Batch processing kit for Speech containers
Use the batch processing kit to complement and scale out workloads on Speech containers. Available as a container, this open-source utility helps facilitate batch transcription for large numbers of audio files, across any number of on-premises and cloud-based speech container endpoints.
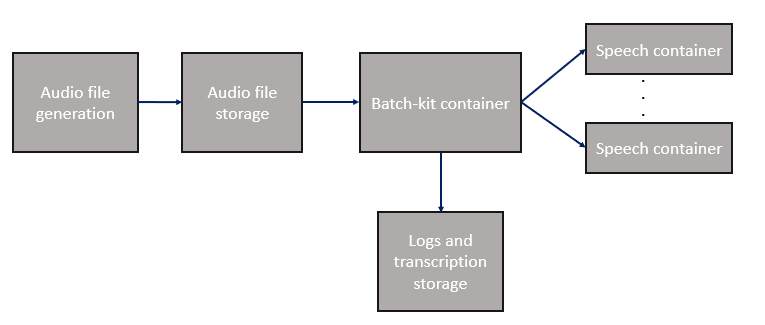
The batch kit container is available for free on GitHub and Docker hub. You're only billed for the Speech containers you use.
| Feature | Description |
|---|---|
| Batch audio file distribution | Automatically dispatch large numbers of files to on-premises or cloud-based Speech container endpoints. Files can be on any POSIX-compliant volume, including network filesystems. |
| Speech SDK integration | Pass common flags to the Speech SDK, including: n-best hypotheses, diarization, language, profanity masking. |
| Run modes | Run the batch client once, continuously in the background, or create HTTP endpoints for audio files. |
| Fault tolerance | Automatically retry and continue transcription without losing progress, and differentiate between which errors can, and can't be retried on. |
| Endpoint availability detection | If an endpoint becomes unavailable, the batch client continues transcribing, using other container endpoints. When the client is available it automatically begins using the endpoint. |
| Endpoint hot-swapping | Add, remove, or modify Speech container endpoints during runtime without interrupting the batch progress. Updates are immediate. |
| Real-time logging | Real-time logging of attempted requests, timestamps, and failure reasons, with Speech SDK log files for each audio file. |
Get the container image with docker pull
Use the docker pull command to download the latest batch kit container.
Note
The following example pulls a public container image from Docker Hub. We recommend that you authenticate with your Docker Hub account (docker login) first instead of making an anonymous pull request. To improve reliability when using public content, import and manage the image in a private Azure container registry. Learn more about working with public images.
docker pull docker.io/batchkit/speech-batch-kit:latest
Endpoint configuration
The batch client takes a yaml configuration file that specifies the on-premises container endpoints. The following example can be written to /mnt/my_nfs/config.yaml, which is used in the examples below.
MyContainer1:
concurrency: 5
host: 192.168.0.100
port: 5000
rtf: 3
MyContainer2:
concurrency: 5
host: BatchVM0.corp.redmond.microsoft.com
port: 5000
rtf: 2
MyContainer3:
concurrency: 10
host: localhost
port: 6001
rtf: 4
This yaml example specifies three speech containers on three hosts. The first host is specified by a IPv4 address, the second is running on the same VM as the batch-client, and the third container is specified by the DNS hostname of another VM. The concurrency value specifies the maximum concurrent file transcriptions that can run on the same container. The rtf (Real-Time Factor) value is optional and can be used to tune performance.
The batch client can dynamically detect if an endpoint becomes unavailable (for example, due to a container restart or networking issue), and when it becomes available again. Transcription requests won't be sent to containers that are unavailable, and the client continues using other available containers. You can add, remove, or edit endpoints at any time without interrupting the progress of your batch.
Run the batch processing container
Note
- This example uses the same directory (
/my_nfs) for the configuration file and the inputs, outputs, and logs directories. You can use hosted or NFS-mounted directories for these folders. - Running the client with the
–hflag lists the available command-line parameters, and their default values. - The batch processing container is only supported on Linux.
Use the Docker run command to start the container. This command starts an interactive shell inside the container.
docker run --network host --rm -ti -v /mnt/my_nfs:/my_nfs --entrypoint /bin/bash /mnt/my_nfs:/my_nfs docker.io/batchkit/speech-batch-kit:latest
To run the batch client:
run-batch-client -config /my_nfs/config.yaml -input_folder /my_nfs/audio_files -output_folder /my_nfs/transcriptions -log_folder /my_nfs/logs -file_log_level DEBUG -nbest 1 -m ONESHOT -diarization None -language en-US -strict_config
To run the batch client and container in a single command:
docker run --network host --rm -ti -v /mnt/my_nfs:/my_nfs docker.io/batchkit/speech-batch-kit:latest -config /my_nfs/config.yaml -input_folder /my_nfs/audio_files -output_folder /my_nfs/transcriptions -log_folder /my_nfs/logs
The client starts running. If an audio file was transcribed in a previous run, the client automatically skips the file. Files are sent with an automatic retry if transient errors occur, and you can differentiate between which errors you want to the client to retry on. On a transcription error, the client continues transcription, and can retry without losing progress.
