Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This guide shows how to perform document summarization by using the Azure OpenAI GPT-3 model. It describes concepts that are related to the document summarization process, approaches to the process, and recommendations on which model to use for specific use cases. Finally, it presents two use cases, together with sample code snippets, to help you understand key concepts.
Architecture
The following diagram shows how a user query fetches relevant data. The summarizer uses GPT-3 to generate a summary of the text of the most relevant document. In this architecture, the GPT-3 endpoint is used to summarize the text.

Download a PowerPoint file of this architecture.
Workflow
This workflow occurs in near-real time.
- A user sends a query. For example, an employee of a manufacturing company searches for specific information about a machine part on the company portal. The query is first processed by an intent recognizer like Conversational language understanding. The relevant entities or concepts in the user query are used to select and present a subset of documents from a knowledge base that's populated offline (in this case, the company's knowledge base database). The output is fed into a search and analysis engine like Azure Elastic Search, which filters the relevant documents to return a document set of hundreds instead of thousands or tens of thousands.
- The user query is applied again on a search endpoint like Azure Cognitive Search to rank the retrieved document set in order of relevance (page ranking). The highest-ranked document is selected.
- The selected document is scanned for relevant sentences. This scanning process uses either a coarse method, like extracting all sentences that contain the user query, or a more sophisticated method, like GPT-3 embeddings, to find semantically similar material in the document.
- After the relevant text is extracted, the GPT-3 Completions endpoint with the summarizer summarizes the extracted content. In this example, the summary of important details about the part that the employee specified in the query is returned.
This article focuses on the summarizer component of the architecture.
Scenario details
Enterprises frequently create and maintain a knowledge base about business processes, customers, products, and information. However, returning relevant content based on a user query of a large dataset is often challenging. The user can query the knowledge base and find an applicable document by using methods like page rank, but delving further into the document to search for relevant information typically becomes a manual task that takes time. However, with recent advances in foundation transformer models like the one developed by OpenAI, the query mechanism has been refined by semantic search methods that use encoding information like embeddings to find relevant information. These developments enable the ability to summarize content and present it to the user in a concise and succinct way.
Document summarization is the process of creating summaries from large volumes of data while maintaining significant informational elements and content value. This article demonstrates how to use Azure OpenAI Service GPT-3 capabilities for your specific use case. GPT-3 is a powerful tool that you can use for a range of natural language processing tasks, including language translation, chatbots, text summarization, and content creation. The methods and architecture described here are customizable and can be applied to many datasets.
Potential use cases
Document summarization applies to any organizational domain that requires users to search large amounts of reference data and generate a summary that concisely describes relevant information. Typical domains include legal, financial, news, healthcare, and academic organizations. Potential use cases of summarization are:
- Generating summaries to highlight key insights about news, financial reporting, and so on.
- Creating a quick reference to support an argument, for example, in legal proceedings.
- Providing context for a paper's thesis, as in academic settings.
- Writing literature reviews.
- Annotating a bibliography.
Some benefits of using a summarization service for any use case are:
- Reduced reading time.
- More effective searching of large volumes of disparate data.
- Reduced chance of bias from human summarization techniques. (This benefit depends on how unbiased the training data is.)
- Enabling employees and users to focus on more in-depth analysis.
In-context learning
Azure OpenAI Service uses a generative completion model. The model uses natural language instructions to identify the requested task and the skill required, a process known as prompt engineering. When you use this approach, the first part of the prompt includes natural language instructions or examples of the desired task. The model completes the task by predicting the most probable next text. This technique is known as in-context learning.
With in-context learning, language models can learn tasks from just a few examples. The language model is provided with a prompt that contains a list of input-output pairs that demonstrate a task, and then with a test input. The model makes a prediction by conditioning on the prompt and predicting the next tokens.
There are three main approaches to in-context learning: zero-shot learning, few-shot learning, and fine-tuning methods that change and improve the output. These approaches vary based on the amount of task-specific data that's provided to the model.
