How to deploy Cohere Command models with Azure AI Studio
Note
Azure AI Studio is currently in public preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
In this article, you learn how to use Azure AI Studio to deploy the Cohere Command models as a service with pay-as you go billing.
Cohere offers two Command models in Azure AI Studio. These models are available with pay-as-you-go token based billing with Models as a Service.
- Cohere Command R
- Cohere Command R+
You can browse the Cohere family of models in the Model Catalog by filtering on the Cohere collection.
Models
In this article, you learn how to use Azure AI Studio to deploy the Cohere models as a service with pay-as-you-go billing.
Cohere Command R
Command R is a highly performant generative large language model, optimized for various use cases including reasoning, summarization, and question answering.
Model Architecture: An auto-regressive language model that uses an optimized transformer architecture. After pretraining, this model uses supervised fine-tuning (SFT) and preference training to align model behavior to human preferences for helpfulness and safety.
Languages covered: The model is optimized to perform well in the following languages: English, French, Spanish, Italian, German, Brazilian Portuguese, Japanese, Korean, Simplified Chinese, and Arabic.
Pre-training data additionally included the following 13 languages: Russian, Polish, Turkish, Vietnamese, Dutch, Czech, Indonesian, Ukrainian, Romanian, Greek, Hindi, Hebrew, Persian.
Context length: Command R supports a context length of 128K.
Input: Models input text only.
Output: Models generate text only.
Cohere Command R+
Command R+ is a highly performant generative large language model, optimized for various use cases including reasoning, summarization, and question answering.
Model Architecture: An auto-regressive language model that uses an optimized transformer architecture. After pretraining, this model uses supervised fine-tuning (SFT) and preference training to align model behavior to human preferences for helpfulness and safety.
Languages covered: The model is optimized to perform well in the following languages: English, French, Spanish, Italian, German, Brazilian Portuguese, Japanese, Korean, Simplified Chinese, and Arabic.
Pre-training data additionally included the following 13 languages: Russian, Polish, Turkish, Vietnamese, Dutch, Czech, Indonesian, Ukrainian, Romanian, Greek, Hindi, Hebrew, Persian.
Context length: Command R+ supports a context length of 128K.
Input: Models input text only.
Output: Models generate text only.
Deploy with pay-as-you-go
Certain models in the model catalog can be deployed as a service with pay-as-you-go, providing a way to consume them as an API without hosting them on your subscription, while keeping the enterprise security and compliance organizations need. This deployment option doesn't require quota from your subscription.
The previously mentioned Cohere models can be deployed as a service with pay-as-you-go, and are offered by Cohere through the Microsoft Azure Marketplace. Cohere can change or update the terms of use and pricing of this model.
Prerequisites
An Azure subscription with a valid payment method. Free or trial Azure subscriptions won't work. If you don't have an Azure subscription, create a paid Azure account to begin.
-
Important
For Cohere family models, the pay-as-you-go model deployment offering is only available with AI hubs created in EastUS2 or Sweden Central region.
An Azure AI project in Azure AI Studio.
Azure role-based access controls (Azure RBAC) are used to grant access to operations in Azure AI Studio. To perform the steps in this article, your user account must be assigned the Azure AI Developer role on the resource group. For more information on permissions, see Role-based access control in Azure AI Studio.
Create a new deployment
To create a deployment:
Sign in to Azure AI Studio.
Select Model catalog from the Explore tab and search for Cohere.
Alternatively, you can initiate a deployment by starting from your project in AI Studio. From the Build tab of your project, select Deployments > + Create.
In the model catalog, on the model's Details page, select Deploy and then Pay-as-you-go.
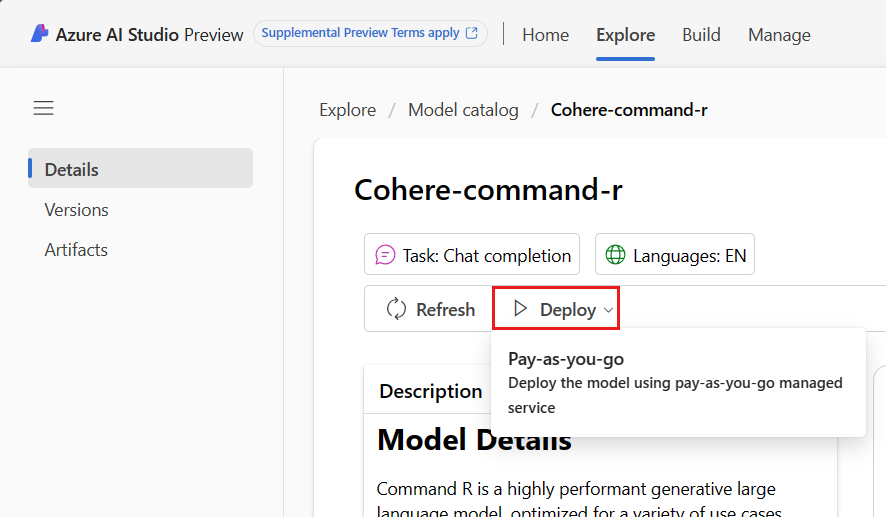
Select the project in which you want to deploy your model. To deploy the model your project must be in the EastUS2 or Sweden Central region.
