Azure AD Connect: User Consolidation
Introduction
Syncing on premise Active Directory (AD) with Azure Active Directory (AD) is a very common scenario nowadays, which is achieved through Azure AD connect.
However, as Benjamin Franklin said: "If you fail to plan, you are planning to fail!" Although he did not quote it for Azure AD, but it is very much applicable here when we are planning to sync on premise AD with Azure AD. There are few things which we should keep in mind, and few points which we need to consider before we start sync process. One of the most critical decision is how the matching users would be identified and consolidated in Azure AD , because our goal is that user would be represented only once in Azure AD.
The objective of this article is to discuss multiple scenarios and best practices related to user consolidation.
This article is as per Microsoft guidelines related to Azure AD connect and user consolidation.
Azure AD Connect Topology
Before we discuss user consolidation, it is important that we discuss Azure AD connect supported and unsupported topologies.
- Microsoft recommends that an organization should avoid using multiple Azure AD tenants, and should opt for single Azure AD tenant.
- Azure AD tenants are completely separate from each other by design, and it is not possible to link multiple tenants.
- There is a 1:1 relationship between Azure AD connect and Azure AD tenant. Microsoft does not support multiple Azure AD connect servers for a single tenant.
- If there are more than one on premise AD forests which we are going to sync with one Azure AD tenant, we must use single Azure AD connect server.
- We should also deploy a staging server, which would act as a DR if the primary Azure AD server is down. In staging mode, Azure AD connect reads all data but does not write anything either in Azure AD or on premise AD.
While designing Azure AD Connect topology for an organization, we should always refer this Microsoft Article and follow the recommendations.
User Consolidation
Microsoft strongly recommends enabling Active Directory Recycle Bin in on premise forest(s), before syncing with Azure AD.
In the Azure AD connect installation wizard, there is a section “Uniquely identifying your users”. We have to configure this page very carefully before we start syncing.
While configuring the options, please evaluate the scenario on the basis of below factors:
1) How many AD Forests we are going to sync with Azure AD? Single Forest or Multiple Forests?
*
*
2) How the on-premise AD Forests are designed? Are there forest trusts exist between these forests?
*
*
*3) In case of multiple forests, is there any specific resource forest? *
A resource forest is where all resources like Exchange, Skype are deployed ,which is used by other account forests. A resource forest should not have active user accounts, but it can have disabled user accounts from other forests. Other account forests typically have trust with this resource forest.
4) If there is no specific resource forest, users and resources can be located in any forest. Is that the current scenario?
*5) Is there any future plan to migrate users from one forest to another forest? *
6) Is it a new Azure AD tenant, or an existing tenant where cloud identities (like Office 365) already exist?
Once we get the answer of below questions, we can plan how users would be uniquely identified in Azure AD.
Default Configuration
Please note that if we are syncing a single forest with a new Azure AD tenant, we should not be worried with any of these points, and we can leave the default configuration in the “Uniquely identifying your users” page.
Also, if we sync multiple forests with a single Azure AD tenant, but there is no trust between these forests, no common Exchange / Skype, and users are represented only once within its own forest, we can go with default configuration. Here we are assuming that the Azure AD Tenant is new and does not contain user identities in cloud.

As stated by Microsoft, the default configuration assumes certain things:
- Each user has only one enabled account, and the forest where this account is located is used to authenticate the user.
- Each user has only one mailbox.
- The forest that hosts the mailbox for a user has the best data quality for attributes visible in the Exchange Global Address List (GAL).
- If you have a linked mailbox, there's also an account in a different forest used for sign-in.
Please note that **if we have more than one active account or more than one mailbox, the sync engine picks one and ignores the other. **
Also, a linked mailbox with no other active account is not exported to Azure AD.
Users are represented across multiple forests
If the default scenario is not applicable for us, and we are planning to sync on premise AD with Azure AD, there can be multiple types of conflicting situations:
1. Conflict between on premise AD forests: Users are represented across multiple forests, and we need to consolidate them while syncing to Azure AD. We need to decide which attributes would be used for user consolidation.
2. Conflict between on premise AD and Azure AD: Users are already present in Azure AD tenant as cloud identity, and while syncing with on premise there would be a conflict between on premise and Azure AD.
Conflict between on premise AD Forests
This scenario is very common if we have a multi forest environment, and users are added to another forest security groups or they are present in another forest Exchange.
Microsoft has a guideline, which we can refer to decide which attribute(s) would be used to compare and consolidate users, best on the forest topology.
Topology 1: Multiple forests: Full Mesh (with optional GALSync)
In this topology, users and resources can be located in any forest. This means, there is no specific resource forest which is dedicated for resources like Exchange, Skype or other products.
