Modeling stage of the Team Data Science Process lifecycle
This article outlines the goals, tasks, and deliverables associated with the modeling stage of the Team Data Science Process (TDSP). This process provides a recommended lifecycle that your team can use to structure your data science projects. The lifecycle outlines the major stages that your team performs, often iteratively:
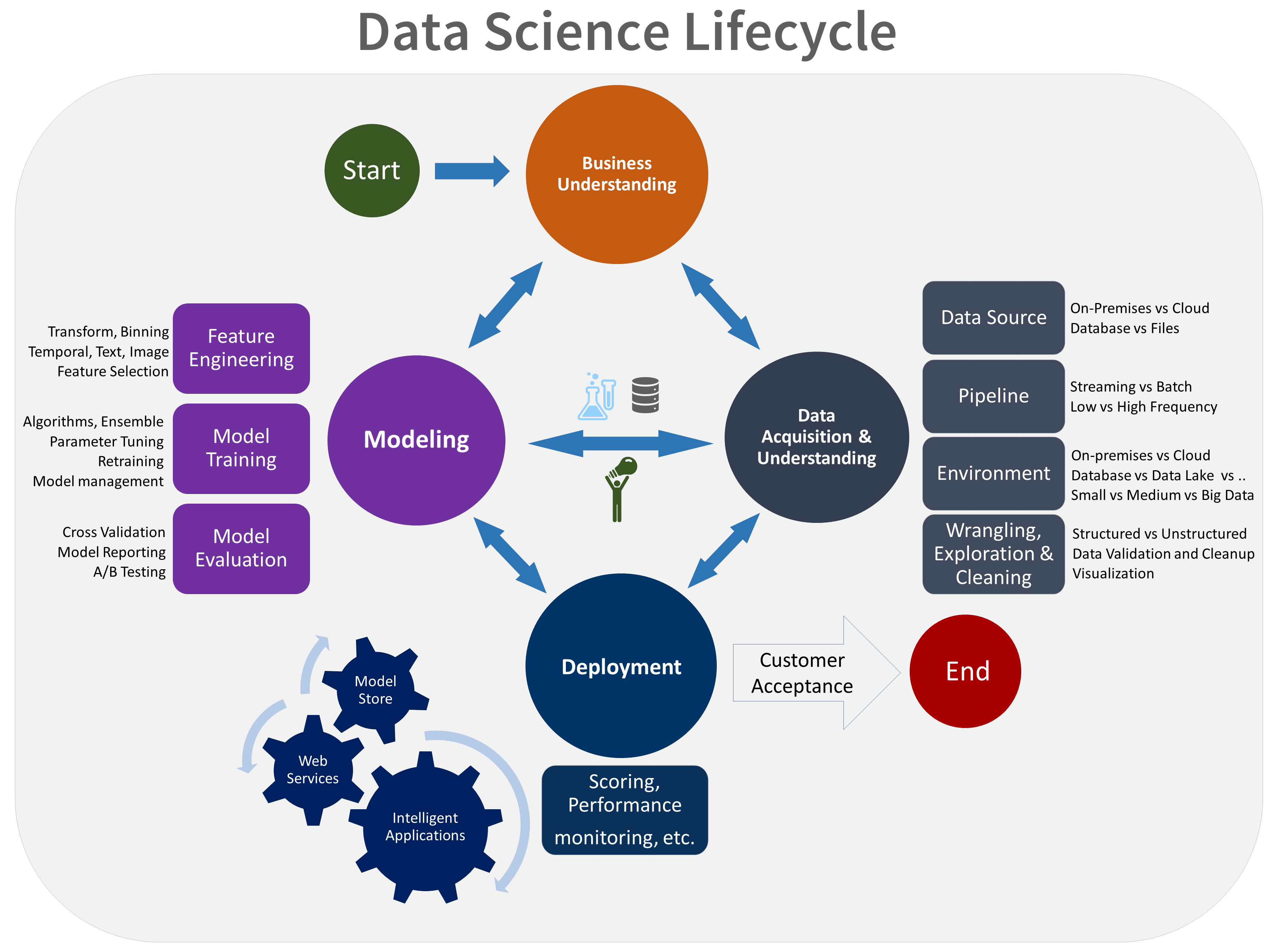
- Business understanding
- Data acquisition and understanding
- Modeling
- Deployment
- Customer acceptance
Here's a visual representation of the TDSP lifecycle:
Goals
The goals of the modeling stage are to:
Determine the optimal data features for the machine learning model.
