Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
You can use a custom speech model for some time after you deploy it to your custom endpoint. But when new base models are made available, the older models are expired. You must periodically recreate and train your custom model from the latest base model to take advantage of the improved accuracy and quality.
Here are some key terms related to the model lifecycle:
- Training: Taking a base model and customizing it to your domain/scenario by using text data and/or audio data. In some contexts such as the REST API properties, training is also referred to as adaptation.
- Transcription: Using a model and performing speech recognition (decoding audio into text).
- Endpoint: A specific deployment of either a base model or a custom model that only you can access.
Note
Endpoints used by F0 Speech resources are deleted after seven days.
Expiration timeline
Here are timelines for model adaptation and transcription expiration:
- Training is available for one year after the quarter when Microsoft created the base model.
- Transcription with a base model is available for two years after the quarter when Microsoft created the base model.
- Transcription with a custom model is available for two years after the quarter when you created the custom model.
In this context, quarters end on January 15, April 15, July 15, and October 15.
What to do when a model expires
When a custom model or base model expires, it's no longer available for transcription. You can change the model that is used by your custom speech endpoint without downtime.
| Transcription route | Expired model result | Recommendation |
|---|---|---|
| Custom endpoint | Speech recognition requests fall back to the most recent base model for the same locale. You get results, but recognition might not accurately transcribe your domain data. | Update the endpoint's model as described in the Deploy a custom speech model guide. |
| Batch transcription | Batch transcription requests for expired models fail with a 4xx error. | In each Transcriptions - Submit REST API request body, set the model property to a base model or custom model that isn't expired. Otherwise don't include the model property to always use the latest base model. |
Get base model expiration dates
Tip
Bring your custom speech models from Speech Studio to the Microsoft Foundry portal. In Microsoft Foundry portal, you can pick up where you left off by connecting to your existing Speech resource. For more information about connecting to an existing Speech resource, see Connect to an existing Speech resource.
The last date that you could use the base model for training was shown when you created the custom model. For more information, see Train a custom speech model.
Follow these instructions to get the transcription expiration date for a base model:
- Sign in to the Microsoft Foundry portal.
- Select Fine-tuning from the left pane.
- Select AI Service fine-tuning.
- Select the custom model that you want to check from the Model name column.
- Select Deploy models.
- The expiration date for the model is shown in the Expiration column. This date is the last date that you can use the model for transcription.
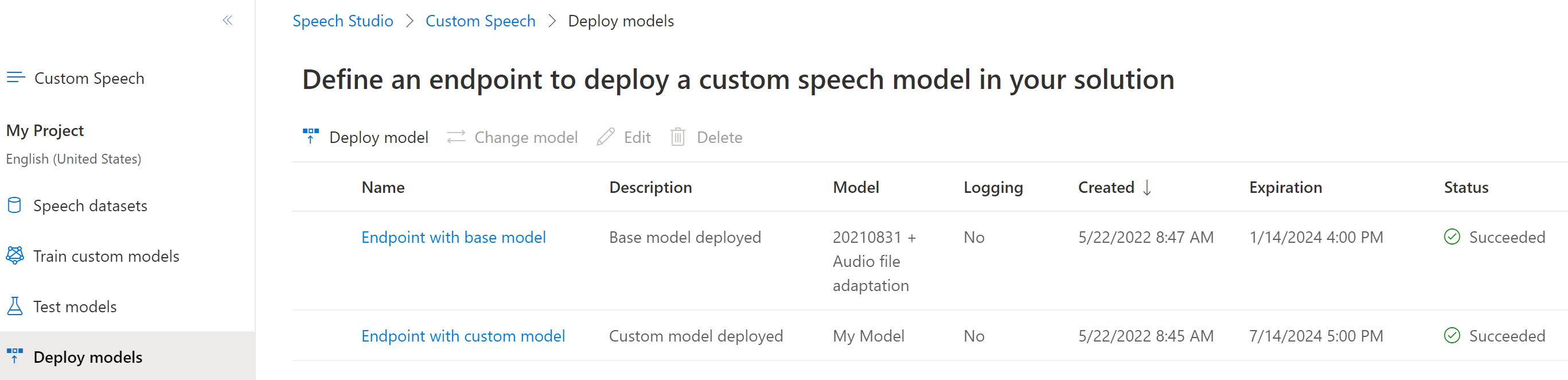
Sign in to the Speech Studio.
Select Custom speech > Your project name > Deploy models.
The expiration date for the model is shown in the Expiration column. This date is the last date that you can use the model for transcription.
