Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: AKS on Azure Local
This article describes how to deploy an AI model on AKS enabled by Azure Arc with the Kubernetes AI toolchain operator (KAITO). The AI toolchain operator runs as a cluster extension in AKS enabled by Azure Arc and makes it easier to deploy and run open source LLM models on your AKS enabled by Azure Arc cluster. To enable this feature, follow this workflow:
- Create a cluster with KAITO.
- Add a GPU node pool.
- Model deployment.
- Validate the model with a test prompt.
- Clean up resources.
- Troubleshoot as needed.
Important
The KAITO Extension for AKS enabled by Azure Arc on Azure Local is currently in PREVIEW. See the Supplemental Terms of Use for Microsoft Azure Previews for legal terms that apply to Azure features that are in beta, preview, or otherwise not yet released into general availability.
Prerequisites
Before you begin, make sure you have the following prerequisites:
- Make sure the Azure Local cluster has a supported GPU, such as A2, A16, or T4.
- Make sure the AKS enabled by Azure Arc cluster can deploy GPU node pools with the corresponding GPU VM SKU. For more information, see use GPU for compute-intensive workloads.
- Make sure that kubectl is installed on your local machine. If you need to install kubectl, see Install kubectl.
- Install the aksarc extension, and make sure the version is at least 1.5.37. To get the list of installed CLI extensions, run
az extension list -o table. - If you use a Powershell terminal, make sure the version is at least 7.4.
For all hosted model preset images and default resource configuration, see the KAITO GitHub repository. All the preset models are originally from HuggingFace, and we do not change the model behavior during the redistribution. See the content policy from HuggingFace.
The AI toolchain operator extension currently supports KAITO version 0.4.5. Make a note of this in considering your choice of model from the KAITO model repository.
Create a cluster with KAITO
To create an AKS enabled by Azure Arc cluster on Azure Local with KAITO, follow these steps:
Gather all required parameters and include the
--enable-ai-toolchain-operatorparameter to enable KAITO as part of the cluster creation.az aksarc create --resource-group <Resource_Group_name> --name <Cluster_Name> --custom-location <Custom_Location_Name> --vnet-ids <VNet_ID> --enable-ai-toolchain-operatorAfter the command succeeds, make sure the KAITO extension is installed correctly and the KAITO operator under the
kaitonamespace is in a running state.
Update an existing cluster with KAITO
If you want to enable KAITO on an existing AKS enabled by Azure Arc cluster with a GPU, you can run the following command to install the KAITO operator on the existing node pool:
az aksarc update --resource-group <Resource_Group_name> --name <Cluster_Name> --enable-ai-toolchain-operator
Add a GPU node pool
Before you add a GPU node pool, make sure that Azure Local is enabled with a supported GPU such as A2, T4, or A16, and that the GPU drivers are installed on all the host nodes. To add a GPU node pool, follow these steps:
Sign in to the Azure portal and find your AKS enabled by Azure Arc cluster. Under Settings > Node pools, select Add. Fill in the other required fields, then create the node pool.
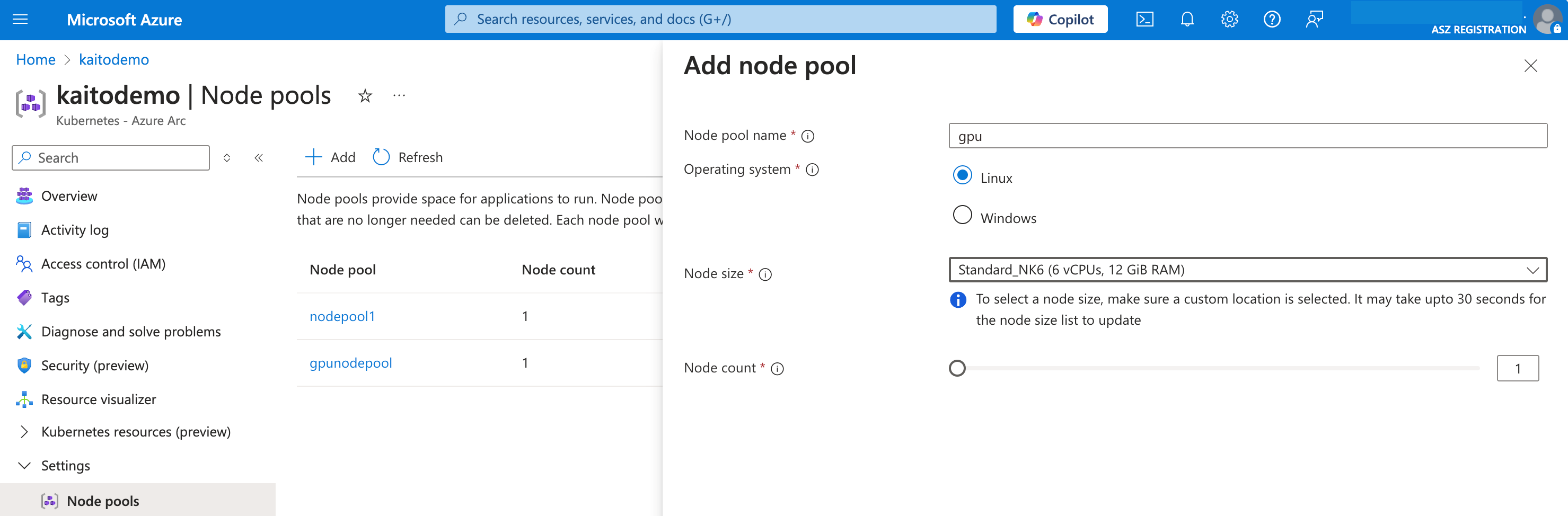

After the node pool is provisioned, you can confirm whether the node is successfully provisioned using the node pool name:
kubectl get nodes --show-labels | grep "msft.microsoft/nodepool-name=.*<Node_Pool_Name>" | awk '{print $1}'For PowerShell, you can use the following command:
kubectl get nodes --show-labels | Select-String "msft.microsoft/nodepool-name=.*<Node_Pool_Name>" | ForEach-Object { ($_ -split '\s+')[0] }Label the newly provisioned GPU node so the inference workspace can be deployed to the node in the next step. You can make sure the label is applied using
kubectl get nodes.kubectl label node moc-l36c6vu97d5 apps=llm-inference
Model deployment
To deploy the AI model, follow these steps:
Create a YAML file with the following sample file. In this example, we use the Phi 3.5 Mini model by specifying the preset name as phi-3.5-mini-instruct. If you want to use other LLMs, use the preset name from the KAITO repo. You should also make sure that the LLM can deploy on the VM SKU based on the matrix table in the "Model VM SKU Matrix" section.
