Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Keyword recognition detects a word or short phrase within a stream of audio. This technique is also referred to as keyword spotting.
The most common use case of keyword recognition is voice activation of virtual assistants. For example, "Hey Cortana" is the keyword for the Cortana assistant. Upon recognition of the keyword, a scenario-specific action is carried out. For virtual assistant scenarios, a common resulting action is speech recognition of audio that follows the keyword.
Generally, virtual assistants are always listening. Keyword recognition acts as a privacy boundary for the user. A keyword requirement acts as a gate that prevents unrelated user audio from crossing the local device to the cloud.
To balance accuracy, latency, and computational complexity, keyword recognition is implemented as a multistage system. For all stages beyond the first, audio is only processed if the stage prior to it recognizes the keyword of interest.
The current system is designed with multiple stages that span the edge and cloud:
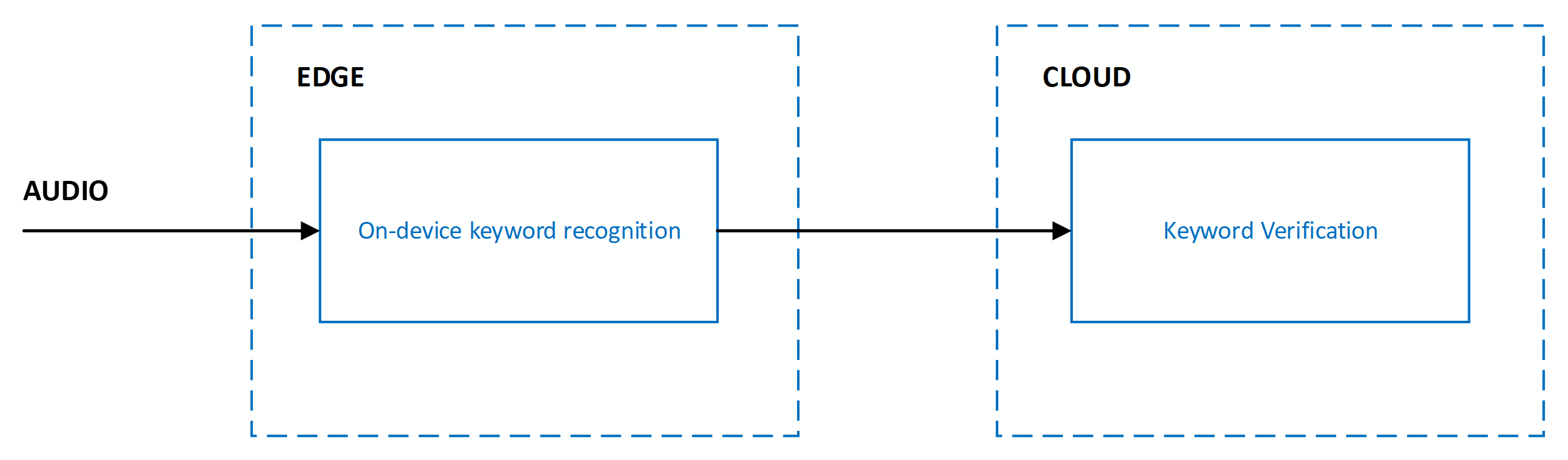
Accuracy of keyword recognition is measured via the following metrics:
- Correct accept rate: Measures the system's ability to recognize the keyword spoken by a user. The correct accept rate is also known as the true positive rate.
- False accept rate: Measures the system's ability to filter out audio that isn't the keyword spoken by a user. The false accept rate is also known as the false positive rate.
The goal is to maximize the correct accept rate while minimizing the false accept rate. The current system is designed to detect a keyword or phrase preceded by a short amount of silence. Detecting a keyword in the middle of a sentence or utterance isn't supported.
Custom keyword for on-device models
With the Custom Keyword portal on Speech Studio, you can generate keyword recognition models that execute at the edge by specifying any word or short phrase. You can further personalize your keyword model by choosing the right pronunciations.
Pricing
There's no cost to use custom keyword to generate models, including both Basic and Advanced models. There's also no cost to run models on-device with the Speech SDK when used with other Speech service features such as speech to text.
Types of models
You can use custom keyword to generate two types of on-device models for any keyword.
| Model type | Description |
|---|---|
| Basic | Best suited for demo or rapid prototyping purposes. Models are generated with a common base model and can take up to 15 minutes to be ready. Models might not have optimal accuracy characteristics. |
| Advanced | Best suited for product integration purposes. Models are generated with adaptation of a common base model by using simulated training data to improve accuracy characteristics. It can take up to 48 hours for models to be ready. |
Note
You can view a list of regions that support the Advanced model type in the keyword recognition region support documentation.
Neither model type requires you to upload training data. Custom keyword fully handles data generation and model training.
Pronunciations
When you create a new model, custom keyword automatically generates possible pronunciations of the provided keyword. You can listen to each pronunciation and choose all variations that closely represent the way you expect users to say the keyword. All other pronunciations shouldn't be selected.
It's important to be deliberate about the pronunciations you select to ensure the best accuracy characteristics. For example, if you choose more pronunciations than you need, you might get higher false accept rates. If you choose too few pronunciations, where not all expected variations are covered, you might get lower correct accept rates.
Test models
After custom keyword generates on-device models, the models can be tested directly on the portal. You can use the portal to speak directly into your browser and get keyword recognition results.
Keyword verification
Keyword verification is a cloud service that reduces the effect of false accepts from on-device models with robust models running on Azure. Tuning or training isn't required for keyword verification to work with your keyword. Incremental model updates are continually deployed to the service to improve accuracy and latency and are transparent to client applications.
Pricing
Keyword verification is always used in combination with speech to text. There's no cost to use keyword verification beyond the cost of speech to text.