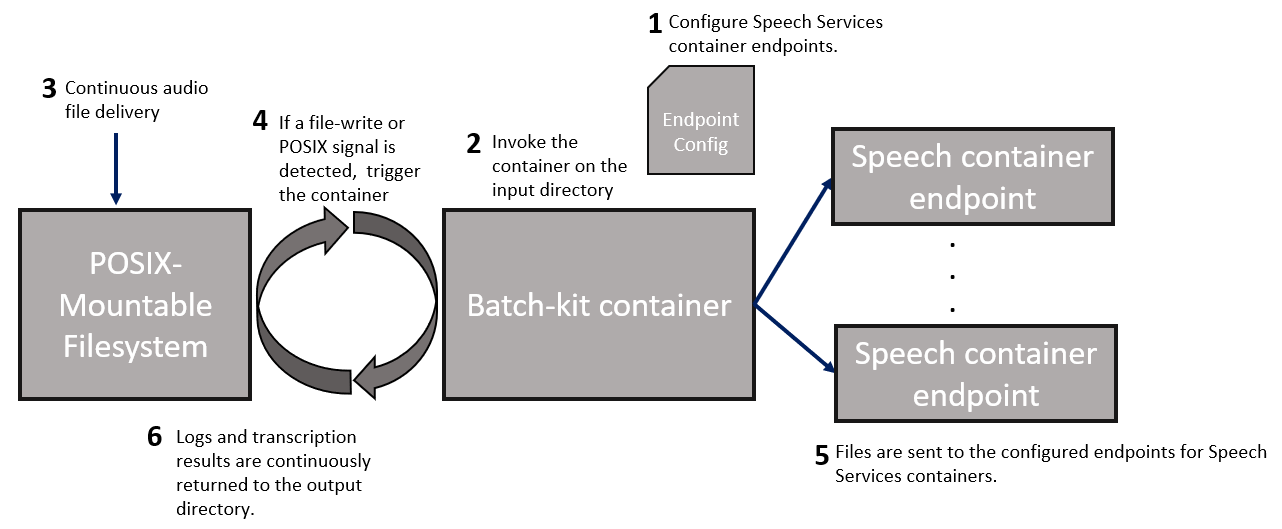
Run modes
The batch processing kit offers three modes, using the --run-mode parameter.
ONESHOT mode transcribes a single batch of audio files (from an input directory and optional file list) to an output folder.
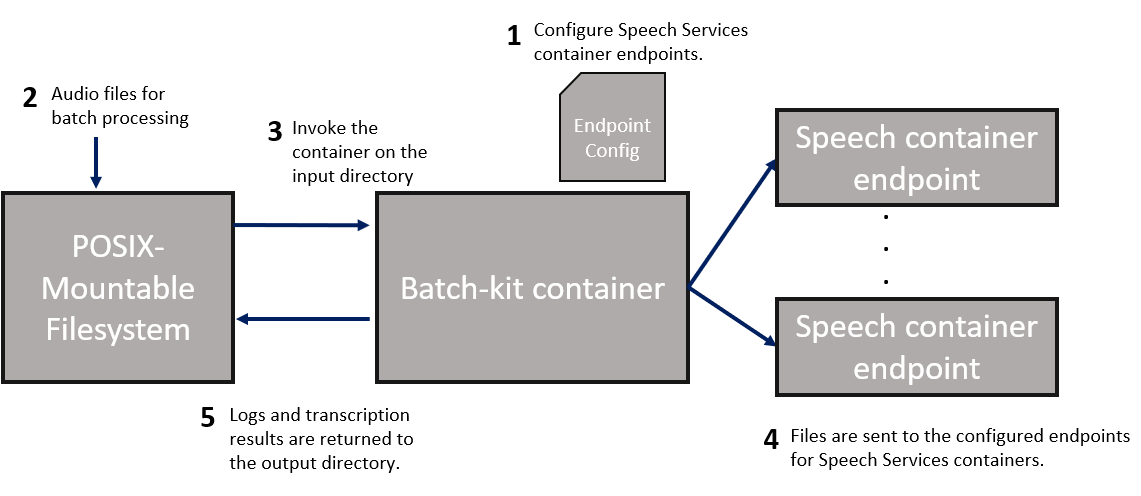
- Define the Speech container endpoints that the batch client uses in the
config.yamlfile. - Place audio files for transcription in an input directory.
