Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
The ingress-nginx controller in the application routing add-on exposes many metrics for requests, the nginx process, and the controller that can be helpful in analyzing the performance and usage of your application.
The application routing add-on exposes the Prometheus metrics endpoint at /metrics on port 10254 and a private Service nginx-metrics.
Prerequisites
- An Azure Kubernetes Service (AKS) cluster with the application routing add-on enabled.
- A Prometheus instance, such as Azure Monitor managed service for Prometheus.
Validating the metrics endpoint
To validate the metrics are being collected, you can set up a port forward from a local port to port 10254 on the nginx-metrics service.
kubectl port-forward -n app-routing-system service/nginx-metrics :10254
Forwarding from 127.0.0.1:43307 -> 10254
Forwarding from [::1]:43307 -> 10254
Note the local port (43307 in this case) and open http://localhost:43307/metrics in your browser. You should see the ingress-nginx controller metrics loading.
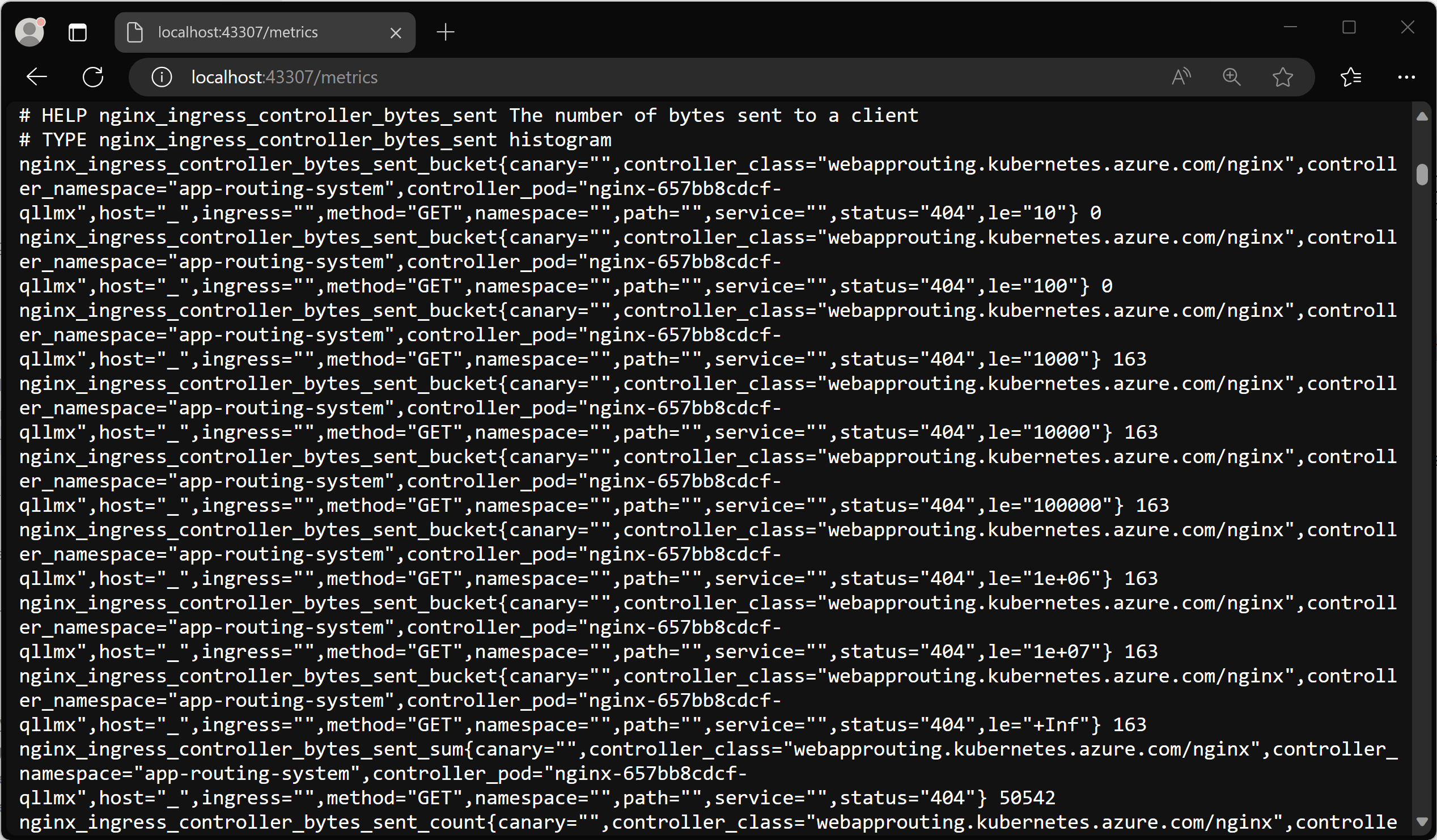
You can now terminate the port-forward process to close the forwarding.
