can just import and move them over.
- Just copy the mongo data into the cosmos and replacing the URL in the code.
- We can use Data migration Tool for the migration.
5 Consistency Types:
There are 5 consistency types where the developer can choose according to the requirement.
- Synchronous – eventual consistent End users get the best performance.(but data will not be consistent)
- Strong – will only commit the database to the write/read regions after the copy is successful.(consistent data across all regions)
- Bounded – Option to set Bounded staleness to 2 hour. If it is set to 0 then it becomes strong consistency.(We can select few interval up to which the consistency can be strong till the replication is completed to read regions)
- Session – It is synchronous but not consistent for all users. Clients who commits the data can see the fresh data.
- Consistent Prefix – Copy of the data order will be maintained and they will see the uniform data.
Based on these 5 consistency concepts, the application developer can decide to choose either to give the best performance or a consistent data to the end users.
Example of Eventual Replication:
The data is not consistent for the read region and users in write region alone can see the fresh data.
https://exchangequery.files.wordpress.com/2018/04/picture6.png?w=600
{kind=link}
Replicate Data with a single click:
Provides more regions to replicate just in few clicks which are more than Amazon and Google combined.
https://exchangequery.files.wordpress.com/2018/04/picture7.png?w=600
{kind=link}
Available API Methods:
https://exchangequery.files.wordpress.com/2018/04/picture8.png?w=600
{kind=link}
Recommendations from Microsoft:
- According to Microsoft, Cosmos DB can be used for “any Web, mobile, gaming and IoT applications that need to handle massive amounts of reads and writes on a global scale with low response times.
- ” However, Cosmos DB’s best use cases might be those that leverage event-driven Azure functions, which enable application code to be executed in a serverless environment.
- Its not a relational database.Its not a SQL server not good at random joins . Does not matter what value of data it is as long as we don’t do joins.
- Minimum is 400RU per collection, which would be around 25 USD / month. Each Collections are charged individually, even if they contain small amounts of data. Need to change our code to put all of documents into one collection.
- It’s a “NoSQL” platform with SQL on top of it for SQL operations better not to do multiple joins.