- Invoke the container on the directory to begin processing the files. If the audio file is already transcribed in a previous run with the same output directory (same file name and checksum), the client skips the file.
- The files are dispatched to the container endpoints from step 1.
- Logs and the Speech container output are returned to the specified output directory.
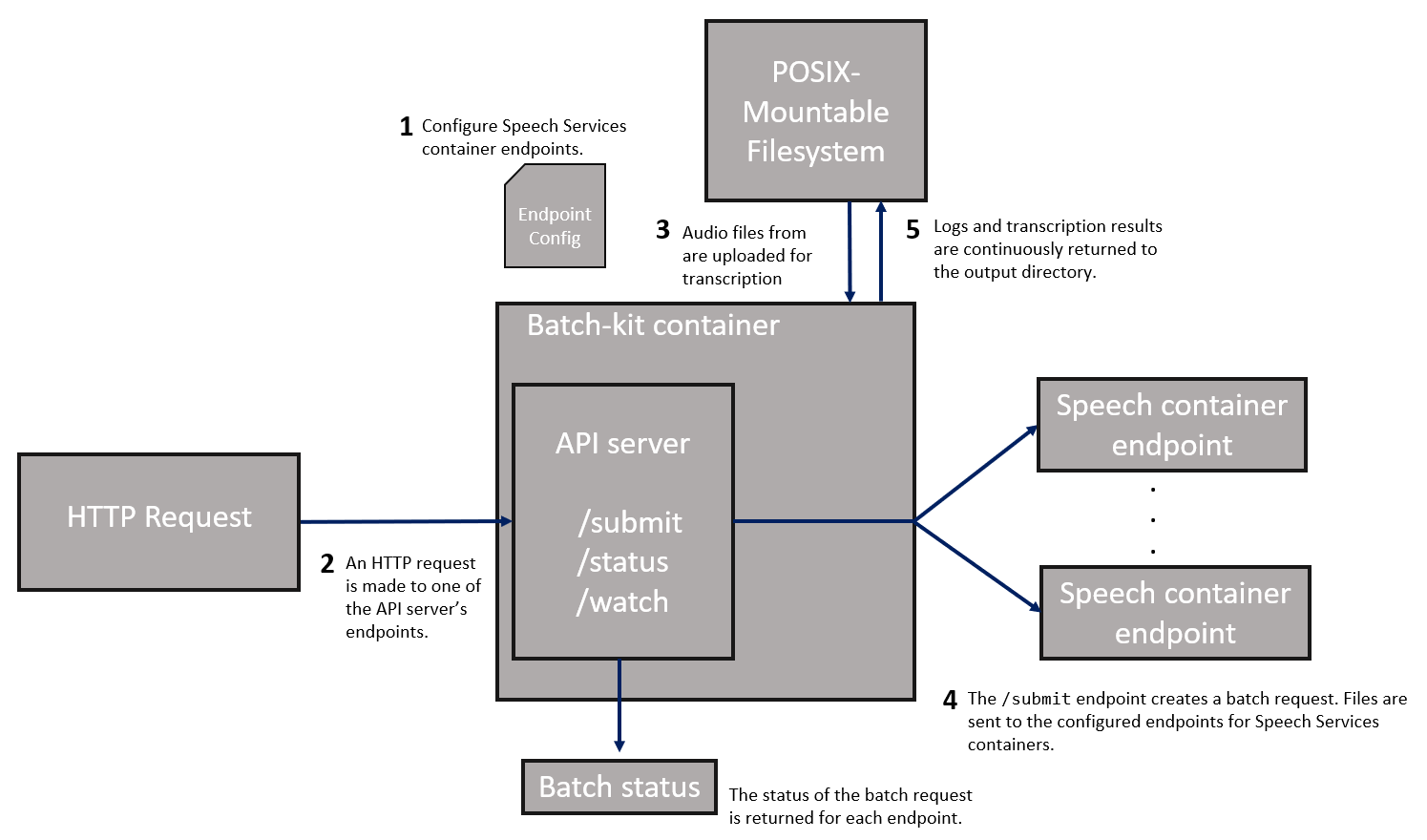
Logging
Note
The batch client may overwrite the run.log file periodically if it gets too large.
The client creates a run.log file in the directory specified by the -log_folder argument in the docker run command. Logs are captured at the DEBUG level by default. The same logs are sent to the stdout/stderr, and filtered depending on the -file_log_level or console_log_level arguments. This log is only necessary for debugging, or if you need to send a trace for support. The logging folder also contains the Speech SDK logs for each audio file.
The output directory specified by -output_folder contains a run_summary.json file, which is periodically rewritten every 30 seconds or whenever new transcriptions are finished. You can use this file to check on progress as the batch proceeds. It also contains the final run statistics and final status of every file when the batch is completed. The batch is completed when the process has a clean exit.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for