Zero-shot: In this approach, no examples are provided to the model. Only the task request is provided as input. In zero-shot learning, the model depends on previously trained concepts. It responds based only on data that it's trained on. It doesn't necessarily understand the semantic meaning, but it has a statistic understanding that's based on everything that it's learned from the internet about what should be generated next. The model attempts to relate the given task to existing categories that it has already learned about and responds accordingly.
Few-shot: In this approach, several examples that demonstrate the expected answer format and content are included in the call prompt. The model is provided with a very small training dataset to guide its predictions. Training with a small set of examples enables the model to generalize and understand unrelated but previously unseen tasks. Creating few-shot examples can be challenging because you need to accurately articulate the task that you want the model to perform. One commonly observed problem is that models are sensitive to the writing style that's used in the training examples, especially small models.
Fine-tuning: Fine-tuning is a process of tailoring models to your own datasets. In this customization step, you can improve the process by:
- Including a larger set of data (at least 500 examples).
- Using traditional optimization techniques with backpropagation to readjust the weights of the model. These techniques enable higher quality results than the zero-shot or few-shot approaches provide by themselves.
- Improving the few-shot approach by training the model weights with specific prompts and a specific structure. This technique enables you to achieve better results on a wider number of tasks without needing to provide examples in the prompt. The result is less text sent and fewer tokens.
When you create a GPT-3 solution, the main effort is in the design and content of the training prompt.
Prompt engineering
Prompt engineering is a natural language processing discipline that involves discovering inputs that yield desirable or useful outputs. When a user prompts the system, the way the content is expressed can dramatically change the output. Prompt design is the most significant process for ensuring that the GPT-3 model provides a desirable and contextual response.
The architecture described in this article uses the completions endpoint for summarization. The completions endpoint is an Azure AI services API that accepts a partial prompt or context as input and returns one or more outputs that continue or complete the input text. A user provides input text as a prompt, and the model generates text that attempts to match the context or pattern that's provided. Prompt design is highly dependent on the task and data. Incorporating prompt engineering into a fine-tuning dataset and investigating what works best before using the system in production requires significant time and effort.
Prompt design
GPT-3 models can perform multiple tasks, so you need to be explicit in the goals of the design. The models estimate the desired output based on the provided prompt.
For example, if you input the words "Give me a list of cat breeds," the model doesn't automatically assume that you're asking for a list of cat breeds. You could be asking the model to continue a conversation in which the first words are "Give me a list of cat breeds" and the next ones are "and I'll tell you which ones I like." If the model just assumed that you wanted a list of cats, it wouldn't be as good at content creation, classification, or other tasks.
As described in Learn how to generate or manipulate text, there are three basic guidelines for creating prompts:
- Show and tell. Improve the clarity about what you want by providing instructions, examples, or a combination of the two. If you want the model to rank a list of items in alphabetical order or to classify a paragraph by sentiment, show it that that's what you want.
- Provide quality data. If you're building a classifier or want a model to follow a pattern, be sure to provide enough examples. You should also proofread your examples. The model can usually recognize spelling mistakes and return a response, but it might assume misspellings are intentional, which can affect the response.
- Check your settings. The
temperatureandtop_psettings control how deterministic the model is in generating a response. If you ask it for a response that has only one right answer, configure these settings at a lower level. If you want more diverse responses, you might want to configure the settings at a higher level. A common error is to assume that these settings are "cleverness" or "creativity" controls.
Alternatives
Azure conversational language understanding is an alternative to the summarizer used here. The main purpose of conversational language understanding is to build models that predict the overall intention of an incoming utterance, extract valuable information from it, and produce a response that aligns with the topic. It's useful in chatbot applications when it can refer to an existing knowledge base to find the suggestion that best corresponds to the incoming utterance. It doesn't help much when the input text doesn't require a response. The intent in this architecture is to generate a short summary of long textual content. The essence of the content is described in a concise manner and all important information is represented.
