Custom speech to text containers with Docker
The custom speech to text container transcribes real-time speech or batch audio recordings with intermediate results. You can use a custom model that you created in the custom speech portal. In this article, you learn how to download, install, and run a custom speech to text container.
For more information about prerequisites, validating that a container is running, running multiple containers on the same host, and running disconnected containers, see Install and run Speech containers with Docker.
Container images
The custom speech to text container image for all supported versions and locales can be found on the Microsoft Container Registry (MCR) syndicate. It resides within the azure-cognitive-services/speechservices/ repository and is named custom-speech-to-text.

The fully qualified container image name is, mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text. Either append a specific version or append :latest to get the most recent version.
| Version | Path |
|---|---|
| Latest | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest |
| 4.10.0 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:4.10.0-amd64 |
All tags, except for latest, are in the following format and are case sensitive:
<major>.<minor>.<patch>-<platform>-<prerelease>
Note
The locale and voice for custom speech to text containers is determined by the custom model ingested by the container.
The tags are also available in JSON format for your convenience. The body includes the container path and list of tags. The tags aren't sorted by version, but "latest" is always included at the end of the list as shown in this snippet:
{
"name": "azure-cognitive-services/speechservices/custom-speech-to-text",
"tags": [
<--redacted for brevity-->
"4.4.0-amd64",
"4.5.0-amd64",
"4.6.0-amd64",
"4.7.0-amd64",
"4.8.0-amd64",
"4.9.0-amd64",
"4.10.0-amd64",
"latest"
]
}
Get the container image with docker pull
You need the prerequisites including required hardware. Also see the recommended allocation of resources for each Speech container.
Use the docker pull command to download a container image from Microsoft Container Registry:
docker pull mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest
Note
The locale and voice for custom Speech containers is determined by the custom model ingested by the container.
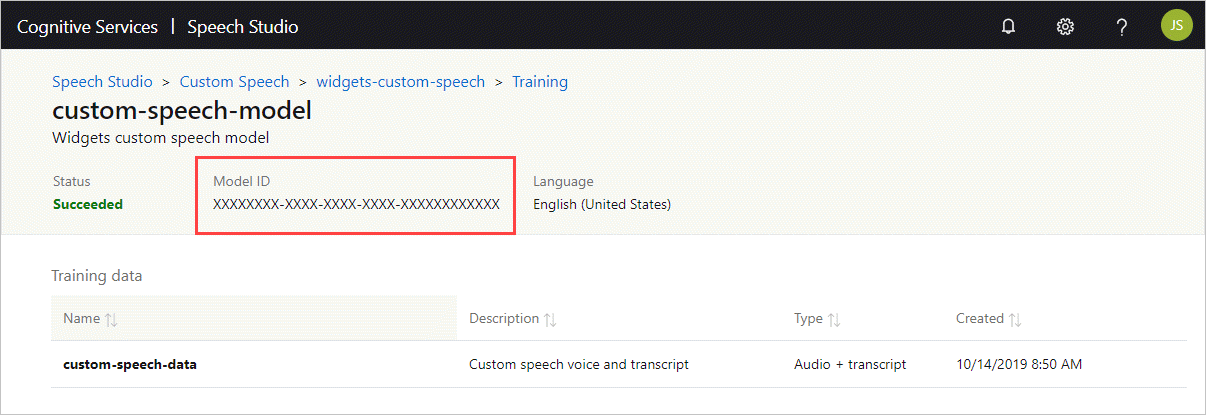
Get the model ID
Before you can run the container, you need to know the model ID of your custom model or a base model ID. When you run the container, you specify one of the model IDs to download and use.
The custom model must be trained by using the Speech Studio. For information about how to get the model ID, see custom speech model lifecycle.
Obtain the Model ID to use as the argument to the ModelId parameter of the docker run command.
Display model download
Before you run the container, you can optionally get the available display models information and choose to download those models into your speech to text container to get highly improved final display output. Display model download is available with custom-speech-to-text container version 3.1.0 and later.
Note
Although you use the docker run command, the container isn't started for service.
You can query or download any or all of these display model types: Rescoring (Rescore), Punctuation (Punct), resegmentation (Resegment), and wfstitn (Wfstitn). Otherwise, you can use the FullDisplay option (with or without the other types) to query or download all types of display models.