In the deployment wizard, select the link to Azure Marketplace Terms to learn more about the terms of use.
You can also select the Marketplace offer details tab to learn about pricing for the selected model.
If this is your first time deploying the model in the project, you have to subscribe your project for the particular offering. This step requires that your account has the Azure AI Developer role permissions on the Resource Group, as listed in the prerequisites. Each project has its own subscription to the particular Azure Marketplace offering of the model, which allows you to control and monitor spending. Select Subscribe and Deploy. Currently you can have only one deployment for each model within a project.
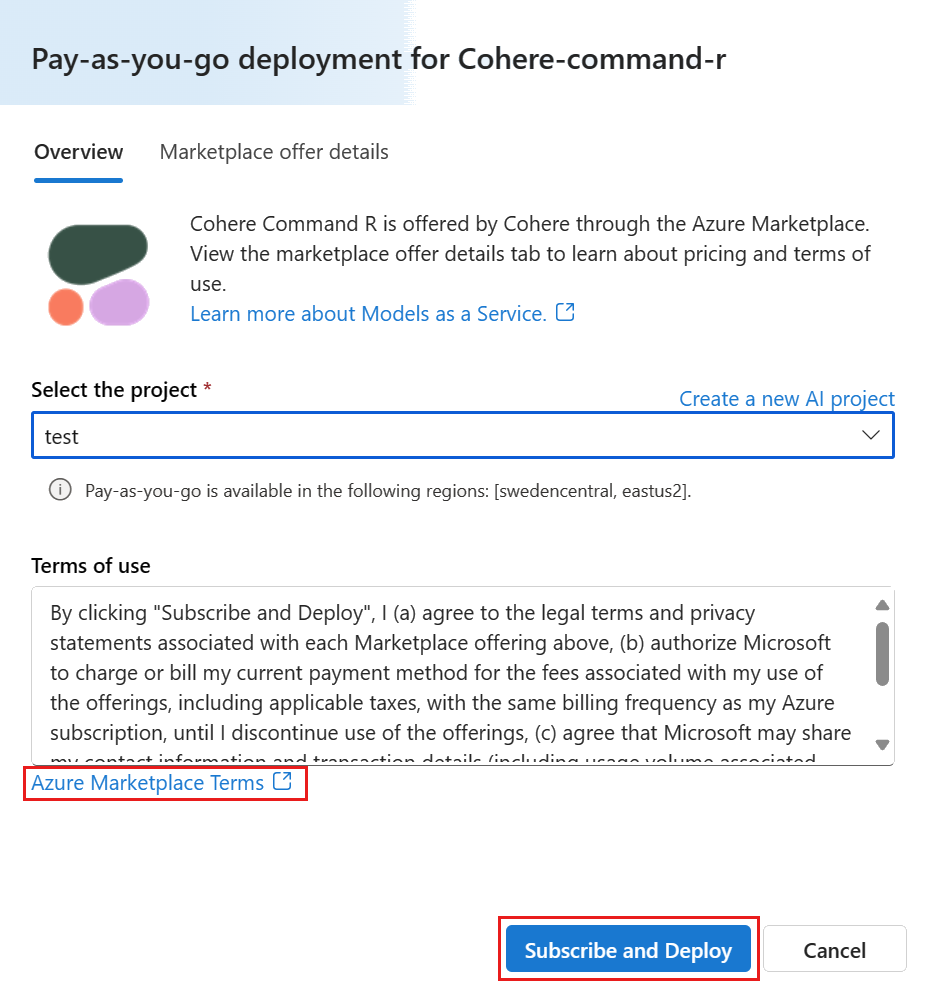
Once you subscribe the project for the particular Azure Marketplace offering, subsequent deployments of the same offering in the same project don't require subscribing again. If this scenario applies to you, there's a Continue to deploy option to select (Currently you can have only one deployment for each model within a project).