Example scenarios
Use case: Summarizing legal documents
In this use case, a collection of legislative bills passed through Congress is summarized. The summary is fine-tuned to bring it closer to a human-generated summary, which is referred to as the ground truth summary.
Zero-shot prompt engineering is used to summarize the bills. The prompt and settings are then modified to generate different summary outputs.
Dataset
The first dataset is the BillSum dataset for summarization of US Congressional and California state bills. This example uses only the Congressional bills. The data is split into 18,949 bills to use for training and 3,269 bills to use for testing. BillSum focuses on mid-length legislation that's between 5,000 and 20,000 characters long. It's cleaned and preprocessed.
For more information about the dataset and instructions for download, see FiscalNote/BillSum on GitHub.
BillSum schema
The schema of the BillSum dataset includes:
bill_id. An identifier for the bill.text. The bill text.summary. A human-written summary of the bill.title. The bill title.text_len. The character length of the bill.sum_len. The character length of the bill summary.
In this use case, the text and summary elements are used.
Zero-shot
The goal here is to teach the GPT-3 model to learn conversation-style input. The completions endpoint is used to create an Azure OpenAI API and a prompt that generates the best summary of the bill. It's important to create the prompts carefully so that they extract relevant information. To extract general summaries from a given bill, the following format is used.
- Prefix: What you want it to do.
- Context primer: The context.
- Context: The information needed to provide a response. In this case, the text to summarize.
- Suffix: The intended form of the answer. For example, an answer, a completion, or a summary.
API_KEY = # SET YOUR OWN API KEY HERE
RESOURCE_ENDPOINT = " -- # SET A LINK TO YOUR RESOURCE ENDPOINT -- "
openai.api_type = "azure"
openai.api_key = API_KEY
openai.api_base = RESOURCE_ENDPOINT
openai.api_version = "2022-12-01-preview"
prompt_i = 'Summarize the legislative bill given the title and the text.\n\nTitle:\n'+" ".join([normalize_text(bill_title_1)])+ '\n\nText:\n'+ " ".join([normalize_text(bill_text_1)])+'\n\nSummary:\n'
response = openai.Completion.create(
engine=TEXT_DAVINCI_001
prompt=prompt_i,
temperature=0.4,
max_tokens=500,
top_p=1.0,
frequency_penalty=0.5,
presence_penalty=0.5,
stop=['\n\n###\n\n'], # The ending token used during inference. Once it reaches this token, GPT-3 knows the completion is over.
best_of=1
)
= 1
Ground truth: National Science Education Tax Incentive for Businesses Act of 2007 - Amends the Internal Revenue Code to allow a general business tax credit for contributions of property or services to elementary and secondary schools and for teacher training to promote instruction in science, technology, engineering, or mathematics.
Zero-shot model summary: The National Science Education Tax Incentive for Businesses Act of 2007 would create a new tax credit for businesses that make contributions to science, technology, engineering, and mathematics (STEM) education at the elementary and secondary school level. The credit would be equal to 100 percent of the qualified STEM contributions of the taxpayer for the taxable year. Qualified STEM contributions would include STEM school contributions, STEM teacher externship expenses, and STEM teacher training expenses.
Observations: The zero-shot model generates a succinct, generalized summary of the document. It's similar to the human-written ground truth and captures the same key points. It's organized like a human-written summary and remains focused on the point.
Fine-tuning
Fine-tuning improves upon zero-shot learning by training on more examples than you can include in the prompt, so you achieve better results on a wider number of tasks. After a model is fine-tuned, you don't need to provide examples in the prompt. Fine-tuning saves money by reducing the number of tokens required and enables lower-latency requests.
At a high level, fine-tuning includes these steps:
- Prepare and upload training data.
- Train a new fine-tuned model.
- Use the fine-tuned model.
For more information, see How to customize a model with Azure OpenAI Service.
