Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
With personal voice, you can enable your users to get AI generated replication of their own voices in a few seconds. With a verbal statement and a short speech sample as the audio prompt, you can create a personal voice for your users and allow them to generate speech in any of the more than 90 languages supported across more than 100 locales.
Note
Personal voice is available in these regions: West Europe, East US, West US 2, South East Asia and East Asia. For supported locales, see personal voice language support.
The following table summarizes the difference between personal voice and professional voice.
| Comparison | Personal voice | Professional voice |
|---|---|---|
| Target scenarios | Business customers to build an app to allow their users to create and use their own personal voice in the app. | Professional scenarios like brand and character voices for chat bots, or audio content reading. |
| Use cases | Restricted to limited use cases. See the transparency note. | |
| Training data | Make sure you follow the code of conduct. | Bring your own data. Recording in a professional studio is recommended. |
| Required data size | One minute of human speech. | 300-2000 utterances (about 30 minutes to 3 hours of human speech). |
| Training time | Less than 5 seconds | Approximately 20-40 compute hours. |
| Voice quality | Natural | Highly natural |
| Multilingual support | Yes. The voice is able to speak about 100 languages, with automatic language detection enabled. | Yes. You need to select the "Neural – cross lingual" feature to train a model that speaks a different language from the training data. |
| Availability | The demo on Speech Studio is available upon registration. Access to the API is restricted to eligible customers and approved use cases. Request access through the intake form. | You can only use professional voice fine-tuning after access is approved. Professional voice fine-tuning access is limited based on eligibility and usage criteria. Request access through the intake form. |
| Pricing | Check the pricing details here1. | Check the pricing details here. |
| Responsible AI requirements | Speaker's verbal statement required. No unapproved use case allowed. | Speaker's verbal statement required. No unapproved use case allowed. |
1 Note that personal voice pricing will only be visible for service regions where the feature is available, including West Europe, East US, West US 2, South East Asia and East Asia.
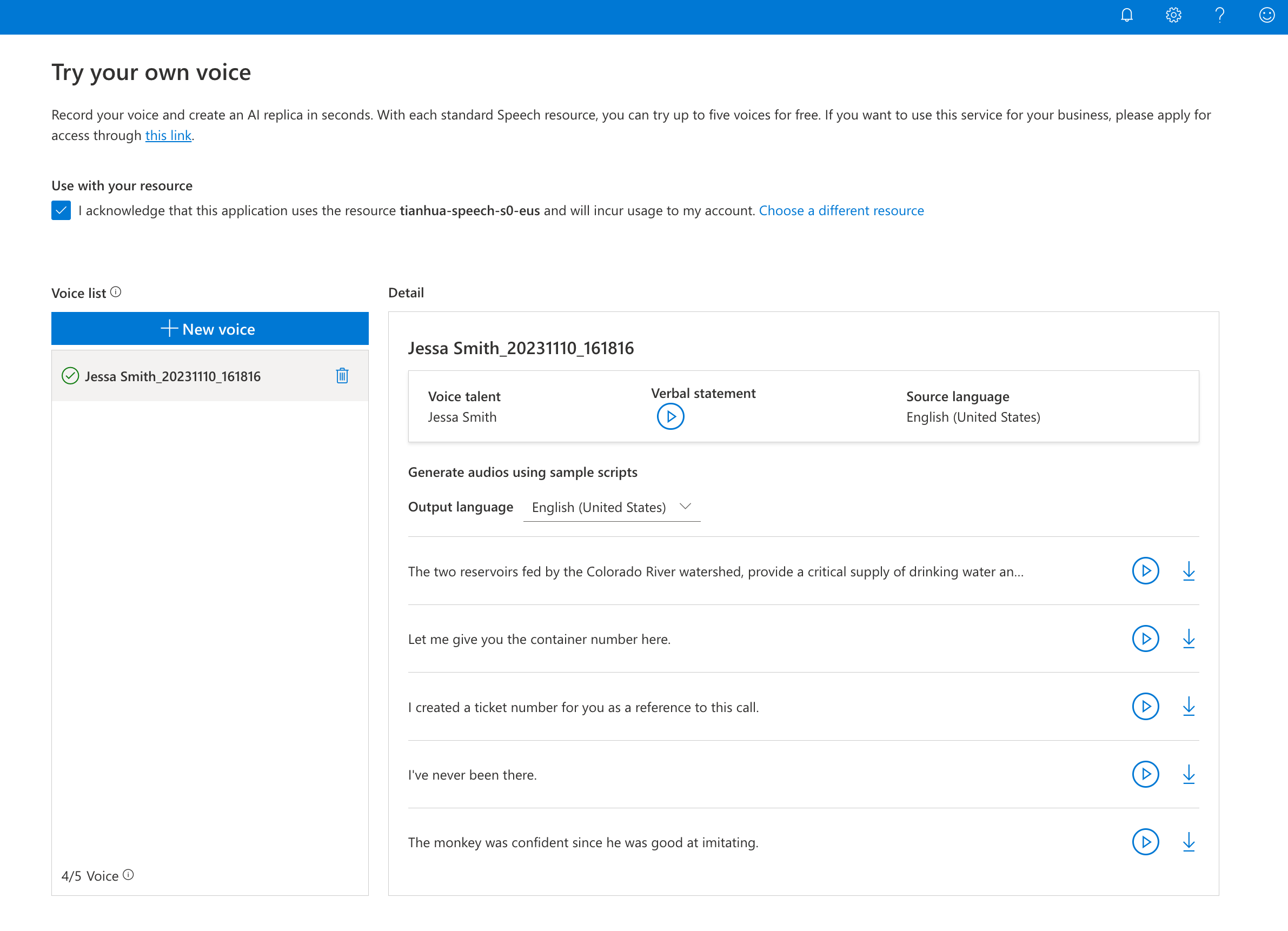
Try the demo
If you have an S0 resource, you can access the personal voice demo in Speech Studio. To use the personal voice API, you can apply for access here.
Go to Speech Studio
Select the Personal Voice card.
You can record your own voice and try the voice output samples in different languages. The demo includes a subset of the languages supported by personal voice.

How to create a personal voice
To get started, here's a summary of the steps to create a personal voice:
- Create a project.
- Upload consent file. With the personal voice feature, it's required that every voice be created with explicit consent from the user. A recorded statement from the user is required acknowledging that the customer (Azure AI Speech resource owner) will create and use their voice.
- Get a speaker profile ID for the personal voice. You get a speaker profile ID based on the speaker's verbal consent statement and an audio prompt. The user's voice characteristics are encoded in the
speakerProfileIdproperty that's used for text to speech.
Once you have a personal voice, you can use it to synthesize speech in any of the 91 languages supported across 100+ locales. A locale tag isn't required. Personal voice uses automatic language detection at the sentence level. For more information, see use personal voice in your application.
Tip
Check out the code samples in the Speech SDK repository on GitHub to see how to use personal voice in your application.
Reference documentation
Responsible AI
We care about the people who use AI and the people who will be affected by it as much as we care about technology. For more information, see the Responsible AI transparency notes.
Next steps
- Create a project.
- Learn more about custom voice in the overview.
- Learn more about Speech Studio in the overview.