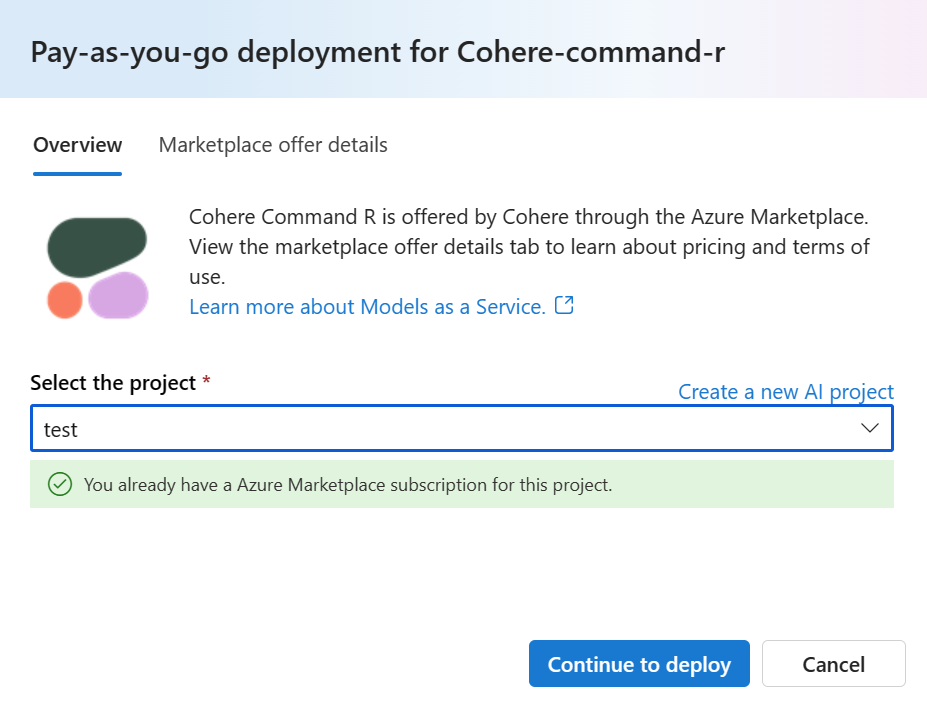
Give the deployment a name. This name becomes part of the deployment API URL. This URL must be unique in each Azure region.
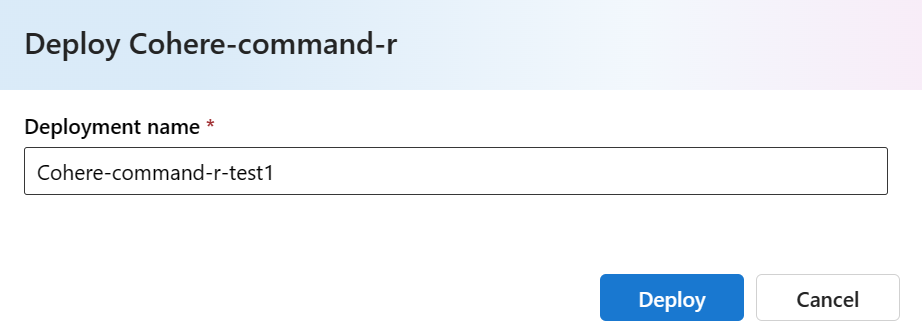
Select Deploy. Wait until the deployment is ready and you're redirected to the Deployments page.
Select Open in playground to start interacting with the model.
You can return to the Deployments page, select the deployment, and note the endpoint's Target URL and the Secret Key. For more information on using the APIs, see the reference section.
You can always find the endpoint's details, URL, and access keys by navigating to the Build tab and selecting Deployments from the Components section.




To learn about billing for the Cohere models deployed with pay-as-you-go, see Cost and quota considerations for Cohere models deployed as a service.
Consume the Cohere models as a service
These models can be consumed using the chat API.
On the Build page, select Deployments.
Find and select the deployment you created.
Copy the Target URL and the Key value.
Cohere exposes two routes for inference with the Command R and Command R+ models.
v1/chat/completionsadheres to the Azure AI Generative Messages API schema, andv1/chatsupports Cohere's native API schema.
For more information on using the APIs, see the reference section.
