Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
To thoroughly assess the performance of your generative AI models and applications when applied to a substantial dataset, you can initiate an evaluation process. During this evaluation, your model or application is tested with the given dataset, and its performance will be quantitatively measured with both mathematical based metrics and AI-assisted metrics. This evaluation run provides you with comprehensive insights into the application's capabilities and limitations.
To carry out this evaluation, you can utilize the evaluation functionality in Azure AI Foundry portal, a comprehensive platform that offers tools and features for assessing the performance and safety of your generative AI model. In Azure AI Foundry portal, you're able to log, view, and analyze detailed evaluation metrics.
In this article, you learn to create an evaluation run against model or a test dataset with built-in evaluation metrics from Azure AI Foundry UI. For greater flexibility, you can establish a custom evaluation flow and employ the custom evaluation feature. Alternatively, if your objective is solely to conduct a batch run without any evaluation, you can also utilize the custom evaluation feature.
Prerequisites
To run an evaluation with AI-assisted metrics, you need to have the following ready:
- A test dataset in one of these formats:
csvorjsonl. - An Azure OpenAI connection. A deployment of one of these models: GPT 3.5 models, GPT 4 models, or Davinci models. Required only when you run AI-assisted quality evaluation.
Create an evaluation with built-in evaluation metrics
An evaluation run allows you to generate metric outputs for each data row in your test dataset. You can choose one or more evaluation metrics to assess the output from different aspects. You can create an evaluation run from the evaluation or model catalog pages in Azure AI Foundry portal. Then an evaluation creation wizard appears to guide you through the process of setting up an evaluation run.
From the evaluate page
From the collapsible left menu, select Evaluation > + Create a new evaluation.

From the model catalog page
From the collapsible left menu, select Model catalog > go to specific model > navigate to the benchmark tab > Try with your own data. This opens the model evaluation panel for you to create an evaluation run against your selected model.

Evaluation target
When you start an evaluation from the evaluate page, you need to decide what the evaluation target is first. By specifying the appropriate evaluation target, we can tailor the evaluation to the specific nature of your application, ensuring accurate and relevant metrics. We support two types of evaluation target:
- Fine-tuned model: You want to evaluate the output generated by your selected model and user-defined prompt.
- Dataset: You already have your model generated outputs in a test dataset.