Prepare data for fine-tuning
This step enables you to improve upon the zero-shot model by incorporating prompt engineering into the prompts that are used for fine-tuning. Doing so helps give directions to the model on how to approach the prompt/completion pairs. In a fine-tune model, prompts provide a starting point that the model can learn from and use to make predictions. This process enables the model to start with a basic understanding of the data, which can then be improved upon gradually as the model is exposed to more data. Additionally, prompts can help the model to identify patterns in the data that it might otherwise miss.
The same prompt engineering structure is also used during inference, after the model is finished training, so that the model recognizes the behavior that it learned during training and can generate completions as instructed.
#Adding variables used to design prompts consistently across all examples
#You can learn more here: https://learn.microsoft.com/azure/cognitive-services/openai/how-to/prepare-dataset
LINE_SEP = " \n "
PROMPT_END = " [end] "
#Injecting the zero-shot prompt into the fine-tune dataset
def stage_examples(proc_df):
proc_df['prompt'] = proc_df.apply(lambda x:"Summarize the legislative bill. Do not make up facts.\n\nText:\n"+" ".join([normalize_text(x['prompt'])])+'\n\nSummary:', axis=1)
proc_df['completion'] = proc_df.apply(lambda x:" "+normalize_text(x['completion'])+PROMPT_END, axis=1)
return proc_df
df_staged_full_train = stage_examples(df_prompt_completion_train)
df_staged_full_val = stage_examples(df_prompt_completion_val)
Now that the data is staged for fine-tuning in the proper format, you can start running the fine-tune commands.
Next, you can use the OpenAI CLI to help with some of the data preparation steps. The OpenAI tool validates data, provides suggestions, and reformats data.
openai tools fine_tunes.prepare_data -f data/billsum_v4_1/prompt_completion_staged_train.csv
openai tools fine_tunes.prepare_data -f data/billsum_v4_1/prompt_completion_staged_val.csv
Fine-tune the dataset
payload = {
"model": "curie",
"training_file": " -- INSERT TRAINING FILE ID -- ",
"validation_file": "-- INSERT VALIDATION FILE ID --",
"hyperparams": {
"n_epochs": 1,
"batch_size": 200,
"learning_rate_multiplier": 0.1,
"prompt_loss_weight": 0.0001
}
}
url = RESOURCE_ENDPOINT + "openai/fine-tunes?api-version=2022-12-01-preview"
r = requests.post(url,
headers={
"api-key": API_KEY,
"Content-Type": "application/json"
},
json = payload
)
data = r.json()
print(data)
fine_tune_id = data['id']
print('Endpoint Called: {endpoint}'.format(endpoint = url))
print('Status Code: {status}'.format(status= r.status_code))
print('Fine tuning job ID: {id}'.format(id=fine_tune_id))
print('Response Information \n\n {text}'.format(text=r.text))
Evaluate the fine-tuned model
This section demonstrates how to evaluate the fine-tuned model.
#Run this cell to check status
url = RESOURCE_ENDPOINT + "openai/fine-tunes/<--insert fine-tune id-->?api-version=2022-12-01-preview"
r = requests.get(url,
headers={
"api-key": API_KEY,
"Content-Type": "application/json"
}
)
data = r.json()
print('Endpoint Called: {endpoint}'.format(endpoint = url))
print('Status Code: {status}'.format(status= r.status_code))
print('Fine tuning ID: {id}'.format(id=fine_tune_id))
print('Status: {status}'.format(status = data['status']))
print('Response Information \n\n {text}'.format(text=r.text))
Ground truth: National Science Education Tax Incentive for Businesses Act of 2007 - Amends the Internal Revenue Code to allow a general business tax credit for contributions of property or services to elementary and secondary schools and for teacher training to promote instruction in science, technology, engineering, or mathematics.