Keyword verification and speech to text
When keyword verification is used, it's always in combination with speech to text. Both services run in parallel, which means audio is sent to both services for simultaneous processing.
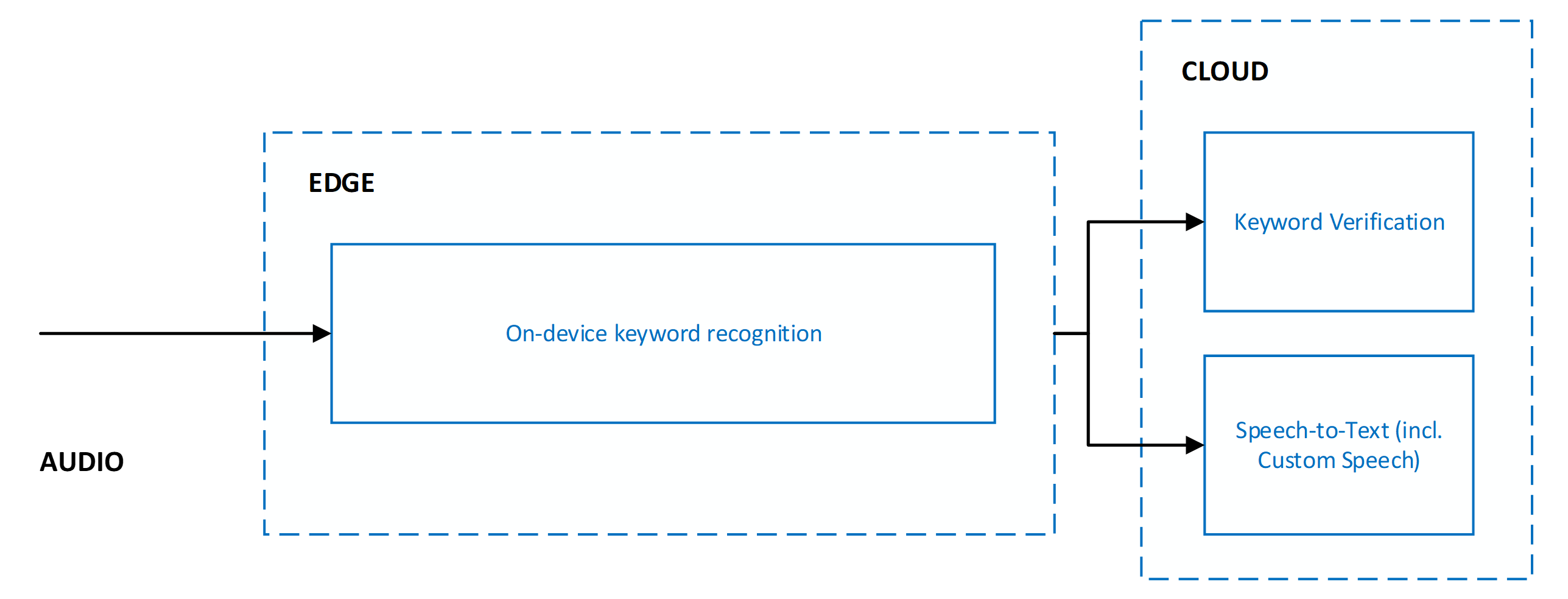
Running keyword verification and speech to text in parallel yields the following benefits:
- No other latency on speech to text results: Parallel execution means that keyword verification adds no latency. The client receives speech to text results as quickly. If keyword verification determines the keyword wasn't present in the audio, speech to text processing is terminated. This action protects against unnecessary speech to text processing. Network and cloud model processing increases the user-perceived latency of voice activation. For more information, see Recommendations and guidelines.
- Forced keyword prefix in speech to text results: Speech to text processing ensures that the results sent to the client are prefixed with the keyword. This behavior allows for increased accuracy in the speech to text results for speech that follows the keyword.
- Increased speech to text timeout: Because of the expected presence of the keyword at the beginning of audio, speech to text allows for a longer pause of up to five seconds after the keyword before it determines the end of speech and terminates speech to text processing. This behavior ensures that the user experience is correctly handled for staged commands (<keyword> <pause> <command>) and chained commands (<keyword> <command>).
Keyword verification responses and latency considerations
For each request to the service, keyword verification returns one of two responses: accepted or rejected. The processing latency varies depending on the length of the keyword and the length of the audio segment expected to contain the keyword. Processing latency doesn't include network cost between the client and Speech services.
| Keyword verification response | Description |
|---|---|
| Accepted | Indicates the service believed that the keyword was present in the audio stream provided as part of the request. |
| Rejected | Indicates the service believed that the keyword wasn't present in the audio stream provided as part of the request. |
Rejected cases often yield higher latencies as the service processes more audio than accepted cases. By default, keyword verification processes a maximum of two seconds of audio to search for the keyword. If the keyword isn't found in two seconds, the service times out and signals a rejected response to the client.
Use keyword verification with on-device models from custom keyword
The Speech SDK enables seamless use of on-device models generated by using custom keyword with keyword verification and speech to text. It transparently handles:
- Audio gating to keyword verification and speech recognition based on the outcome of an on-device model.
- Communicating the keyword to keyword verification.
- Communicating any more metadata to the cloud for orchestrating the end-to-end scenario.
You don't need to explicitly specify any configuration parameters. All necessary information is automatically extracted from the on-device model generated by custom keyword.
Speech SDK integration and scenarios
The Speech SDK enables easy use of personalized on-device keyword recognition models generated with custom keyword and keyword verification. To ensure that your product needs can be met, the SDK supports the following two scenarios:
The offline keyword recognition scenario is best suited for products without network connectivity that use a customized on-device keyword model from custom keyword.