Configure test data
When you enter the evaluation creation wizard, you can select from preexisting datasets or upload a new dataset specifically to evaluate. The test dataset needs to have the model generated outputs to be used for evaluation. A preview of your test data will be shown in the right pane.
Choose existing dataset: You can choose the test dataset from your established dataset collection.
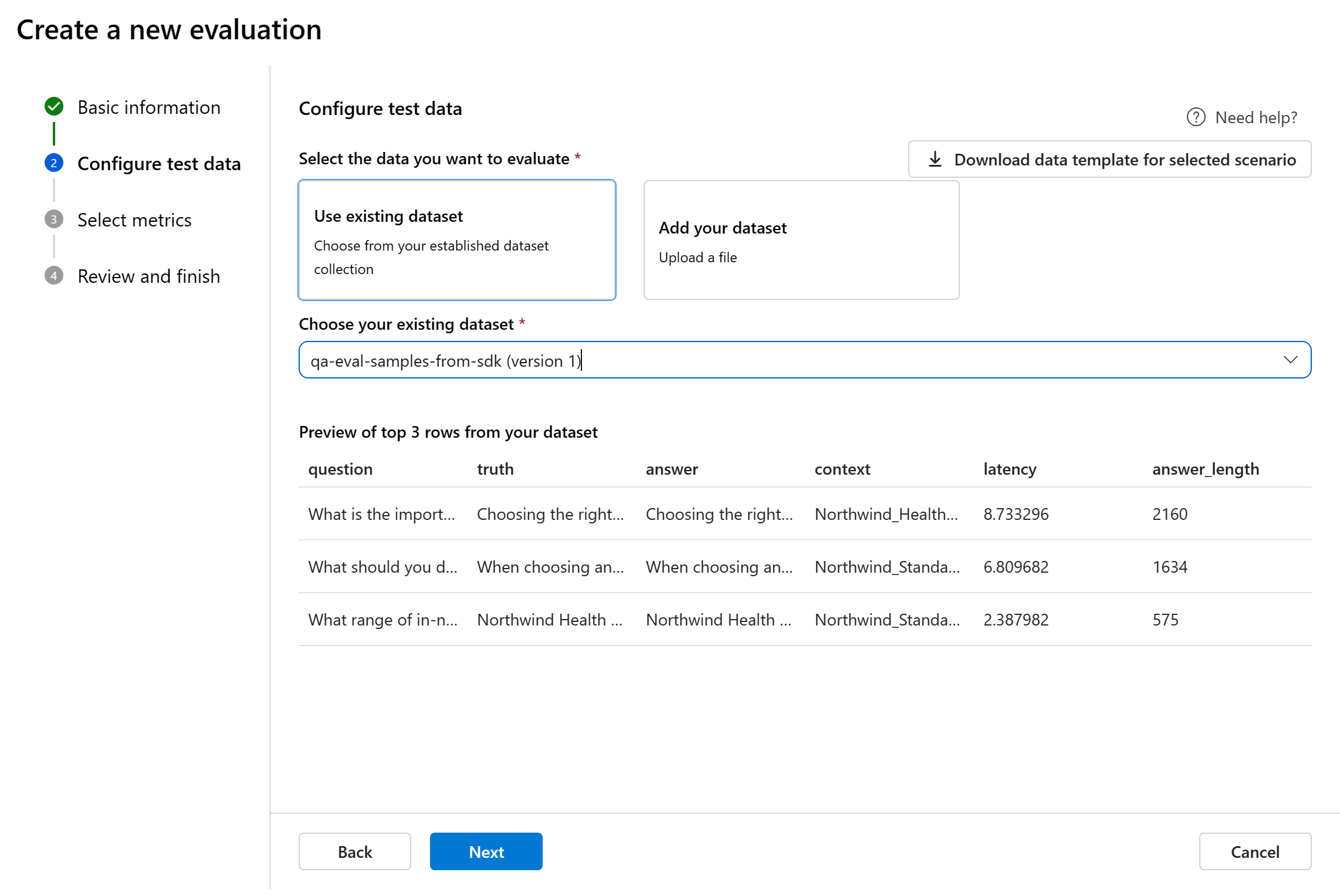
Add new dataset: You can upload files from your local storage. We only support
.csvand.jsonlfile formats. A preview of your test data will be shown in the right pane.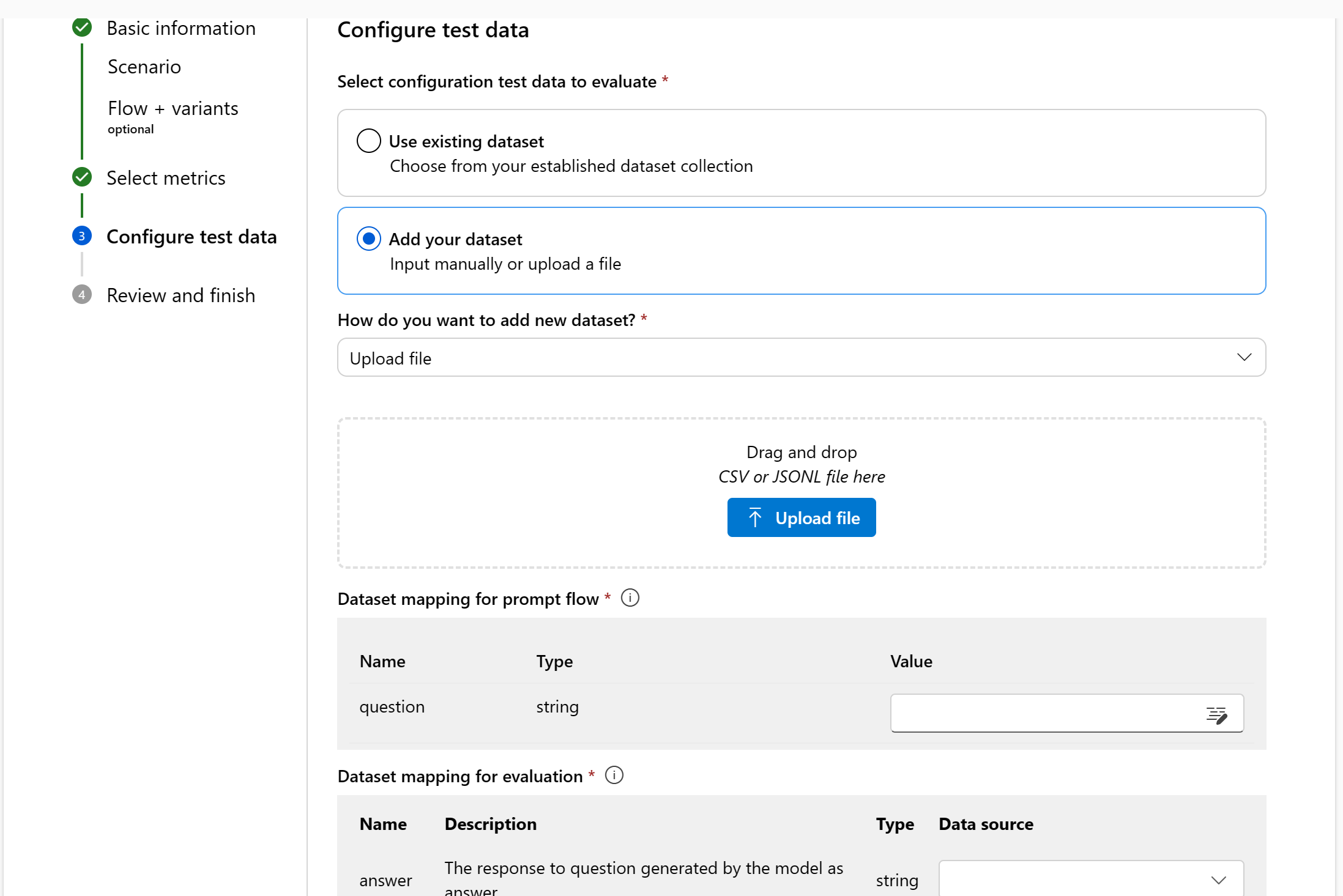