Fine-tuned model summary: This bill provides a tax credit for contributions to elementary and secondary schools that benefit science, technology, engineering, and mathematics education. The credit is equal to 100% of qualified STEM contributions made by taxpayers during the taxable year. Qualified STEM contributions include: (1) STEM school contributions, (2) STEM teacher externship expenses, and (3) STEM teacher training expenses. The bill also provides a tax credit for contributions to elementary and secondary schools that benefit science, technology, engineering, or mathematics education. The credit is equal to 100% of qualified STEM service contributions made by taxpayers during the taxable year. Qualified STEM service contributions include: (1) STEM service contributions paid or incurred during the taxable year for services provided in the United States or on a military base outside the United States; and (2) STEM inventory property contributed during the taxable year which is used by an educational organization located in the United States or on a military base outside the United States in providing education in grades K-12 in science, technology, engineering or mathematics.
Observations: Overall, the fine-tuned model does an excellent job of summarizing the bill. It captures domain-specific jargon and the key points that are represented but not explained in the human-written ground truth. It differentiates itself from the zero-shot model by providing a more detailed and comprehensive summary.
Use case: Financial reports
In this use case, zero-shot prompt engineering is used to create summaries of financial reports. A summary of summaries approach is then used to generate the results.
Summary of summaries approach
When you write prompts, the GPT-3 total of the prompt and the resulting completion must include fewer than 4,000 tokens, so you're limited to a couple pages of summary text. For documents that typically contain more than 4,000 tokens (roughly 3,000 words), you can use a summary of summaries approach. When you use this approach, the entire text is first divided up to meet the token constraints. Summaries of the shorter texts are then derived. In the next step, a summary of the summaries is created. This use case demonstrates the summary of summaries approach with a zero-shot model. This solution is useful for long documents. Additionally, this section describes how different prompt engineering practices can vary the results.
Note
Fine-tuning is not applied in the financial use case because there's not enough data available to complete that step.
Dataset
The dataset for this use case is technical and includes key quantitative metrics to assess a company's performance.
The financial dataset includes:
url: The URL for the financial report.pages: The page in the report that contains key information to be summarized (1-indexed).completion: The ground truth summary of the report.comments: Any additional information that's needed.
In this use case, Rathbone's financial report, from the dataset, will be summarized. Rathbone's is an individual investment and wealth management company for private clients. The report highlights Rathbone's performance in 2020 and mentions performance metrics like profit, FUMA, and income. The key information to summarize is on page 1 of the PDF.
API_KEY = # SET YOUR OWN API KEY HERE
RESOURCE_ENDPOINT = "# SET A LINK TO YOUR RESOURCE ENDPOINT"
openai.api_type = "azure"
openai.api_key = API_KEY
openai.api_base = RESOURCE_ENDPOINT
openai.api_version = "2022-12-01-preview"
name = os.path.abspath(os.path.join(os.getcwd(), '---INSERT PATH OF LOCALLY DOWNLOADED RATHBONES_2020_PRELIM_RESULTS---')).replace('\\', '/')
pages_to_summarize = [0]
# Using pdfminer.six to extract the text
# !pip install pdfminer.six
from pdfminer.high_level import extract_text
t = extract_text(name
, page_numbers=pages_to_summarize
)
print("Text extracted from " + name)
t
Zero-shot approach
When you use the zero-shot approach, you don't provide solved examples. You provide only the command and the unsolved input. In this example, the Instruct model is used. This model is specifically intended to take in an instruction and record an answer for it without extra context, which is ideal for the zero-shot approach.