Configuring Azure Monitor managed service for Prometheus
Azure Monitor managed service for Prometheus is a fully managed Prometheus-compatible service that supports industry standard features such as PromQL, Grafana dashboards, and Prometheus alerts. This service requires configuring the metrics addon for the Azure Monitor agent, which sends data to Prometheus. If your cluster isn't configured with the add-on, you can follow this article to configure your Azure Kubernetes Service (AKS) cluster to send data to Azure Monitor managed service for Prometheus.
Enable Service Monitor based scraping
Once your cluster is updated with the Azure Monitor agent, you need to configure the agent to enable scraping the metrics endpoint. You can create a Pod or a Service Monitor to accomplish this.
The following creates a Service Monitor scrape metrics from the ingress-nginx controller deployed by the application routing add-on.
kubectl apply -f - <<EOF
apiVersion: azmonitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: nginx-monitor
namespace: app-routing-system
spec:
labelLimit: 63
labelNameLengthLimit: 511
labelValueLengthLimit: 1023
selector:
matchLabels:
app.kubernetes.io/component: ingress-controller
app.kubernetes.io/managed-by: aks-app-routing-operator
app.kubernetes.io/name: nginx
endpoints:
- port: prometheus
EOF
In a few minutes, the ama-metrics pods in the kube-system namespace should restart and pick up the new configuration.
Review visualization of metrics in Azure Managed Grafana
Now that you have Azure Monitor managed service for Prometheus and Azure Managed Grafana configured, you should access your Managed Grafana instance.
There are two official ingress-nginx dashboards dashboards that you can download and import into your Grafana instance:
- Ingress-nginx controller dashboard
- Request handling performance dashboard
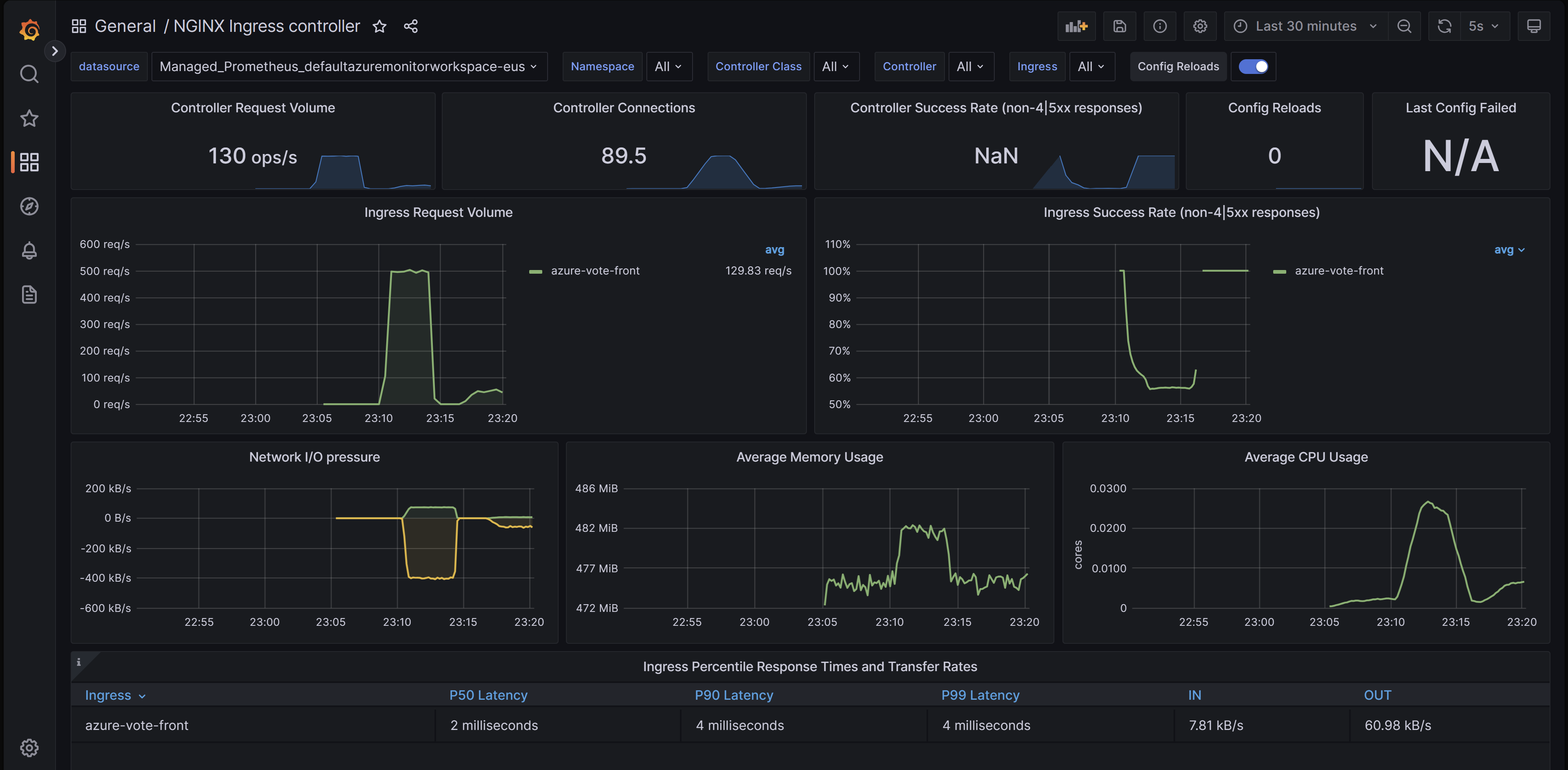
Ingress-nginx controller dashboard
This dashboard gives you visibility of request volume, connections, success rates, config reloads and configs out of sync. You can also use it to view the network IO pressure, memory and CPU use of the ingress controller. Finally, it also shows the P50, P95, and P99 percentile response times of your ingresses and their throughput.
You can download this dashboard from GitHub.