Before proceeding, make sure that you have the Speech CLI installed and configured.
To get the training and transcription expiration dates for a base model, use the spx csr model status command. Construct the request parameters according to the following instructions:
- Set the
urlproperty to the URI of the base model that you want to get. You can run thespx csr list --basecommand to get available base models for all locales.
Here's an example Speech CLI command to get the training and transcription expiration dates for a base model:
spx csr model status --api-version v3.2 --model https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/aaaabbbb-0000-cccc-1111-dddd2222eeee
Important
You must set --api-version v3.2. The Speech CLI uses the REST API, but doesn't yet support versions later than v3.2.
In the response, take note of the date in the adaptationDateTime property. This property is the last date that you can use the base model for training. Also take note of the date in the transcriptionDateTime property. This date is the last date that you can use the base model for transcription.
You should receive a response body in the following format:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/bbbbcccc-1111-dddd-2222-eeee3333ffff",
"datasets": [],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/1aae1070-7972-47e9-a977-87e3b05c457d/manifest"
},
"properties": {
"deprecationDates": {
"adaptationDateTime": "2023-01-15T00:00:00Z",
"transcriptionDateTime": "2024-01-15T00:00:00Z"
}
},
"lastActionDateTime": "2022-05-06T10:52:02Z",
"status": "Succeeded",
"createdDateTime": "2021-10-13T00:00:00Z",
"locale": "en-US",
"displayName": "20210831 + Audio file adaptation",
"description": "en-US base model"
}
For Speech CLI help with models, run the following command:
spx help csr model
To get the training and transcription expiration dates for a base model, use the Models_GetBaseModel operation of the Speech to text REST API. You can make a Models_ListBaseModels request to get available base models for all locales.
Make an HTTP GET request using the model URI as shown in the following example. Replace BaseModelId with your model ID, replace YourSpeechResoureKey with your Speech resource key, and replace YourServiceRegion with your Speech resource region.
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/BaseModelId" -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey"
In the response, take note of the date in the adaptationDateTime property. This date is the last date that you can use the base model for training. Also take note of the date in the transcriptionDateTime property. This date is the last date that you can use the base model for transcription.
You should receive a response body in the following format:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/bbbbcccc-1111-dddd-2222-eeee3333ffff",
"datasets": [],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/1aae1070-7972-47e9-a977-87e3b05c457d/manifest"
},
"properties": {
"deprecationDates": {
"adaptationDateTime": "2023-01-15T00:00:00Z",
"transcriptionDateTime": "2024-01-15T00:00:00Z"
}
},
"lastActionDateTime": "2022-05-06T10:52:02Z",
"status": "Succeeded",
"createdDateTime": "2021-10-13T00:00:00Z",
"locale": "en-US",
"displayName": "20210831 + Audio file adaptation",
"description": "en-US base model"
}
Get custom model expiration dates
Follow these instructions to get the transcription expiration date for a custom model:
- Sign in to the Microsoft Foundry portal.
- Select Fine-tuning from the left pane.
- Select AI Service fine-tuning.
- Select the custom model that you want to check from the Model name column.
- Select Deploy models.
- The expiration date for the model is shown in the Expiration column. This date is the last date that you can use the model for transcription.
Follow these instructions to get the transcription expiration date for a custom model:
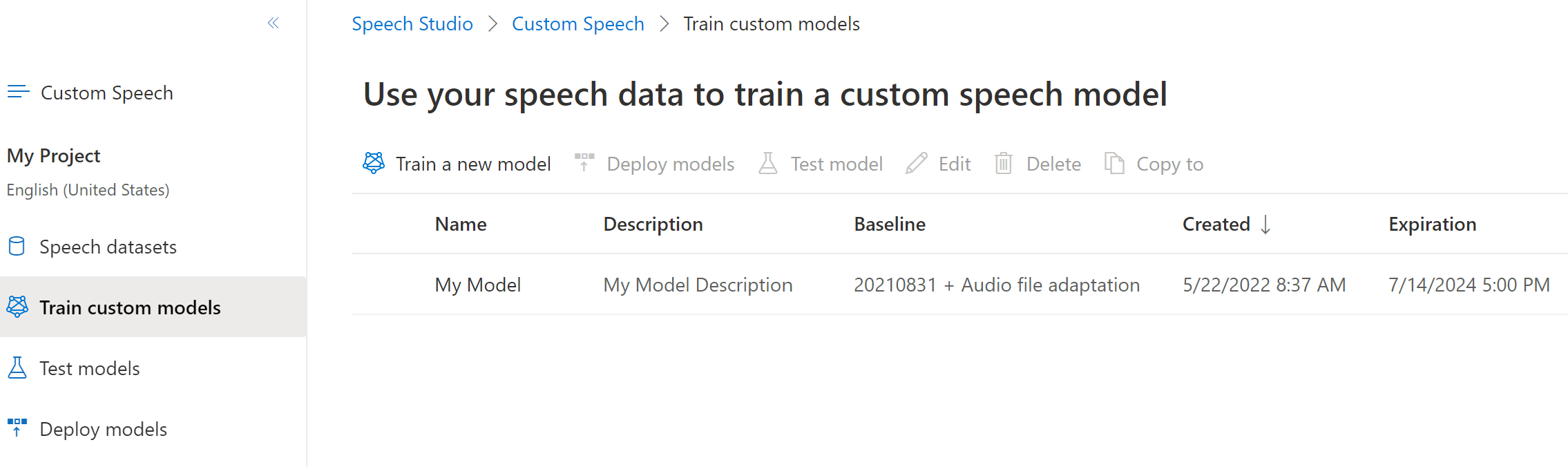
Sign in to the Speech Studio.