After you extract the text, you can use various prompts to see how they influence the quality of the summary:
#Using the text from the Rathbone's report, you can try different prompts to see how they affect the summary
prompt_i = 'Summarize the key financial information in the report using qualitative metrics.\n\nText:\n'+" ".join([normalize_text(t)])+'\n\nKey metrics:\n'
response = openai.Completion.create(
engine="davinci-instruct",
prompt=prompt_i,
temperature=0,
max_tokens=2048-int(len(prompt_i.split())*1.5),
top_p=1.0,
frequency_penalty=0.5,
presence_penalty=0.5,
best_of=1
)
print(response.choices[0].text)
>>>
- Funds under management and administration (FUMA) reached £54.7 billion at 31 December 2020, up 8.5% from £50.4 billion at 31 December 2019
- Operating income totalled £366.1 million, 5.2% ahead of the prior year (2019: £348.1 million)
- Underlying1 profit before tax totalled £92.5 million, an increase of 4.3% (2019: £88.7 million); underlying operating margin of 25.3% (2019: 25.5%)
# Different prompt
prompt_i = 'Extract most significant money related values of financial performance of the business like revenue, profit, etc. from the below text in about two hundred words.\n\nText:\n'+" ".join([normalize_text(t)])+'\n\nKey metrics:\n'
response = openai.Completion.create(
engine="davinci-instruct",
prompt=prompt_i,
temperature=0,
max_tokens=2048-int(len(prompt_i.split())*1.5),
top_p=1.0,
frequency_penalty=0.5,
presence_penalty=0.5,
best_of=1
)
print(response.choices[0].text)
>>>
- Funds under management and administration (FUMA) grew by 8.5% to reach £54.7 billion at 31 December 2020
- Underlying profit before tax increased by 4.3% to £92.5 million, delivering an underlying operating margin of 25.3%
- The board is announcing a final 2020 dividend of 47 pence per share, which brings the total dividend to 72 pence per share, an increase of 2.9% over 2019
Challenges
As you can see, the model might produce metrics that aren't mentioned in the original text.
Proposed solution: You can resolve this problem by changing the prompt.
The summary might focus on one section of the article and neglect other important information.
Proposed solution: You can try a summary of summaries approach. Divide the report into sections and create smaller summaries that you can then summarize to create the output summary.
This code implements the proposed solutions:
# Body of function
from pdfminer.high_level import extract_text
text = extract_text(name
, page_numbers=pages_to_summarize
)
r = splitter(200, text)
tok_l = int(2000/len(r))
tok_l_w = num2words(tok_l)
res_lis = []
# Stage 1: Summaries
for i in range(len(r)):
prompt_i = f'Extract and summarize the key financial numbers and percentages mentioned in the Text in less than {tok_l_w}
words.\n\nText:\n'+normalize_text(r[i])+'\n\nSummary in one paragraph:'
response = openai.Completion.create(
engine=TEXT_DAVINCI_001,
prompt=prompt_i,
temperature=0,
max_tokens=tok_l,
top_p=1.0,
frequency_penalty=0.5,
presence_penalty=0.5,
best_of=1
)
t = trim_incomplete(response.choices[0].text)
res_lis.append(t)
# Stage 2: Summary of summaries
prompt_i = 'Summarize the financial performance of the business like revenue, profit, etc. in less than one hundred words. Do not make up values that are not mentioned in the Text.\n\nText:\n'+" ".join([normalize_text(res) for res in res_lis])+'\n\nSummary:\n'
response = openai.Completion.create(
engine=TEXT_DAVINCI_001,
prompt=prompt_i,
temperature=0,
max_tokens=200,
top_p=1.0,
frequency_penalty=0.5,
presence_penalty=0.5,
best_of=1
)
print(trim_incomplete(response.choices[0].text))
The input prompt includes the original text from Rathbone's financial report for a specific year.
Ground truth: Rathbones has reported revenue of £366.1m in 2020, up from £348.1m in 2019, and an increase in underlying profit before tax to £92.5m from £88.7m. Assets under management rose 8.5% from £50.4bn to £54.7bn, with assets in wealth management increasing 4.4% to £44.9bn. Net inflows were £2.1bn in 2020 compared with £600m in the previous year, driven primarily by £1.5bn inflows into its funds business and £400m due to the transfer of assets from Barclays Wealth.