In general, there are two way trust exists between these forests.
If Exchange is present in more than one forest and GALSync is enabled, every user is then represented as a contact in all other forests.
If this is our scenario, we should choose below option to consolidate users:
User identities exist across multiple directories, match using: Mail attribute

When we select the “Mail attribute” option, below things happen:
1. This option joins users and contacts if the mail attribute has the same value in different forests.
2. User objects whose Mail attribute aren't populated will not be synchronized to Azure AD.
Topology 2: Multiple forests: Account-Resource Forest
In many organizations, there is a dedicated forest for deploying resources like Exchange, Skype and others.
Typically, resource forest does not contain active user accounts, but it can contain disabled user accounts as required by Exchange and other products.
There are other account forests, where active user accounts are present who uses the resource forest for email, skype etc.
If this is our scenario, then we should choose below option to consolidate users:
User identities exist across multiple directories, match using: ObjectSID and msExchangeMasterAccountSID attributes

When we select this option, below things happen:
- This option joins an enabled user in an account forest with a disabled user in a resource forest.
- In Exchange, this configuration is known as a linked mailbox.
Note: This option is not only applicable for Exchange, but also for Lync / Skype. If Exchange is not present in resource forest, but Lync / Skype is present then also this option is applicable.
So to consolidate users between multiple on premise forests, we will use any of these options which we have discussed.
Please note that this is only applicable for user object, and not for any other type of object. Also, there is no role of Azure AD to consolidate users from multiple forests, as this is completely handled by Azure AD Connect sync service.
Conflict between on premise AD and Azure AD
It may be possible that organization is already using Azure AD for Office 365 or any other application, and they already have cloud only users. Now, we decide to sync Azure AD with their on premise AD.
There can be another situation, where we have lost our existing Azure AD connect server and reinstalling a new instance of Azure AD connect. In this case, we already have synced users in Azure AD, by previous Azure AD connect instance.
Microsoft says “An object in Azure AD is either mastered in the cloud (Azure AD) or on-premises.” This is a very important statement, which means that for a single object, it is not possible to manage some attribute on-premises and some attributes in Azure AD. Every object has a flag which indicates where the object is managed.
Let’s discuss what happens in this scenario, when we already have uses in Azure AD and then we are going to sync with on premise AD.
When we install Azure AD Connect and start synchronizing with Azure AD, the Azure AD sync service (in Azure AD) checks every new object and try to find an existing object to match. There are three attributes used for this process:
Soft match >
*
*
a) userPrincipalName
b) proxyAddresses (users primary email address)
**Hard match > **
c) sourceAnchor/immutableID (we will discuss it later)
A match on userPrincipalName and proxyAddresses is known as a Soft Match. A match on sourceAnchor is known as Hard Match.
Please note that this matching is only done for new objects, which are coming from Azure AD connect to Azure AD. After syncing with Azure AD, if we change any attribute of any object on premise which would result conflict with any existing Azure AD object, we would receive an error. No matching algorithm will run in that case.
As Microsoft states, for a new installation of Azure AD Connect, there is no practical difference between a soft- and a hard-match. The different between soft and hard matching is important when we lose our existing Azure AD connect server, and want to reinstall it.
Understanding sourceAnchor/immutableID
In case of Hard Matching (which is done jointly be Azure AD Connect and Azure AD), the two objects are being compared by the sourceAnchor attribute, which is also called as immutable ID.
**sourceAnchor should be one of the attribute of the object, which will remain same throughout the lifetime of the object. This is the reason sourceAnchor attribute is also called as immutable ID. **
Which attribute is the best candidate to be considered as sourceAnchor ? The attribute who’s value will never change throughout the object's lifetime.
If any organization is using employee ID attribute in AD, then that is a good candidate to be a sourceAnchor, because Employee ID value is generally unique and is never changed for an employee.
In earlier versions of Azure AD Connect (till version version 1.1.524.0) , the default sourceAnchor value was objectGUID. While the objectGUID attribute remains same for an object throughout its lifetime, the value can be changed if the user is migrated to a different forest, or user is recreated in AD after an accidental deletion.
Also, objectGUID attribute is not writable attribute, even AD cannot change the value of this attribute once created.
