Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Multi-device conversation makes it easy to create a speech or text conversation between multiple clients and coordinate the messages sent between them.
Note
Multi-device conversation access is a preview feature.
With multi-device conversation, you can:
- Connect multiple clients into the same conversation and manage the sending and receiving of messages between them.
- Easily transcribe audio from each client and send the transcription to the others, with optional translation.
- Easily send text messages between clients, with optional translation.
You can build a feature or solution that works across an array of devices. Each device can independently send messages (either transcriptions of audio or instant messages) to all other devices.
Multi-device Conversation is suited for scenarios with multiple devices, each with a single microphone.
Important
Multi-device conversation does not support sending audio files between clients: only the transcription and/or translation.
Key features
- Real-time transcription: Everyone receives a transcript of the conversation, so they can follow along the text in real-time or save it for later.
- Real-time translation: With more than 70 supported languages for text translation, users can translate the conversation to their preferred languages.
- Readable transcripts: The transcription and translation are easy to follow, with punctuation and sentence breaks.
- Voice or text input: Each user can speak or type on their own device, depending on the language support capabilities enabled for the participant's chosen language. Refer to Language support.
- Message relay: The multi-device conversation service distributes messages sent by one client to all the others, in the languages of their choice.
- Message identification: Every message that users receive in the conversation is tagged with the nickname of the user who sent it.
Use cases
Lightweight conversations
Creating and joining a conversation is easy. One user acts as the 'host' and create a conversation, which generates a random five letter conversation code and a QR code. All other users can join the conversation by typing in the conversation code or scanning the QR code.
Since users join via the conversation code and aren't required to share contact information, it's easy to create quick, on-the-spot conversations.
Inclusive meetings
Real-time transcription and translation can help make conversations accessible for people who speak different languages and/or are deaf or hard of hearing. Each person can also actively participate in the conversation, by speaking their preferred language or sending instant messages.
Presentations
You can also provide captions for presentations and lectures both on-screen and on the audience members' own devices. After the audience joins with the conversation code, they can see the transcript in their preferred language, on their own device.
How it works
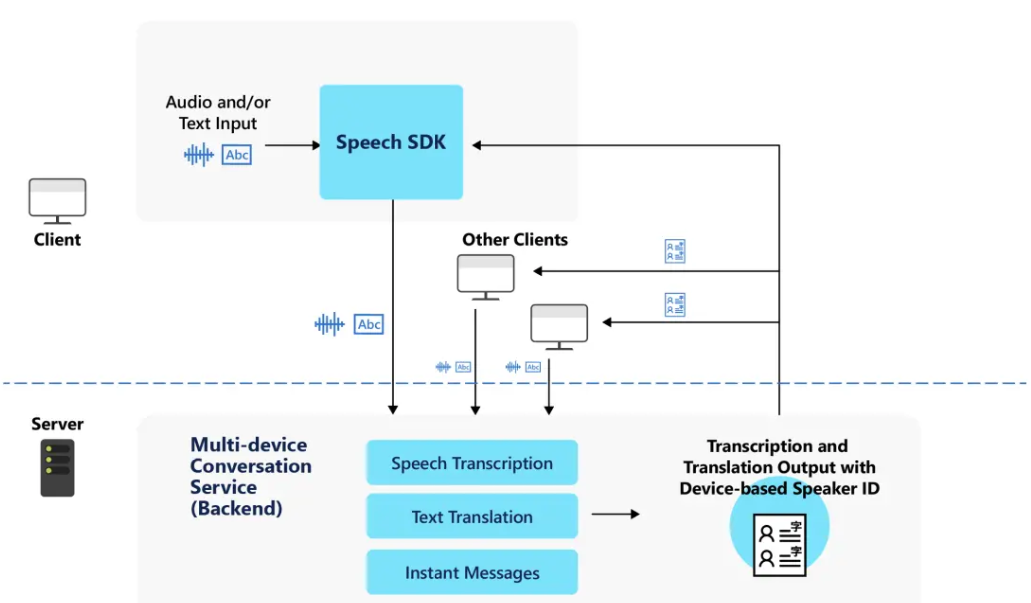
All clients use the Speech SDK to create or join a conversation. The Speech SDK interacts with the multi-device conversation service, which manages the lifetime of a conversation. The conversation includes the list of participants, each client's chosen language, and the messages sent.
Each client can send audio or instant messages. The service uses speech recognition to convert audio into text, and send instant messages as-is. If clients choose different languages, then the service translates all messages to the specified language(s) of each client.
Overview of Conversation, Host, and Participant
A conversation is a session that one user starts for the other participating users to join. All clients connect to the conversation using the five-letter conversation code.
Each conversation creates metadata that includes:
- Timestamps of when the conversation started and ended
- List of all participants in the conversation, which includes each user's chosen nickname and primary language for speech or text input.
There are two types of users in a conversation: host and participant.
The host is the user who starts a conversation, and who acts as the administrator of that conversation.
- Each conversation can only have one host
- The host must be connected to the conversation during the conversation. If the host leaves the conversation, the conversation ends for all other participants.
- The host has a few extra controls to manage the conversation:
- Lock the conversation - prevent more participants from joining
- Mute all participants - prevent other participants from sending any messages to the conversation, whether transcribed from speech or instant messages
- Mute individual participants
- Unmute all participants
- Unmute individual participants
A participant is a user who joins a conversation.
- A participant can leave and rejoin the same conversation at any time, without ending the conversation for other participants.
- Participants can't lock the conversation or mute/unmute others
Note
Each conversation can have up to 100 participants, of which 10 can be simultaneously speaking at any given time.
Language support
Each user must choose a primary language when they join a conversation. Their selection is the language they speak and send instant messages in, and also the language they see other users' messages.
There are two kinds of languages: speech to text and text-only:
If the user chooses a speech to text language as their primary language, then they can use both speech and text input in the conversation.
If the user chooses a text-only language, then they can only use text input and send instant messages in the conversation. Text-only languages are the languages that are supported for text translation, but not speech to text. You can see available languages on the language support page.
Apart from their primary language, each participant can also specify more languages for translating the conversation.
The following table is a summary of what the user can do in a multi-device conversation, based to their chosen primary language.
| What the user can do in the conversation | Speech to text | Text-only |
|---|---|---|
| Use speech input | ✔️ | ❌ |
| Send instant messages | ✔️ | ✔️ |
| Translate the conversation | ✔️ | ✔️ |
Note
For lists of available speech to text and text translation languages, see supported languages.