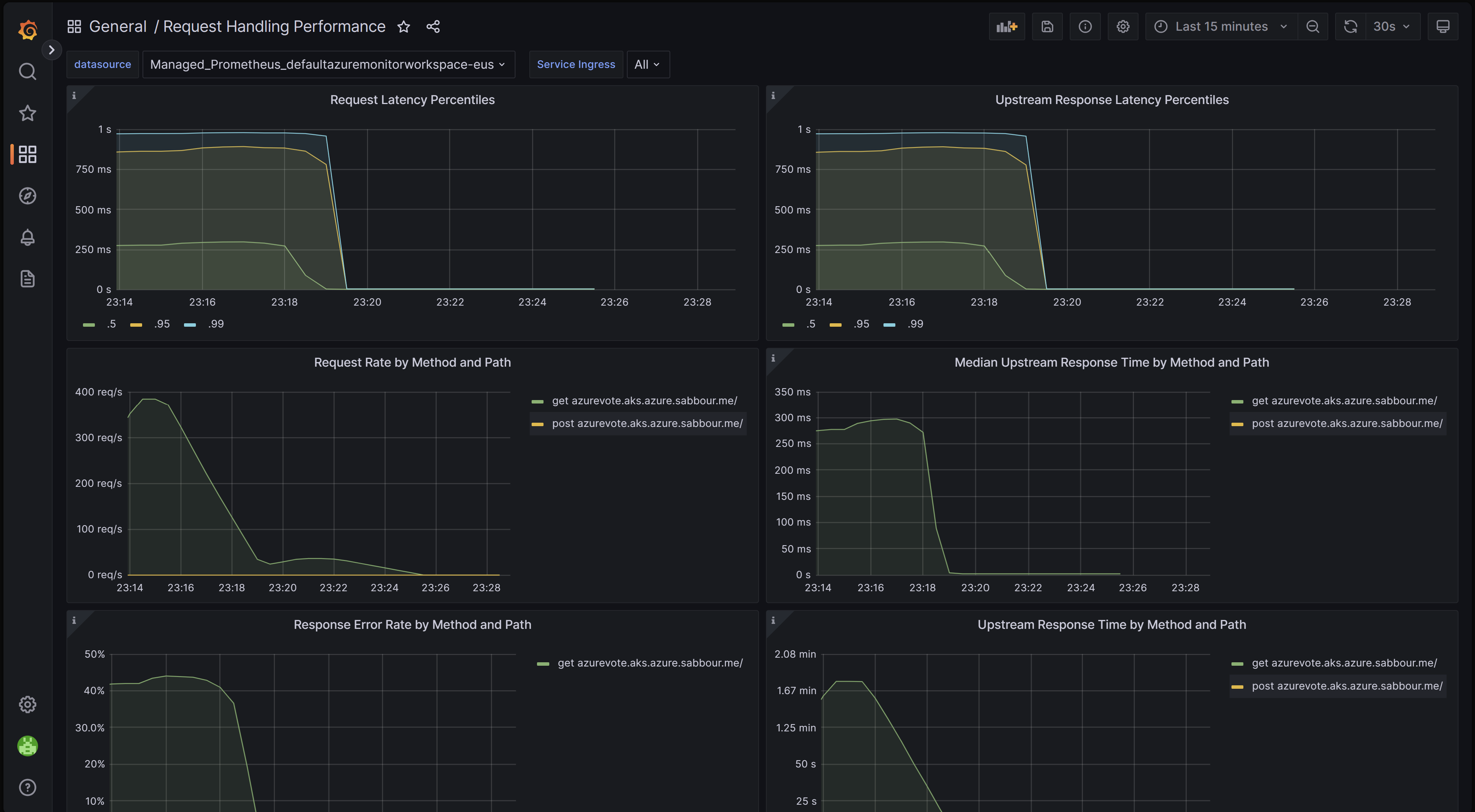
Request handling performance dashboard
This dashboard gives you visibility into the request handling performance of the different ingress upstream destinations, which are your applications' endpoints that the ingress controller is forwarding traffic to. It shows the P50, P95 and P99 percentile of total request and upstream response times. You can also view aggregates of request errors and latency. Use this dashboard to review and improve the performance and scalability of your applications.
You can download this dashboard from GitHub.