Chat API reference for Cohere models deployed as a service
v1/chat/completions
Request
POST /v1/chat/completions HTTP/1.1
Host: <DEPLOYMENT_URI>
Authorization: Bearer <TOKEN>
Content-type: application/json
v1/chat/completions request schema
Cohere Command R and Command R+ accept the following parameters for a v1/chat/completions response inference call:
| Property | Type | Default | Description |
|---|---|---|---|
messages |
array |
None |
Text input for the model to respond to. |
max_tokens |
integer |
None |
The maximum number of tokens the model generates as part of the response. Note: Setting a low value might result in incomplete generations. If not specified, generates tokens until end of sequence. |
stop |
array of strings |
None |
The generated text is cut at the end of the earliest occurrence of a stop sequence. The sequence is included in the text. |
stream |
boolean |
False |
When true, the response is a JSON stream of events. The final event contains the complete response, and has an event_type of "stream-end". Streaming is beneficial for user interfaces that render the contents of the response piece by piece, as it gets generated. |
temperature |
float |
0.3 |
Use a lower value to decrease randomness in the response. Randomness can be further maximized by increasing the value of the p parameter. Min value is 0, and max is 2. |
top_p |
float |
0.75 |
Use a lower value to ignore less probable options. Set to 0 or 1.0 to disable. If both p and k are enabled, p acts after k. min value of 0.01, max value of 0.99. |
frequency_penalty |
float |
0 |
Used to reduce repetitiveness of generated tokens. The higher the value, the stronger a penalty is applied to previously present tokens, proportional to how many times they have already appeared in the prompt or prior generation. Min value of 0.0, max value of 1.0. |
presence_penalty |
float |
0 |
Used to reduce repetitiveness of generated tokens. Similar to frequency_penalty, except that this penalty is applied equally to all tokens that have already appeared, regardless of their exact frequencies. Min value of 0.0, max value of 1.0. |
seed |
integer |
None |
If specified, the backend makes a best effort to sample tokens deterministically, such that repeated requests with the same seed and parameters should return the same result. However, determinism can't be guaranteed. |
tools |
list[Tool] |
None |
A list of available tools (functions) that the model might suggest invoking before producing a text response. |
response_format and tool_choice aren't yet supported parameters for the Command R and Command R+ models.
A System or User Message supports the following properties:
| Property | Type | Default | Description |
|---|---|---|---|
role |
enum |
Required | role=system or role=user. |
content |
string |
Required | Text input for the model to respond to. |
An Assistant Message supports the following properties:
| Property | Type | Default | Description |
|---|---|---|---|
role |
enum |
Required | role=assistant |
content |
string |
Required | The contents of the assistant message. |
tool_calls |
array |
None | The tool calls generated by the model, such as function calls. |
A Tool Message supports the following properties:
| Property | Type | Default | Description |
|---|---|---|---|
role |
enum |
Required | role=tool |
content |
string |
Required | The contents of the tool message. |
tool_call_id |
string |
None | Tool call that this message is responding to. |
v1/chat/completions response schema
The response payload is a dictionary with the following fields:
| Key | Type | Description |
|---|---|---|
id |
string |
A unique identifier for the completion. |
choices |
array |
The list of completion choices the model generated for the input messages. |
created |
integer |
The Unix timestamp (in seconds) of when the completion was created. |
model |
string |
The model_id used for completion. |
object |
string |
chat.completion. |
usage |
object |
Usage statistics for the completion request. |
The choices object is a dictionary with the following fields:
| Key | Type | Description |
|---|---|---|
index |
integer |
Choice index. |
messages or delta |
string |
Chat completion result in messages object. When streaming mode is used, delta key is used. |
finish_reason |
string |
The reason the model stopped generating tokens. |
The usage object is a dictionary with the following fields:
| Key | Type | Description |
|---|---|---|
prompt_tokens |
integer |
Number of tokens in the prompt. |
completion_tokens |
integer |
Number of tokens generated in the completion. |
total_tokens |
integer |
Total tokens. |
Examples
Request:
"messages": [
{
"role": "user",
"content": "What is the weather like in Boston?"
},
{
"role": "assistant",
"tool_calls": [
{
"id": "call_ceRrx0tP7bYPTClugKrOgvh4",
"type": "function",
"function": {
"name": "get_current_weather",
"arguments": "{\"location\":\"Boston\"}"
}
}
]
},
{
"role": "tool",
"content": "{\"temperature\":30}",
"tool_call_id": "call_ceRrx0tP7bYPTClugKrOgvh4"
}
]
Response:
{
"id": "df23b9f7-e6bd-493f-9437-443c65d428a1",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "Right now, the weather in Boston is cool, with temperatures of around 30°F. Stay warm!"