Configure testing criteria
We support three types of metrics curated by Microsoft to facilitate a comprehensive evaluation of your application:
- AI quality (AI assisted): These metrics evaluate the overall quality and coherence of the generated content. To run these metrics, it requires a model deployment as judge.
- AI quality (NLP): These NLP metrics are mathematical based, and they also evaluate the overall quality of the generated content. They often require ground truth data, but they don't require model deployment as judge.
- Risk and safety metrics: These metrics focus on identifying potential content risks and ensuring the safety of the generated content.

As you add your testing criteria, different metrics are going to be used as part of the evaluation. You can refer to the table for the complete list of metrics we offer support for in each scenario. For more in-depth information on each metric definition and how it's calculated, see What are evaluators?.
| AI quality (AI assisted) | AI quality (NLP) | Risk and safety metrics |
|---|---|---|
| Groundedness, Relevance, Coherence, Fluency, GPT similarity | F1 score, ROUGE, score, BLEU score, GLEU score, METEOR score | Self-harm-related content, Hateful and unfair content, Violent content, Sexual content, Protected material, Indirect attack |
When running AI assisted quality evaluation, you must specify a GPT model for the calculation/grading process.

AI Quality (NLP) metrics are mathematically based measurements that assess your application's performance. They often require ground truth data for calculation. ROUGE is a family of metrics. You can select the ROUGE type to calculate the scores. Various types of ROUGE metrics offer ways to evaluate the quality of text generation. ROUGE-N measures the overlap of n-grams between the candidate and reference texts.

For risk and safety metrics, you don't need to provide a deployment. The Azure AI Foundry portal safety evaluations back-end service provisions a GPT-4 model that can generate content risk severity scores and reasoning to enable you to evaluate your application for content harms.

Note
AI-assisted risk and safety metrics are hosted by Azure AI Foundry safety evaluations back-end service and is only available in the following regions: East US 2, France Central, UK South, Sweden Central
Caution
Backward compatibility for Azure OpenAI users who onboarded to Foundry Developer Platform:
Users who previously used oai.azure.com to manage their model deployments and run evaluations and have since onboarded to Foundry Developer Platform (FDP) will have a few limitations when using ai.azure.com:
First, users will be unable to view their evaluations that were created using the Azure OpenAI API. Instead, to view these, users have to navigate back to oai.azure.com.
Second, users will be unable to use the Azure OpenAI API to run evaluations within AI Foundry. Instead, these users should continue to use oai.azure.com for this. However, users can use the Azure OpenAI evaluators that are available directly in AI Foundry (ai.azure.com) in the dataset evaluation creation option. The Fine-tuned model evaluation option isn't supported if the deployment is a migration from Azure OpenAI to Azure Foundry.
For the dataset upload + bring your own storage scenario, a few configurations requirements need to happen:
- Account authentication needs to be Entra ID.
- The storage needs to be added to the account (if it’s added to the project, you'll get service errors).
- User needs to add their project to their storage account through access control in the Azure portal.
To learn more about creating evaluations specifically with OpenAI evaluation graders in Azure OpenAI Hub, see How to use Azure OpenAI in Azure AI Foundry Models evaluation
Data mapping
Data mapping for evaluation: For each metric added, you must specify which data columns in your dataset correspond with inputs needed in the evaluation. Different evaluation metrics demand distinct types of data inputs for accurate calculations.
During evaluation, the model’s response is assessed against key inputs such as:
- Query: required for all metrics
- Context: optional
- Ground Truth: optional, required for AI quality (NLP) metrics
These mappings ensure accurate alignment between your data and the evaluation criteria.