Create an informative machine learning model that predicts the target most accurately.
Create a machine learning model that's suitable for production.
How to complete the tasks
The modeling stage has three main tasks:
Feature engineering: Create data features from the raw data to facilitate model training.
Model training: Find the model that answers the question most accurately by comparing the success metrics of models.
Model evaluation: Determine if your model is suitable for production.
Feature engineering
Feature engineering involves the inclusion, aggregation, and transformation of raw variables to create the features used in the analysis. If you want insight into how a model is built, then you need to study the model's underlying features.
This step requires a creative combination of domain expertise and the insights obtained from the data exploration step. Feature engineering is a balancing act of finding and including informative variables but at the same time trying to avoid too many unrelated variables. Informative variables improve your result. Unrelated variables introduce unnecessary noise into the model. You also need to generate these features for any new data obtained during scoring. As a result, the generation of these features can only depend on data that's available at the time of scoring.
Model training
There are many modeling algorithms that you can use, depending on the type of question that you're trying to answer. For guidance on choosing a prebuilt algorithm, see Machine Learning algorithm cheat sheet for Azure Machine Learning designer. Other algorithms are available through open-source packages in R or Python. Although this article focuses on Azure Machine Learning, the guidance it provides is useful for many machine-learning projects.
The process for model training includes the following steps:
Split the input data randomly for modeling into a training data set and a test data set.
Build the models by using the training data set.
Evaluate the training and the test data set. Use a series of competing machine-learning algorithms. Use various associated tuning parameters (known as parameter sweeps) that are geared toward answering the question of interest with the current data.
Determine the best solution to answer the question by comparing the success metrics between alternative methods.
For more information, see Train models with Machine Learning.
Note
Avoid leakage: You might cause data leakage if you include data from outside the training data set that allows a model or machine-learning algorithm to make unrealistically good predictions. Leakage is a common reason why data scientists get nervous when they get predictive results that seem too good to be true. These dependencies might be hard to detect. Avoiding leakage often requires iterating between building an analysis data set, creating a model, and evaluating the accuracy of the results.
Model evaluation
After you train the model, a data scientist on your team focuses on model evaluation.
Make a determination: Evaluate whether the model performs sufficiently for production. Some key questions to ask are:
Does the model answer the question with sufficient confidence given the test data?
Should you try any alternative approaches?
Should you collect more data, do more feature engineering, or experiment with other algorithms?
Interpret the model: Use the Machine Learning Python SDK to perform the following tasks:
Explain the entire model behavior or individual predictions on your personal machine locally.
Enable interpretability techniques for engineered features.
Explain the behavior for the entire model and individual predictions in Azure.
Upload explanations to the Machine Learning run history.
Use a visualization dashboard to interact with your model explanations, both in a Jupyter notebook and in the Machine Learning workspace.
Deploy a scoring explainer alongside your model to observe explanations during inferencing.
Assess fairness: Use the fairlearn open-source Python package with Machine Learning to perform the following tasks:
Assess the fairness of your model predictions. This process helps your team learn more about fairness in machine learning.
Upload, list, and download fairness assessment insights to and from Machine Learning studio.
See the fairness assessment dashboard in Machine Learning studio to interact with your models' fairness insights.
Integrate with MLflow
Machine Learning integrates with MLflow to support the modeling lifecycle. It uses MLflow’s tracking for experiments, project deployment, model management, and a model registry. This integration ensures a seamless and efficient machine learning workflow. The following features in Machine Learning help support this modeling lifecycle element:
Track experiments: MLflow's core functionality is extensively used in the modeling stage to track various experiments, parameters, metrics, and artifacts.
Deploy projects: Packaging code with MLflow Projects ensures consistent runs and easy sharing among team members, which is essential during iterative model development.
Manage models: Managing and versioning models is critical in this phase as different models are built, evaluated, and refined.
Register models: The model registry is used for versioning and managing models throughout their lifecycle.
Peer-reviewed literature
Researchers publish studies about the TDSP in peer-reviewed literature. The citations provide an opportunity to investigate other applications or similar ideas to the TDSP, including the modeling lifecycle stage.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal author:
- Mark Tabladillo | Senior Cloud Solution Architect
To see non-public LinkedIn profiles, sign in to LinkedIn.
Related resources
These articles describe the other stages of the TDSP lifecycle:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for