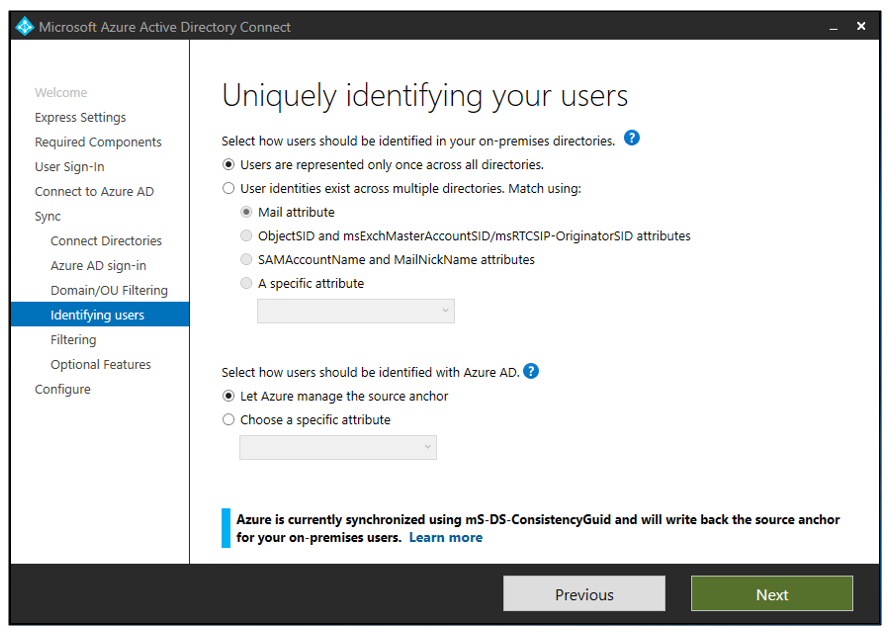
Due to this drawback, Microsoft has changed the default sourceAnchor attribute from objectGUID to mS-DS-ConsistencyGuid in the recent versions of Azure AD Connect (version 1.1.524.0 and onwards).
However, if we need to change the sourceAnchor attribute from objectGUID to mS-DS-ConsistencyGuid, we have to use version 1.1.552.0 or higher. Changing sourceAnchor attribute was not allowed in earlier Azure AD Connect versions.
Please note, that mS-DS-ConsistencyGuid is the sourceAnchor only for user objects, for other types of objects (like computers), objectGUID is still the default sourceAnchor attribute.
What is the advantage of using mS-DS-ConsistencyGuid as sourceAnchor?
The major advantage is, mS-DS-ConsistencyGuid is writable, it’s value can be changed if required.
Here is how Azure AD Sync Service works while syncing user objects:
1. It uses mS-DS-ConsistencyGuid as the sourceAnchor attribute. However, if the value is blank, then it writes the value of objectGUID attribute to the mS-DS-ConsistencyGuid attribute.
2. Once the mS-DS-ConsistencyGuid is filled up with respective objectGUID attribute value, it then synchronizes the users with Azure AD.
3. Now, if users are migrated from one forest to another, the value of objectGUID attribute will be changed, since it will be randomly re-generated by AD in the new forest. However, the value of the attribute mS-DS-ConsistencyGuid will not be changed. So during a hard match, Azure AD would be able to identify the migrated users by comparing the mS-DS-ConsistencyGuid value.
One important point to keep in mind is, the sourceAnchor value can only be changed during the initial installation value of Azure AD Connect. Once AAD Connect is installed, the sourceAnchor value will become read only, and to change it Azure AD Connect needs to be uninstalled and reinstalled.
Also, once an object has been exported to Azure AD, it is not possible to change its sourceAnchor value, it will through an error.
If a matching is found
If Azure AD detects a matching of attribute between an existing object in Azure AD and an object coming from on premise AD, following things will happen:
a) The object coming from on premise AD will get preference, and will replace all attributes for that object which are present in cloud.
b) The object was previously managed marked as cloud identity, and managed through cloud. But now, it will be flagged as on premise object, and will be managed from on premise.
c) All cloud attribute values of that object would be overwritten by on premise attribute, so we should be very careful to maintain correct values in the on premise attributes.
Verify before commit
Every environment is unique, and different from each other. So we have to be extremely careful when we plan a strategy for user consolidation. It is always better to check what attributes are going to be synced to Azure AD, before the actual syncing.
It is also important to locate the common identifiers.
To assess the result, we have to follow below steps:
- On the last page of the installation, enable staging mode.
- In the same page, unselect the “Start Synchronization” option.
In staging mode, Azure AD connect will receive all updates, but it will not write anything to Azure Ad or on premise AD. In staging mode, we can assess what all attributes are going to be synced, by executing some commands in the Azure AD connect server where we have enabled staging mode. Please follow this link where Microsoft has clearly mentioned the steps.
See Also
- Azure AD Connect: Supported Topologies
- Uniquely identifying your users
- Azure AD Connect: When you have an existent tenant
- Azure AD Connect sync: Operational tasks and consideration