Importing a dashboard
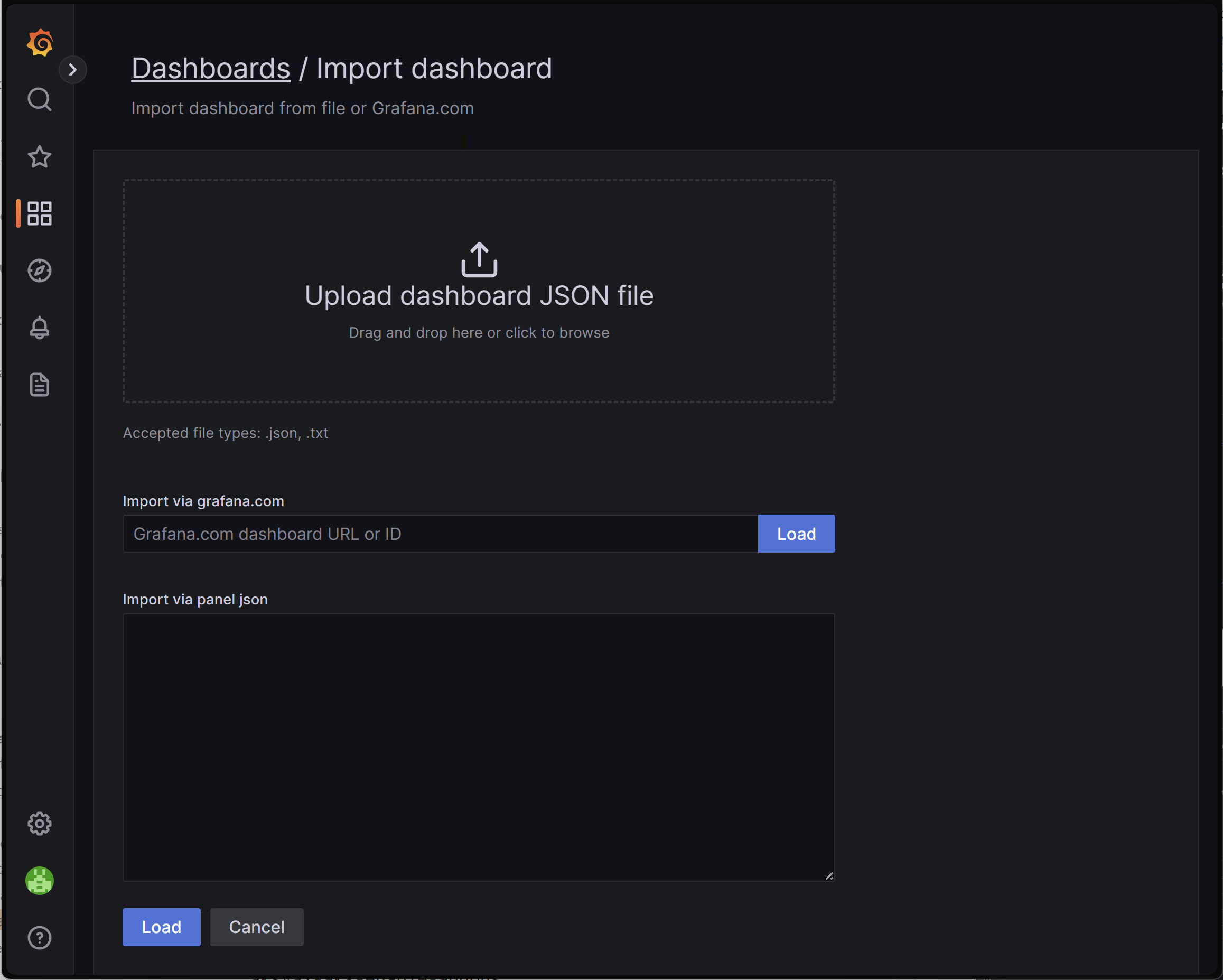
To import a Grafana dashboard, expand the left menu and click on Import under Dashboards.
Then upload the desired dashboard file and click on Load.
Next steps
- You can configure scaling your workloads using ingress metrics scraped with Prometheus using Kubernetes Event Driven Autoscaler (KEDA). Learn more about integrating KEDA with AKS.
- Create and run a load test with Azure Load Testing to test workload performance and optimize the scalability of your applications.