}
}
],
"created": 1711734274,
"model": "command-r",
"object": "chat.completion",
"usage": {
"prompt_tokens": 744,
"completion_tokens": 23,
"total_tokens": 767
}
}
v1/chat
Request
POST /v1/chat HTTP/1.1
Host: <DEPLOYMENT_URI>
Authorization: Bearer <TOKEN>
Content-type: application/json
v1/chat request schema
Cohere Command R and Command R+ accept the following parameters for a v1/chat response inference call:
| Key | Type | Default | Description |
|---|---|---|---|
message |
string |
Required | Text input for the model to respond to. |
chat_history |
array of messages |
None |
A list of previous messages between the user and the model, meant to give the model conversational context for responding to the user's message. |
documents |
array |
None |
A list of relevant documents that the model can cite to generate a more accurate reply. Each document is a string-string dictionary. Keys and values from each document are serialized to a string and passed to the model. The resulting generation includes citations that reference some of these documents. Some suggested keys are "text", "author", and "date". For better generation quality, it's recommended to keep the total word count of the strings in the dictionary to under 300 words. An _excludes field (array of strings) can be optionally supplied to omit some key-value pairs from being shown to the model. The omitted fields still show up in the citation object. The "_excludes" field aren't passed to the model. See Document Mode guide from Cohere docs. |
search_queries_only |
boolean |
false |
When true, the response only contains a list of generated search queries, but no search takes place, and no reply from the model to the user's message is generated. |
stream |
boolean |
false |
When true, the response is a JSON stream of events. The final event contains the complete response, and has an event_type of "stream-end". Streaming is beneficial for user interfaces that render the contents of the response piece by piece, as it gets generated. |
max_tokens |
integer |
None | The maximum number of tokens the model generates as part of the response. Note: Setting a low value might result in incomplete generations. If not specified, generates tokens until end of sequence. |
temperature |
float |
0.3 |
Use a lower value to decrease randomness in the response. Randomness can be further maximized by increasing the value of the p parameter. Min value is 0, and max is 2. |
p |
float |
0.75 |
Use a lower value to ignore less probable options. Set to 0 or 1.0 to disable. If both p and k are enabled, p acts after k. min value of 0.01, max value of 0.99. |
k |
float |
0 |
Specify the number of token choices the model uses to generate the next token. If both p and k are enabled, p acts after k. Min value is 0, max value is 500. |
prompt_truncation |
enum string |
OFF |
Accepts AUTO_PRESERVE_ORDER, AUTO, OFF. Dictates how the prompt is constructed. With prompt_truncation set to AUTO_PRESERVE_ORDER, some elements from chat_history and documents are dropped to construct a prompt that fits within the model's context length limit. During this process the order of the documents and chat history are preserved. With prompt_truncation set to "OFF", no elements are dropped. |
stop_sequences |
array of strings |
None |
The generated text is cut at the end of the earliest occurrence of a stop sequence. The sequence is included the text. |
frequency_penalty |
float |
0 |
Used to reduce repetitiveness of generated tokens. The higher the value, the stronger a penalty is applied to previously present tokens, proportional to how many times they have already appeared in the prompt or prior generation. Min value of 0.0, max value of 1.0. |
presence_penalty |
float |
0 |
Used to reduce repetitiveness of generated tokens. Similar to frequency_penalty, except that this penalty is applied equally to all tokens that have already appeared, regardless of their exact frequencies. Min value of 0.0, max value of 1.0. |
seed |
integer |
None |
If specified, the backend makes a best effort to sample tokens deterministically, such that repeated requests with the same seed and parameters should return the same result. However, determinism can't be guaranteed. |
return_prompt |
boolean |
false |
Returns the full prompt that was sent to the model when true. |
tools |
array of objects |
None |
Field is subject to changes. A list of available tools (functions) that the model might suggest invoking before producing a text response. When tools is passed (without tool_results), the text field in the response is "" and the tool_calls field in the response is populated with a list of tool calls that need to be made. If no calls need to be made, the tool_calls array is empty. |
tool_results |
array of objects |
None |
Field is subject to changes. A list of results from invoking tools recommended by the model in the previous chat turn. Results are used to produce a text response and is referenced in citations. When using tool_results, tools must be passed as well. Each tool_result contains information about how it was invoked, and a list of outputs in the form of dictionaries. Cohere's unique fine-grained citation logic requires the output to be a list. In case the output is just one item, for example, {"status": 200}, still wrap it inside a list. |
The chat_history object requires the following fields:
| Key | Type | Description |
|---|---|---|
role |
enum string |