For guidance on the specific data mapping requirements for each metric, refer to the information provided in the table:
Query and response metric requirements
| Metric | Query | Response | Context | Ground truth |
|---|---|---|---|---|
| Groundedness | Required: Str | Required: Str | Required: Str | N/A |
| Coherence | Required: Str | Required: Str | N/A | N/A |
| Fluency | Required: Str | Required: Str | N/A | N/A |
| Relevance | Required: Str | Required: Str | Required: Str | N/A |
| GPT-similarity | Required: Str | Required: Str | N/A | Required: Str |
| F1 score | N/A | Required: Str | N/A | Required: Str |
| BLEU score | N/A | Required: Str | N/A | Required: Str |
| GLEU score | N/A | Required: Str | N/A | Required: Str |
| METEOR score | N/A | Required: Str | N/A | Required: Str |
| ROUGE score | N/A | Required: Str | N/A | Required: Str |
| Self-harm-related content | Required: Str | Required: Str | N/A | N/A |
| Hateful and unfair content | Required: Str | Required: Str | N/A | N/A |
| Violent content | Required: Str | Required: Str | N/A | N/A |
| Sexual content | Required: Str | Required: Str | N/A | N/A |
| Protected material | Required: Str | Required: Str | N/A | N/A |
| Indirect attack | Required: Str | Required: Str | N/A | N/A |
- Query: a query seeking specific information.
- Response: the response to query generated by the model.
- Context: the source that response is generated with respect to (that is, grounding documents)...
- Ground truth: the response to query generated by user/human as the true answer.
Review and finish
After completing all the necessary configurations, you can provide an optional name for your evaluation. Then you can review and proceed to select Submit to submit the evaluation run.

Fine-tuned model evaluation
To create a new evaluation for your selected model deployment, you can use a GPT model to generate sample questions or you can choose from your established dataset collection.

Configure test data for fine-tuned model
Set up the test dataset that is used for evaluation. This dataset is sent to the model to generate responses for assessment. You have two options for configuring your test data:
- Generate sample questions
- Use existing dataset (or upload new dataset)
Generate sample questions
If you don't have a dataset readily available and would like to run an evaluation with a small sample, select the model deployment you want to evaluate based on a chosen topic. We support both Azure OpenAI models and other open models compatible with serverless API deployment, such as Meta LIama and Phi-3 family models. The topic helps tailor the generated content to your area of interest. The queries and responses are generated in real time, and you have the option to regenerate them as needed.

Using your dataset
You can also choose from your established dataset collection or upload a new dataset.

Choose evaluation metrics
After that you can hit next to configure your test criteria. As you select your criteria, metrics are added, and you need to map your dataset’s columns to the required fields for evaluation. These mappings ensure accurate alignment between your data and the evaluation criteria. Once you select the test criteria you want, you can review the evaluation, optionally change the name of the evaluation and then select Submit to submit the evaluation run and go to the evaluation page to see the results.

Note
The generated dataset is saved to the project’s blob storage once the evaluation run is created.
View and manage the evaluators in the evaluator library
The evaluator library is a centralized place that allows you to see the details and status of your evaluators. You can view and manage Microsoft curated evaluators.
The evaluator library also enables version management. You can compare different versions of your work, restore previous versions if needed, and collaborate with others more easily.
To use the evaluator library in Azure AI Foundry portal, go to your project's Evaluation page and select the Evaluator library tab.

You can select the evaluator name to see more details. You can see the name, description, and parameters, and check any files associated with the evaluator. Here are some examples of Microsoft curated evaluators:
- For performance and quality evaluators curated by Microsoft, you can view the annotation prompt on the details page. You can adapt these prompts to your own use case by changing the parameters or criteria according to your data and objectives in the Azure AI Evaluation SDK. For example, you can select Groundedness-Evaluator and check the Prompty file showing how we calculate the metric.
- For risk and safety evaluators curated by Microsoft, you can see the definition of the metrics. For example, you can select the Self-Harm-Related-Content-Evaluator and learn what it means and how Microsoft determines the various severity levels for this safety metric.
Related content
Learn more about how to evaluate your generative AI applications: