Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Important
Items marked (preview) in this article are currently in public or private preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
In the field of AI application development, A/B experimentation has emerged as a critical practice. It allows for continuous evaluation of AI applications, balancing business impact, risk, and cost. While offline and online evaluations provide some insights, they need to be supplemented with A/B experimentation to ensure the use of right metrics for measuring success. A/B experimentation involves comparing two versions of a feature, prompt, or model using feature flags or dynamic configuration to determine which performs better. This method is essential for several reasons:
- Enhancing Model Performance - A/B experimentation allows developers to systematically test different versions of AI models, algorithms, or features to identify the most effective version. With controlled experiments, you can measure the effect of changes on key performance metrics, such as accuracy, user engagement, and response time. This iterative process enables you to identify the best model, helps fine-tuning and ensures that your models deliver the best possible results.
- Reducing Bias and Improving Fairness - AI models can inadvertently introduce biases, leading to unfair outcomes. A/B experimentation helps identify and mitigate these biases by comparing the performance of different model versions across diverse user groups. This ensures that the AI applications are fair and equitable, providing consistent performance for all users.
- Accelerating Innovation - A/B experimentation fosters a culture of innovation by encouraging continuous experimentation and learning. You can quickly validate new ideas and features, reducing the time and resources spent on unproductive approaches. This accelerates the development cycle and allows teams to bring innovative AI solutions to market faster.
- Optimizing User Experience - User experience is paramount in AI applications. A/B experimentation enables you to experiment with different user interface designs, interaction patterns, and personalization strategies. By analyzing user feedback and behavior, you can optimize the user experience, making AI applications more intuitive and engaging.
- Data-Driven Decision Making - A/B experimentation provides a robust framework for data-driven decision making. Instead of relying on intuition or assumptions, you can base your decisions on empirical evidence. This leads to more informed and effective strategies for improving AI applications.
How does A/B experimentation fit into the AI application lifecycle?
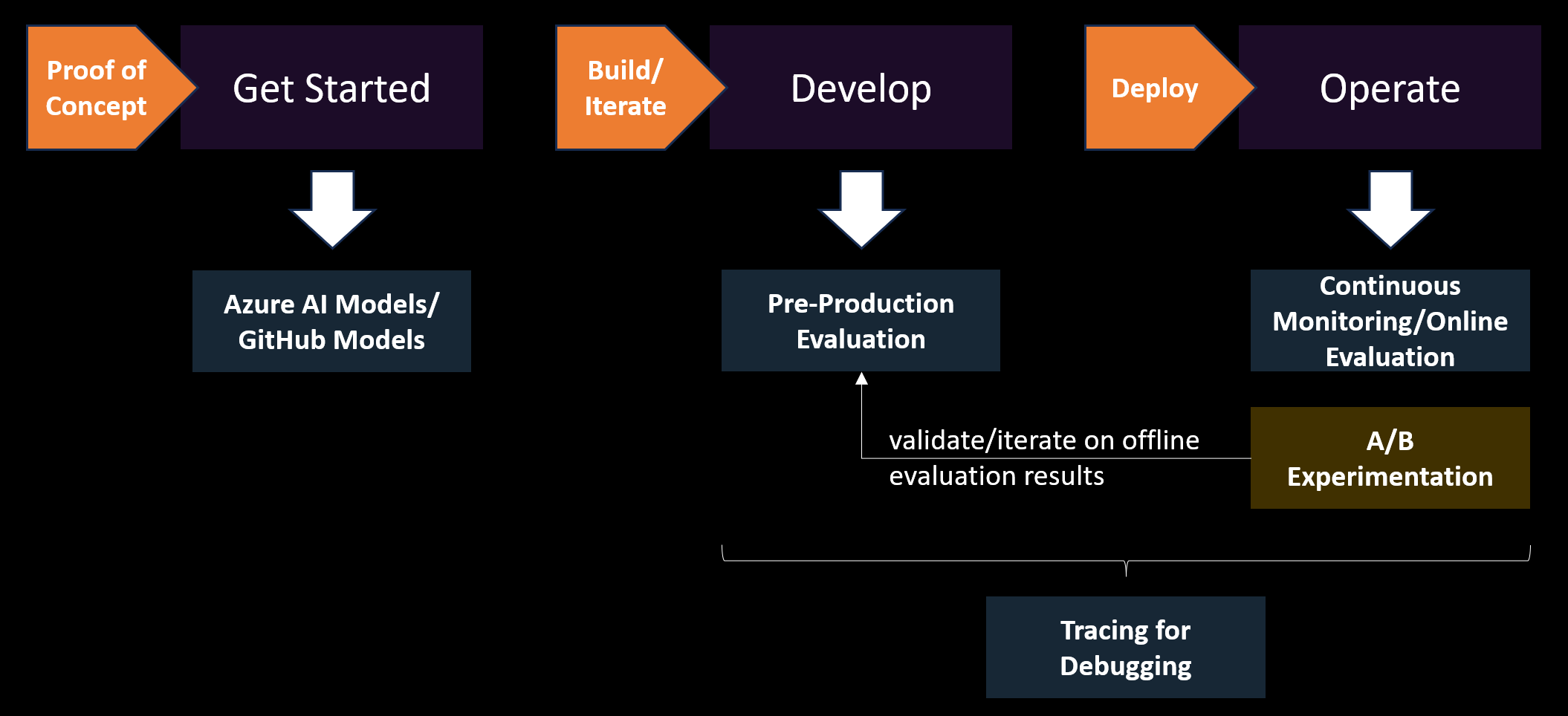
A/B experimentation and offline evaluation are both essential components in the development of AI applications, each serving unique purposes that complement each other.
Offline evaluation involves testing AI models using test datasets to measure their performance on various metrics such as fluency and coherence. After selecting a model in the Azure AI Model Catalog or GitHub Model marketplace, offline preproduction evaluation is crucial for initial model validation during integration testing, allowing you to identify potential issues and make improvements before deploying the model or application to production.
However, offline evaluation has its limitations. It can't fully capture the complex interactions that occur in real-world scenarios. This is where A/B experimentation comes into play. By deploying different versions of the AI model or UX features to live users, A/B experimentation provides insights into how the model and application performs in real-world conditions. This helps you understand user behavior, identify unforeseen issues, and measure the impact of changes on model evaluation metrics, operational metrics (for example, latency), and business metrics (for example, account sign-ups, conversions, etc.).
As shown in the diagram, while offline evaluation is essential for initial model validation and refinement, A/B experimentation provides the real-world testing needed to ensure the AI application performs effectively and fairly in practice. Together, they form a comprehensive approach to developing robust, safe, and user-friendly AI applications.
Scale AI applications with Azure AI evaluations and online A/B experimentation using CI/CD workflows
We're significantly simplifying the evaluation and A/B experimentation process with GitHub Actions that can be integrated seamlessly into existing CI/CD workflows in GitHub. In your CI workflows, you can now use our Azure AI Evaluation GitHub Action to run manual or automated evaluations after changes are committed using the Azure AI Evaluation SDK to compute metrics such as coherence and fluency.
Using the Online Experimentation GitHub Action (preview), you can integrate A/B experimentation into your continuous deployment (CD) workflows. You can use this feature to automatically create and analyze A/B experiments with built-in AI model metrics and custom metrics as part of your CD workflows after successful deployment. Additionally, you can use the GitHub Copilot for Azure plugin to assist with experimentation, create metrics, and support decision-making.
Important
Online experimentation is available through a limited access preview. Request access to learn more.
Azure AI Partners
You're also welcome to use your own A/B experimentation provider to run experiments on your AI applications. There are several solutions to choose from available in Azure Marketplace:
Statsig
Statsig is experimentation platform for Product, Engineering, and Data Science teams that connects the features you build to the business metrics you care about. Statsig powers automatic A/B tests and experiments for web and mobile applications, giving teams a comprehensive view of which features are driving impact (and which aren't). To simplify experimentation with Azure AI, Statsig has published SDKs built on top of the Azure AI SDK and Azure AI Inference API that makes it easier for Statsig customers to run experiments.
Other A/B Experimentation Providers
Split.io
Split.io enables you to set up feature flags and safely deploy to production, controlling who sees which features and when. You can also connect every flag to contextual data, so you know if your features are making things better or worse, and act without hesitation. With Split's Microsoft integrations, we're helping development teams manage feature flags, monitor release performance, experiment, and surface data to make ongoing, data-driven decisions.
LaunchDarkly
LaunchDarkly is a feature management and experimentation platform built with software developers in mind. It enables you to manage feature flags on a large scale, run A/B tests and experiments, and progressively deliver software to ship with confidence.