Takes USER, SYSTEM, or CHATBOT. |
message |
string |
Text contents of the message. |
The documents object has the following optional fields:
| Key | Type | Default | Description |
|---|---|---|---|
id |
string |
None |
Can be supplied to identify the document in the citations. This field isn't passed to the model. |
_excludes |
array of strings |
None |
Can be optionally supplied to omit some key-value pairs from being shown to the model. The omitted fields still show up in the citation object. The _excludes field isn't passed to the model. |
v1/chat response schema
Response fields are fully documented on Cohere's Chat API reference. The response object always contains:
| Key | Type | Description |
|---|---|---|
response_id |
string |
Unique identifier for chat completion. |
generation_id |
string |
Unique identifier for chat completion, used with Feedback endpoint on Cohere's platform. |
text |
string |
Model's response to chat message input. |
finish_reason |
enum string |
Why the generation was completed. Can be any of the following values: COMPLETE, ERROR, ERROR_TOXIC, ERROR_LIMIT, USER_CANCEL or MAX_TOKENS |
token_count |
integer |
Count of tokens used. |
meta |
string |
API usage data, including current version and billable tokens. |
Documents
If documents are specified in the request, there are two other fields in the response:
| Key | Type | Description |
|---|---|---|
documents |
array of objects |
Lists the documents that were cited in the response. |
citations |
array of objects |
Specifies which part of the answer was found in a given document. |
citations is an array of objects with the following required fields:
| Key | Type | Description |
|---|---|---|
start |
integer |
The index of text that the citation starts at, counting from zero. For example, a generation of Hello, world! with a citation on world would have a start value of 7. This is because the citation starts at w, which is the seventh character. |
end |
integer |
The index of text that the citation ends after, counting from zero. For example, a generation of Hello, world! with a citation on world would have an end value of 11. This is because the citation ends after d, which is the eleventh character. |
text |
string |
The text of the citation. For example, a generation of Hello, world! with a citation of world would have a text value of world. |
document_ids |
array of strings |
Identifiers of documents cited by this section of the generated reply. |
Tools
If tools are specified and invoked by the model, there's another field in the response:
| Key | Type | Description |
|---|---|---|
tool_calls |
array of objects |
Contains the tool calls generated by the model. Use it to invoke your tools. |
tool_calls is an array of objects with the following fields:
| Key | Type | Description |
|---|---|---|
name |
string |
Name of the tool to call. |
parameters |
object |
The name and value of the parameters to use when invoking a tool. |
Search_queries_only
If search_queries_only=TRUE is specified in the request, there are two other fields in the response:
| Key | Type | Description |
|---|---|---|
is_search_required |
boolean |
Instructs the model to generate a search query. |
search_queries |
array of objects |
Object that contains a list of search queries. |
search_queries is an array of objects with the following fields:
| Key | Type | Description |
|---|---|---|
text |
string |
The text of the search query. |
generation_id |
string |
Unique identifier for the generated search query. Useful for submitting feedback. |
Examples
Chat - Completions
The following example is a sample request call to get chat completions from the Cohere Command model. Use when generating a chat completion.
Request:
{
"chat_history": [
{"role":"USER", "message": "What is an interesting new role in AI if I don't have an ML background"},
{"role":"CHATBOT", "message": "You could explore being a prompt engineer!"}
],
"message": "What are some skills I should have"
}
Response:
{
"response_id": "09613f65-c603-41e6-94b3-a7484571ac30",
"text": "Writing skills are very important for prompt engineering. Some other key skills are:\n- Creativity\n- Awareness of biases\n- Knowledge of how NLP models work\n- Debugging skills\n\nYou can also have some fun with it and try to create some interesting, innovative prompts to train an AI model that can then be used to create various applications.",
"generation_id": "6d31a57f-4d94-4b05-874d-36d0d78c9549",
"finish_reason": "COMPLETE",
"token_count": {
"prompt_tokens": 99,
"response_tokens": 70,
"total_tokens": 169,
"billed_tokens": 151
},
"meta": {
"api_version": {
"version": "1"
},
"billed_units": {
"input_tokens": 81,
"output_tokens": 70
}
}
}
Chat - Grounded generation and RAG capabilities
Command R and Command R+ are trained for RAG via a mixture of supervised fine-tuning and preference fine-tuning, using a specific prompt template. We introduce that prompt template via the documents parameter. The document snippets should be chunks, rather than long documents, typically around 100-400 words per chunk. Document snippets consist of key-value pairs. The keys should be short descriptive strings. The values can be text or semi-structured.
Request:
{
"message": "Where do the tallest penguins live?",
"documents": [
{
"title": "Tall penguins",
"snippet": "Emperor penguins are the tallest."
},
{
"title": "Penguin habitats",
"snippet": "Emperor penguins only live in Antarctica."
}
]
}
Response:
{
"response_id": "d7e72d2e-06c0-469f-8072-a3aa6bd2e3b2",
"text": "Emperor penguins are the tallest species of penguin and they live in Antarctica.",
"generation_id": "b5685d8d-00b4-48f1-b32f-baebabb563d8",
"finish_reason": "COMPLETE",
"token_count": {
"prompt_tokens": 615,
"response_tokens": 15,
"total_tokens": 630,
"billed_tokens": 22
},
"meta": {
"api_version": {
"version": "1"
},
"billed_units": {
"input_tokens": 7,
"output_tokens": 15
}
},
"citations": [
{
"start": 0,
"end": 16,
"text": "Emperor penguins",
"document_ids": [
"doc_0"
]
},
{
"start": 69,
"end": 80,
"text": "Antarctica.",
"document_ids": [
"doc_1"
]
}
],
"documents": [
{
"id": "doc_0",
"snippet": "Emperor penguins are the tallest.",
"title": "Tall penguins"
},
{
"id": "doc_1",
"snippet": "Emperor penguins only live in Antarctica.",
"title": "Penguin habitats"
}
]
}
Chat - Tool Use
If invoking tools or generating a response based on tool results, use the following parameters.
Request:
{
"message":"I'd like 4 apples and a fish please",
"tools":[
{
"name":"personal_shopper",
"description":"Returns items and requested volumes to purchase",
"parameter_definitions":{
"item":{
"description":"the item requested to be purchased, in all caps eg. Bananas should be BANANAS",
"type": "str",
"required": true
},
"quantity":{
"description": "how many of the items should be purchased",
"type": "int",
"required": true
}
}
}
],
"tool_results": [
{
"call": {
"name": "personal_shopper",
"parameters": {
"item": "Apples",
"quantity": 4
},
"generation_id": "cb3a6e8b-6448-4642-b3cd-b1cc08f7360d"
},
"outputs": [
{
"response": "Sale completed"
}
]
},
{
"call": {
"name": "personal_shopper",
"parameters": {
"item": "Fish",
"quantity": 1
},
"generation_id": "cb3a6e8b-6448-4642-b3cd-b1cc08f7360d"
},
"outputs": [
{
"response": "Sale not completed"
}
]
}
]
}
Response:
{
"response_id": "fa634da2-ccd1-4b56-8308-058a35daa100",
"text": "I've completed the sale for 4 apples. \n\nHowever, there was an error regarding the fish; it appears that there is currently no stock.",
"generation_id": "f567e78c-9172-4cfa-beba-ee3c330f781a",
"chat_history": [
{
"message": "I'd like 4 apples and a fish please",
"response_id": "fa634da2-ccd1-4b56-8308-058a35daa100",
"generation_id": "a4c5da95-b370-47a4-9ad3-cbf304749c04",
"role": "User"
},
{
"message": "I've completed the sale for 4 apples. \n\nHowever, there was an error regarding the fish; it appears that there is currently no stock.",
"response_id": "fa634da2-ccd1-4b56-8308-058a35daa100",
"generation_id": "f567e78c-9172-4cfa-beba-ee3c330f781a",
"role": "Chatbot"
}
],
"finish_reason": "COMPLETE",
"token_count": {
"prompt_tokens": 644,
"response_tokens": 31,
"total_tokens": 675,
"billed_tokens": 41
},
"meta": {
"api_version": {
"version": "1"
},
"billed_units": {
"input_tokens": 10,
"output_tokens": 31
}
},
"citations": [
{
"start": 5,
"end": 23,
"text": "completed the sale",
"document_ids": [
""
]
},
{
"start": 113,
"end": 132,
"text": "currently no stock.",
"document_ids": [
""
]
}
],
"documents": [
{
"response": "Sale completed"
}
]
}
Once you run your function and received tool outputs, you can pass them back to the model to generate a response for the user.