apiVersion: kaito.sh/v1beta1 kind: Workspace metadata: name: workspace-llm resource: instanceType: <GPU_VM_SKU> # Update this value with GPU VM SKU labelSelector: matchLabels: apps: llm-inference preferredNodes: - moc-l36c6vu97d5 # Update the value with GPU VM name inference: preset: name: phi-3.5-mini-instruct # Update preset name as needed config: "ds-inference-params" --- apiVersion: v1 kind: ConfigMap metadata: name: ds-inference-params data: inference_config.yaml: | max_probe_steps: 6 # Maximum number of steps to find the max available seq len fitting in the GPU memory. vllm: cpu-offload-gb: 0 swap-space: 4 gpu-memory-utilization: 0.9 max-model-len: 4096Apply the YAML and wait until the deployment completes. Make sure that internet connectivity is good so that the model can be downloaded from the Hugging Face website within a few minutes. When the inference workspace is successfully provisioned, both ResourceReady and InferenceReady become True. See the "Troubleshooting" section if you encounter any failures in the workspace deployment.
kubectl apply -f sampleyamlfile.yamlValidate that the workspace deployment succeeded:
kubectl get workspace -A
Validate the model with a test prompt
After the resource and inference states become ready, the inference service is exposed internally via a Cluster IP. You can test the model with the following prompt:
export CLUSTERIP=$(kubectl get svc workspace-llm -o jsonpath="{.spec.clusterIPs[0]}")
kubectl run -it --rm --restart=Never curl --image=curlimages/curl -- curl -X POST http://$CLUSTERIP/v1/completions
-H "Content-Type: application/json"
-d '{
"model": "phi-3.5-mini-instruct",
"prompt": "What is kubernetes?",
"max_tokens": 20,
"temperature": 0
}'
$CLUSTERIP = $(kubectl get svc workspace-llm -o jsonpath="{.spec.clusterIPs[0]}" )
$jsonContent = '{"model":"phi-3.5-mini-instruct","prompt":"What is kubernetes","max_tokens":200,"temperature":0}' | ConvertTo-Json
kubectl run -it --rm --restart=Never curl --image=curlimages/curl -- curl -X POST http://$CLUSTERIP/v1/completions -H "accept: application/json" -H "Content-Type: application/json" -d $jsonContent
Clean up resources
To clean up the resources, remove both the inference workspace and the extension:
kubectl delete workspace workspace-llm
az aksarc update --resource-group <Resource_Group_name> --name <Cluster_Name> --disable-ai-toolchain-operator
Model VM SKU Matrix
The following table shows the supported GPU models and their corresponding VM SKUs. The GPU model is used to determine the VM SKU when you create a node pool. For more information about the GPU models, see Supported GPU models.
| Type | T4 | A2 or A16 | A2 or A16 |
|---|---|---|---|
| Model VM SKU Matrix | Standard_NK6 | Standard_NC4, Standard_NC8 | Standard_NC32, Standard_NC16 |
| phi-3-mini-4k-instruct | Y | Y | Y |
| phi-3-mini-128k-instruct | N | Y | Y |
| phi-3.5-mini-instruct | N | Y | Y |
| phi-4-mini-instruct | N | N | Y |
| mistral-7b/mistral-7b-instruct | N | N | Y |
| qwen2.5-coder-7b-instruct | N | N | Y |
Troubleshooting
- If you want to deploy an LLM and see the error OutOfMemoryError: CUDA out of memory, please raise an issue in the KAITO repo.
- If you see the error (ExtensionOperationFailed) The extension operation failed with the following error: Unable to get a response from the Agent in time during extension installation, see this TSG and ensure the extension agent in the AKS enabled by Azure Arc cluster can connect to Azure.
- If you see an error during prompt testing such as {"detail":[{"type":"json_invalid","loc":["body",1],"msg":"JSON decode error","input":{},"ctx":{"error":"Expecting property name enclosed in double quotes"}}]}, it's possible that your PowerShell terminal version is 5.1. Make sure the terminal version is at least 7.4.
Next steps
- Monitor the inference metrics in Managed Prometheus and Managed Grafana
- For more information about KAITO, see KAITO GitHub Repo