Select Custom speech > Your project name > Train custom models.
The expiration date the custom model is shown in the Expiration column. This date is the last date that you can use the custom model for transcription. Base models aren't shown on the Train custom models page.
You can also follow these instructions to get the transcription expiration date for a custom model:
Sign in to the Speech Studio.
Select Custom speech > Your project name > Deploy models.
The expiration date for the model is shown in the Expiration column. This date is the last date that you can use the model for transcription.
Before proceeding, make sure that you have the Speech CLI installed and configured.
To get the transcription expiration date for your custom model, use the spx csr model status command. Construct the request parameters according to the following instructions:
- Set the
urlproperty to the URI of the model that you want to get. ReplaceYourModelIdwith your model ID and replaceYourServiceRegionwith your Speech resource region.
Here's an example Speech CLI command to get the transcription expiration date for your custom model:
spx csr model status --api-version v3.2 --model https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.1/models/YourModelId
Important
You must set --api-version v3.2. The Speech CLI uses the REST API, but doesn't yet support versions later than v3.2.
In the response, take note of the date in the transcriptionDateTime property. This date is the last date that you can use your custom model for transcription. The adaptationDateTime property isn't applicable, since custom models aren't used to train other custom models.
You should receive a response body in the following format:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/ccccdddd-2222-eeee-3333-ffff4444aaaa",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/datasets/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
}
],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/86c4ebd7-d70d-4f67-9ccc-84609504ffc7/manifest",
"copyTo": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/86c4ebd7-d70d-4f67-9ccc-84609504ffc7:copyto"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/eeeeffff-4444-aaaa-5555-bbbb6666cccc"
},
"properties": {
"deprecationDates": {
"adaptationDateTime": "2023-01-15T00:00:00Z",
"transcriptionDateTime": "2024-07-15T00:00:00Z"
}
},
"lastActionDateTime": "2022-05-21T13:21:01Z",
"status": "Succeeded",
"createdDateTime": "2022-05-22T16:37:01Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description"
}
For Speech CLI help with models, run the following command:
spx help csr model
To get the transcription expiration date for your custom model, use the Models_GetCustomModel operation of the Speech to text REST API.
Make an HTTP GET request using the model URI as shown in the following example. Replace YourModelId with your model ID, replace YourSpeechResoureKey with your Speech resource key, and replace YourServiceRegion with your Speech resource region.
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.1/models/YourModelId" -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey"
In the response, take note of the date in the transcriptionDateTime property. This date is the last date that you can use your custom model for transcription. The adaptationDateTime property isn't applicable, since custom models aren't used to train other custom models.
You should receive a response body in the following format:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/ccccdddd-2222-eeee-3333-ffff4444aaaa",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/datasets/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
}
],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/86c4ebd7-d70d-4f67-9ccc-84609504ffc7/manifest",
"copyTo": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/86c4ebd7-d70d-4f67-9ccc-84609504ffc7:copyto"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/eeeeffff-4444-aaaa-5555-bbbb6666cccc"
},
"properties": {
"deprecationDates": {
"adaptationDateTime": "2023-01-15T00:00:00Z",
"transcriptionDateTime": "2024-07-15T00:00:00Z"
}
},
"lastActionDateTime": "2022-05-21T13:21:01Z",
"status": "Succeeded",
"createdDateTime": "2022-05-22T16:37:01Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description"
}