Request:
{
"message":"I'd like 4 apples and a fish please",
"tools":[
{
"name":"personal_shopper",
"description":"Returns items and requested volumes to purchase",
"parameter_definitions":{
"item":{
"description":"the item requested to be purchased, in all caps eg. Bananas should be BANANAS",
"type": "str",
"required": true
},
"quantity":{
"description": "how many of the items should be purchased",
"type": "int",
"required": true
}
}
}
],
"tool_results": [
{
"call": {
"name": "personal_shopper",
"parameters": {
"item": "Apples",
"quantity": 4
},
"generation_id": "cb3a6e8b-6448-4642-b3cd-b1cc08f7360d"
},
"outputs": [
{
"response": "Sale completed"
}
]
},
{
"call": {
"name": "personal_shopper",
"parameters": {
"item": "Fish",
"quantity": 1
},
"generation_id": "cb3a6e8b-6448-4642-b3cd-b1cc08f7360d"
},
"outputs": [
{
"response": "Sale not completed"
}
]
}
]
}
Response:
{
"response_id": "fa634da2-ccd1-4b56-8308-058a35daa100",
"text": "I've completed the sale for 4 apples. \n\nHowever, there was an error regarding the fish; it appears that there is currently no stock.",
"generation_id": "f567e78c-9172-4cfa-beba-ee3c330f781a",
"chat_history": [
{
"message": "I'd like 4 apples and a fish please",
"response_id": "fa634da2-ccd1-4b56-8308-058a35daa100",
"generation_id": "a4c5da95-b370-47a4-9ad3-cbf304749c04",
"role": "User"
},
{
"message": "I've completed the sale for 4 apples. \n\nHowever, there was an error regarding the fish; it appears that there is currently no stock.",
"response_id": "fa634da2-ccd1-4b56-8308-058a35daa100",
"generation_id": "f567e78c-9172-4cfa-beba-ee3c330f781a",
"role": "Chatbot"
}
],
"finish_reason": "COMPLETE",
"token_count": {
"prompt_tokens": 644,
"response_tokens": 31,
"total_tokens": 675,
"billed_tokens": 41
},
"meta": {
"api_version": {
"version": "1"
},
"billed_units": {
"input_tokens": 10,
"output_tokens": 31
}
},
"citations": [
{
"start": 5,
"end": 23,
"text": "completed the sale",
"document_ids": [
""
]
},
{
"start": 113,
"end": 132,
"text": "currently no stock.",
"document_ids": [
""
]
}
],
"documents": [
{
"response": "Sale completed"
}
]
}
Chat - Search queries
If you're building a RAG agent, you can also use Cohere's Chat API to get search queries from Command. Specify search_queries_only=TRUE in your request.
Request:
{
"message": "Which lego set has the greatest number of pieces?",
"search_queries_only": true
}
Response:
{
"response_id": "5e795fe5-24b7-47b4-a8bc-b58a68c7c676",
"text": "",
"finish_reason": "COMPLETE",
"meta": {
"api_version": {
"version": "1"
}
},
"is_search_required": true,
"search_queries": [
{
"text": "lego set with most pieces",
"generation_id": "a086696b-ad8e-4d15-92e2-1c57a3526e1c"
}
]
}
More inference examples
| Package | Sample Notebook |
|---|---|
| CLI using CURL and Python web requests - Command R | command-r.ipynb |
| CLI using CURL and Python web requests - Command R+ | command-r-plus.ipynb |
| OpenAI SDK (experimental) | openaisdk.ipynb |
| LangChain | langchain.ipynb |
| Cohere SDK | cohere-sdk.ipynb |
| LiteLLM SDK | litellm.ipynb |
Retrieval Augmented Generation (RAG) and tool use samples
| Description | Package | Sample Notebook |
|---|---|---|
| Create a local Facebook AI similarity search (FAISS) vector index, using Cohere embeddings - Langchain | langchain, langchain_cohere |
cohere_faiss_langchain_embed.ipynb |
| Use Cohere Command R/R+ to answer questions from data in local FAISS vector index - Langchain | langchain, langchain_cohere |
command_faiss_langchain.ipynb |
| Use Cohere Command R/R+ to answer questions from data in AI search vector index - Langchain | langchain, langchain_cohere |
cohere-aisearch-langchain-rag.ipynb |
| Use Cohere Command R/R+ to answer questions from data in AI search vector index - Cohere SDK | cohere, azure_search_documents |
cohere-aisearch-rag.ipynb |
| Command R+ tool/function calling, using LangChain | cohere, langchain, langchain_cohere |
command_tools-langchain.ipynb |
Cost and quotas
Cost and quota considerations for models deployed as a service
Cohere models deployed as a service are offered by Cohere through the Azure Marketplace and integrated with Azure AI Studio for use. You can find the Azure Marketplace pricing when deploying the model.
Each time a project subscribes to a given offer from the Azure Marketplace, a new resource is created to track the costs associated with its consumption. The same resource is used to track costs associated with inference; however, multiple meters are available to track each scenario independently.
For more information on how to track costs, see monitor costs for models offered throughout the Azure Marketplace.
Quota is managed per deployment. Each deployment has a rate limit of 200,000 tokens per minute and 1,000 API requests per minute. However, we currently limit one deployment per model per project. Contact Microsoft Azure Support if the current rate limits aren't sufficient for your scenarios.
Content filtering
Models deployed as a service with pay-as-you-go are protected by Azure AI Content Safety. With Azure AI content safety, both the prompt and completion pass through an ensemble of classification models aimed at detecting and preventing the output of harmful content. The content filtering system detects and takes action on specific categories of potentially harmful content in both input prompts and output completions. Learn more about content filtering here.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for