The journey to SaaS: Dynamics 365
Many independent software vendors (ISVs) think about moving from on-premises software delivery to a cloud-based and software-as-a-service (SaaS)–based delivery model. At Microsoft, we’ve been through this journey with many of our products, and we get asked to share our real-life experiences and the key lessons that we learned along the way.
Our goal with this article is to give an overview of how this journey played out when we built Microsoft Dynamics 365. We describe the thought process we went through and the key drivers for each of the major decisions we made. We hope that this document provides a sense of the evolution of our product as we moved from delivering on-premises software to a hyperscale SaaS product used by millions of users across thousands of organizations. We hope that by reading this document, you can learn from our experiences and plan your own journey to SaaS. While the Microsoft journey with Dynamics 365 might be unique, we believe that the lessons and principles we learned can still provide valuable insights for organizations of any size that are planning their own transition to a SaaS model.
A brief history of our journey
Microsoft Dynamics has a deep history as a set of on-premises products. We adopted the cloud for all of the many benefits it offered, and we knew that our technology and business model would need to adapt as we moved toward providing SaaS.
The first decision that we confronted was the choice between building something new or evolving our on-premises applications into cloud services. For Dynamics 365, we believed two things. First, there was sufficient value in the data models and business logic that we’d created and validated with thousands of customers that it was worth trying to evolve our existing solutions. Second, the layered architecture and platform framework of our on-premises products provided the right levers to allow us to evolve to a great cloud architecture more quickly than starting from scratch. The combination of value and speed, along with the understanding that we could evolve to the correct cloud-native principles, made evolution to cloud-based SaaS and continuous improvement the right choice for Dynamics 365. Other organizations might have different priorities and come to a different strategy.
Early on, we decided to focus on building the best product we could build on the Microsoft Azure platform. Cloud platforms evolve rapidly, and we wanted to take advantage of the richness of one platform, instead of spreading our resources across multiple clouds. Other SaaS vendors might make different decisions based on their own situations. For example, a horizontal platform provider might build software for customers to use across multiple clouds, so it makes sense for them to have a presence on each of those cloud platforms. But a SaaS application developer can make a choice to focus on one cloud and gain the benefits of focusing on that one cloud provider and their evolution. For Dynamics 365, we knew that going all-in on Microsoft Azure would give us a more integrated and seamless experience while maintaining robust security and high performance.
As we started to deeply explore the Azure platform and plan our SaaS journey, we learned how to operate and scale a massive enterprise resource planning (ERP) platform in the cloud. At the same time, Azure has become richer and more capable, and it introduced new capabilities that we couldn't have imagined. We knew the constant evolution of the cloud meant that our migration wouldn't be a one-time thing. Instead, we thought about continuous improvement at every step of our journey. Continuous improvement affects everything we do, and in the early stages of our journey, we had to make significant changes—everything from our overall architecture to how we dealt with database queries. We’re constantly evolving our solution to make the most of what the cloud enables. We’ve embraced microservice architecture, and we use generative AI as part of our ongoing evolution. These approaches and technologies are easier to build, deploy, and operate when you use a powerful cloud platform like Microsoft Azure.
An essential ingredient of continuous improvement in the cloud is telemetry. With effective telemetry, you can understand how the application is used and how it performs—even down to the level of individual features. Telemetry provides insights that let you solve problems by knowing what's happened instead of following traditional on-premises approaches like reproducing the problem and debugging. Telemetry also allows you to make engineering decisions based on real data and to confirm product hypotheses through experimentation and data. Creating a telemetry infrastructure along with the right policies around what data is retained and for how long, and how it's managed is something that should be done as early as possible.
Understanding data classification and retention policies for the data managed by your application also requires extra attention as part of the journey to SaaS. As a SaaS provider, your responsibilities under current and emerging data privacy laws are different than when you supplied software that customers deployed and ran themselves. It's essential that you understand the data privacy regulations that apply to you as a SaaS provider. You also need to get your data classification and retention processes in place at the start of your cloud journey.
How we prepared for the journey
Scoping an MVP
Our strategy focused on building a minimum viable product (MVP) so that we could get the solution to customers as quickly as possible and begin learning about the unique challenges and opportunities of SaaS. This focus was a strategic choice. We believe that rapid learning and iteration is essential in the cloud, and defining the MVP is a place to start.
The term minimum viable product is often misunderstood. It’s important to consider that both attributes of the MVP are equally important:
- Minimum: Figure out the quickest way to start generating value for your customers. The sooner your customers use your solution, the sooner you start learning how they use it and how you can continue to improve it.