Set the BaseModelLocale to query the latest available display model on the target locale. If you include multiple display model types, the command returns the latest available display models for each type. For example:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
BaseModelLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Set the DisplayLocale to download the latest available display model on the target locale. When you set DisplayLocale, you must also specify FullDisplay or a space-separated subset of display models. The command downloads the latest available display model for each specified type. For example:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
DisplayLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Set one model ID parameter to download a specific display model: Rescoring (RescoreId), Punctuation (PunctId), resegmentation (ResegmentId), or wfstitn (WfstitnId). This is similar to how you would download a base model via the ModelId parameter. For example, to download a rescoring display model, you can use the following command with the RescoreId parameter:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
RescoreId={RESCORE_MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Note
If you set more than one query or download parameter, the command will prioritize in this order: BaseModelLocale, model ID, and then DisplayLocale (only applicable for display models).
Run the container with docker run
Use the docker run command to run the container for service.
The following table represents the various docker run parameters and their corresponding descriptions:
| Parameter | Description |
|---|---|
{VOLUME_MOUNT} |
The host computer volume mount, which Docker uses to persist the custom model. An example is c:\CustomSpeech where the c:\ drive is located on the host machine. |
{MODEL_ID} |
The custom speech or base model ID. For more information, see Get the model ID. |
{ENDPOINT_URI} |
The endpoint is required for metering and billing. For more information, see billing arguments. |
{API_KEY} |
The API key is required. For more information, see billing arguments. |
When you run the custom speech to text container, configure the port, memory, and CPU according to the custom speech to text container requirements and recommendations.
Here's an example docker run command with placeholder values. You must specify the VOLUME_MOUNT, MODEL_ID, ENDPOINT_URI, and API_KEY values:
docker run --rm -it -p 5000:5000 --memory 8g --cpus 4 \
-v {VOLUME_MOUNT}:/usr/local/models \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
ModelId={MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
This command:
- Runs a custom speech to text container from the container image.
- Allocates 4 CPU cores and 8 GB of memory.
- Loads the custom speech to text model from the volume input mount, for example, C:\CustomSpeech.
- Exposes TCP port 5000 and allocates a pseudo-TTY for the container.
- Downloads the model given the
ModelId(if not found on the volume mount). - If the custom model was previously downloaded, the
ModelIdis ignored. - Automatically removes the container after it exits. The container image is still available on the host computer.
For more information about docker run with Speech containers, see Install and run Speech containers with Docker.
Use the container
Speech containers provide websocket-based query endpoint APIs that are accessed through the Speech SDK and Speech CLI. By default, the Speech SDK and Speech CLI use the public Speech service. To use the container, you need to change the initialization method.
Important
When you use the Speech service with containers, be sure to use host authentication. If you configure the key and region, requests will go to the public Speech service. Results from the Speech service might not be what you expect. Requests from disconnected containers will fail.
Instead of using this Azure-cloud initialization config:
var config = SpeechConfig.FromSubscription(...);
Use this config with the container host:
var config = SpeechConfig.FromHost(
new Uri("ws://localhost:5000"));
Instead of using this Azure-cloud initialization config:
auto speechConfig = SpeechConfig::FromSubscription(...);
Use this config with the container host:
auto speechConfig = SpeechConfig::FromHost("ws://localhost:5000");
Instead of using this Azure-cloud initialization config:
speechConfig, err := speech.NewSpeechConfigFromSubscription(...)
Use this config with the container host:
speechConfig, err := speech.NewSpeechConfigFromHost("ws://localhost:5000")
Instead of using this Azure-cloud initialization config:
SpeechConfig speechConfig = SpeechConfig.fromSubscription(...);
Use this config with the container host:
SpeechConfig speechConfig = SpeechConfig.fromHost("ws://localhost:5000");
Instead of using this Azure-cloud initialization config:
const speechConfig = sdk.SpeechConfig.fromSubscription(...);
Use this config with the container host:
const speechConfig = sdk.SpeechConfig.fromHost("ws://localhost:5000");
Instead of using this Azure-cloud initialization config:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithSubscription:...];
Use this config with the container host:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithHost:"ws://localhost:5000"];
Instead of using this Azure-cloud initialization config:
let speechConfig = SPXSpeechConfiguration(subscription: "", region: "");
Use this config with the container host:
let speechConfig = SPXSpeechConfiguration(host: "ws://localhost:5000");
Instead of using this Azure-cloud initialization config:
speech_config = speechsdk.SpeechConfig(
subscription=speech_key, region=service_region)
Use this config with the container endpoint:
speech_config = speechsdk.SpeechConfig(
host="ws://localhost:5000")
When you use the Speech CLI in a container, include the --host ws://localhost:5000/ option. You must also specify --key none to ensure that the CLI doesn't try to use a Speech key for authentication. For information about how to configure the Speech CLI, see Get started with the Azure AI Speech CLI.
Try the speech to text quickstart using host authentication instead of key and region.
Next steps
- See the Speech containers overview
- Review configure containers for configuration settings
- Use more Azure AI containers