Zero-shot summary of summaries output: Rathbones delivered a strong performance in 2020, with funds under management and administration (FUMA) growing by 8.5% to reach £54.7 billion at the end of the year. Underlying profit before tax increased by 4.3% to £92.5 million, delivering an underlying operating margin of 25.3%. Total net inflows across the group were £2.1 billion, representing a growth rate of 4.2%. Profit before tax for the year was £43.8 million, with basic earnings per share totaling 49.6p. Operating income for the year was 5.2% ahead of the prior year, totaling £366.1 million.
Observations: The summary of summaries approach generates a great result set that resolves the challenges encountered initially when a more detailed and comprehensive summary was provided. It does a great job of capturing the domain-specific jargon and the key points, which are represented in the ground truth but not explained well.
The zero-shot model works well for summarizing mainstream documents. If the data is industry-specific or topic-specific, contains industry-specific jargon, or requires industry-specific knowledge, fine-tuning performs best. For example, this approach works well for medical journals, legal forms, and financial statements. You can use the few-shot approach instead of zero-shot to provide the model with examples of how to formulate a summary, so it can learn to mimic the summary provided. For the zero-shot approach, this solution doesn't retrain the model. The model's knowledge is based on the GPT-3 training. GPT-3 is trained with almost all available data from the internet. It performs well for tasks that don't require specific knowledge.
Recommendations
There are many ways to approach summarization by using GPT-3, including zero-shot, few-shot, and fine-tuning. The approaches produce summaries of varying quality. You can explore which approach produces the best results for your intended use case.
Based on observations on the testing presented in this article, here are few recommendations:
- Zero-shot is best for mainstream documents that don't require specific domain knowledge. This approach attempts to capture all high-level information in a succinct, human-like manner and provides a high-quality baseline summary. Zero-shot creates a high-quality summary for the legal dataset that's used in the tests in this article.
- Few-shot is difficult to use for summarizing long documents because the token limitation is exceeded when an example text is provided. You can instead use a zero-shot summary of summaries approach for long documents or increase the dataset to enable successful fine-tuning. The summary of summaries approach generates excellent results for the financial dataset that's used in these tests.
- Fine-tuning is most useful for technical or domain-specific use cases when the information isn't readily available. To achieve the best results with this approach, you need a dataset that contains a couple thousand samples. Fine-tuning captures the summary in a few templated ways, trying to conform to how the dataset presents the summaries. For the legal dataset, this approach generates a higher quality of summary than the one created by the zero-shot approach.
Evaluating summarization
There are multiple techniques for evaluating the performance of summarization models.
Here are a few:
ROUGE (Recall-Oriented Understudy for Gisting Evaluation). This technique includes measures for automatically determining the quality of a summary by comparing it to ideal summaries created by humans. The measures count the number of overlapping units, like n-gram, word sequences, and word pairs, between the computer-generated summary being evaluated and the ideal summaries.
Here's an example:
reference_summary = "The cat ison porch by the tree"
generated_summary = "The cat is by the tree on the porch"
rouge = Rouge()
rouge.get_scores(generated_summary, reference_summary)
[{'rouge-1': {'r':1.0, 'p': 1.0, 'f': 0.999999995},
'rouge-2': {'r': 0.5714285714285714, 'p': 0.5, 'f': 0.5333333283555556},
'rouge-1': {'r': 0.75, 'p': 0.75, 'f': 0.749999995}}]
BERTScore. This technique computes similarity scores by aligning generated and reference summaries on a token level. Token alignments are computed greedily to maximize the cosine similarity between contextualized token embeddings from BERT.
Here's an example:
import torchmetrics
from torchmetrics.text.bert import BERTScore
preds = "You should have ice cream in the summer"
target = "Ice creams are great when the weather is hot"
bertscore = BERTScore()
score = bertscore(preds, target)
print(score)
Similarity matrix. A similarity matrix is a representation of the similarities between different entities in a summarization evaluation. You can use it to compare different summaries of the same text and measure their similarity. It's represented by a two-dimensional grid, where each cell contains a measure of the similarity between two summaries. You can measure the similarity by using various methods, like cosine similarity, Jaccard similarity, and edit distance. You then use the matrix to compare the summaries and determine which one is the most accurate representation of the original text.
Here's a sample command that gets the similarity matrix of a BERTScore comparison of two similar sentences:
bert-score-show --lang en -r "The cat is on the porch by the tree"
-c "The cat is by the tree on the porch"
-f out.png
The first sentence, "The cat is on the porch by the tree", is referred to as the candidate. The second sentence is referred to as the reference. The command uses BERTScore to compare the sentences and generate a matrix.
This following matrix displays the output that's generated by the preceding command:
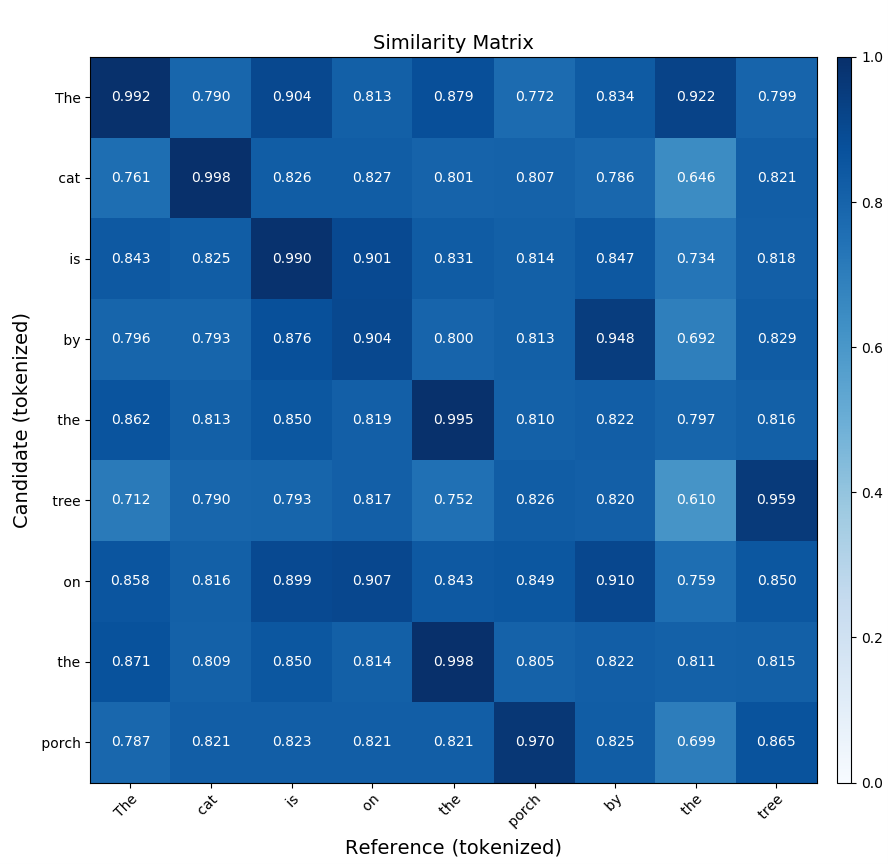
For more information, see SummEval: Reevaluating Summarization Evaluation. For a Python Package Index (PyPI) toolkit for summarization, see Summ-eval 0.892.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal author:
- Noa Ben-Efraim | Data & Applied Scientist
Other contributors:
- Mick Alberts | Technical Writer
- Rania Bayoumy | Senior Technical Program Manager
- Harsha Viswanath | Principal Applied Science Manager
To see non-public LinkedIn profiles, sign in to LinkedIn.
Next steps
- Azure OpenAI - Documentation, quickstarts, API reference
- What are intents in LUIS?
- Conversational language understanding