- Viable: It’s critical that you scope your product so that it’s complete enough for somebody to get real value from it. Initially, you pick a subset of the overall capabilities that you expect to build. Picking the right subset is important—if you're too minimum to be viable, then customers don’t use the product, and you don’t get the feedback you need to evolve.
For Dynamics 365, we focused on making a product that was ready for customers to use right from its launch. Then, we learned how customers got value from it, and we got a large amount of feedback and telemetry. We used that data to inform our product journey, iterating and making it better and better as we progressed.
Our strategy was to build a product that new customers would love. While we were intentional about making migrations from existing on-premises customers easier, migration was a secondary focus compared to building a great modern product. This strategy meant that our new customers would have a complete experience in Dynamics 365 right from the start. They also provided us with invaluable feedback, and they did so with the benefit of fresh eyes. They weren’t already heavily invested in the on-premises Dynamics products, so they helped us to build a product that truly was cloud native and a full SaaS offering. As we continued to improve and expand our capabilities, we eventually reached the point where the feature set was a superset of the on-premises products. At that point, we could start to support the transition of our existing customers from the on-premises version to the more advanced Dynamics 365.
We consciously chose this strategy because we knew it would work well for an ERP system. In other products, it might be possible to pick a subset of the product’s features to move first, and then add more features over time. But in an ERP, components are tightly interconnected. The product isn’t useful until there’s a slice of functionality across all these components, providing a useful end-to-end experience to customers. The MVP scope is a horizontal slice of features across each component. We decided to select a cross-cutting set of functionalities that would support new customers’ use cases:
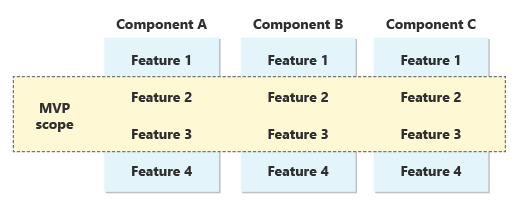
For other solutions, it might make sense to instead scope an MVP as a whole component. It’s important to make a conscious decision about the strategy you follow when you embark on your own journey to SaaS. The key is that the initial deliverable to market should be as small as possible, while still being complete enough to get real usage.
As we planned and improved, we kept in mind that customer expectations were continuously evolving, too. Rather than migrating our product in its exact current state, we instead planned for what customers would need by the time we had a product ready for them to use. A journey to SaaS coupled with a cloud migration is often a long-term endeavor, taking months or even years. It's important not to lose sight of changes in customer demand during this time. Otherwise, you can spend significant effort building something that doesn’t fully address customer needs when it finally arrives.
Usage, customer satisfaction, and costs
On-premises software revenue is typically recognized at the point that the sales transaction occurs, and the responsibility for successful deployment and adoption rests with the customer. With a cloud SaaS subscription model, customers often begin by licensing a few seats and only expand their subscription after the solution has been proven. Any seats that they purchase but don't use are a risk because they might be canceled at the next subscription anniversary. As a result, with the transition to SaaS, we changed the top metrics that we used to drive our business.
In the on-premises world of licensed software, the primary focus was revenue. In the cloud, the focus was on usage and customer satisfaction. These metrics became the forward indicators of revenue and revenue growth. We spent effort on minimizing the time to successful deployment, providing visibility of purchased but unused licenses, and maintaining high satisfaction across user and business roles. From the start, our focus has been on creating products that customers love to use. We know from experience that when customers get value from using the product, revenue follows. By prioritizing customer experience and usage, we set the foundations for a successful business strategy.
When you build SaaS, the cost of goods sold (COGS) matters a lot, especially as you scale and your costs grow, too. But it's better to prioritize satisfaction and usage first. If you provide a good customer experience, you can optimize the costs of delivering the service by making more efficient use of your resources and taking advantage of new platform capabilities. If the experience isn’t good enough, usage will be lower and you’ll have fewer customers to satisfy. So when we review our progress, we focus on three key performance indicators, in order of importance:
- Customer satisfaction: Do our customers like the experience of using the product? What’s their feedback?
- Usage: How many users do we have? How many subscriptions do we have? Is our usage accelerating? What's the time between purchase and usage? How can we encourage customers to use all the subscriptions they purchase?
- COGS: How much does it cost to serve our customers?
It's also important to think about how any SaaS product generates revenue. Customers need to understand how they pay for the service, and the pricing model needs to make sense to them. In many business-to-business SaaS solutions, the number of users that the customer has is a great indicator of the resources consumed when the users use the system. The more users who actively use the system, the more system resources are needed to give them a good experience. The cost to the customer reflects that fact. Customers have an intuitive understanding of a user-based pricing structure.
However, there are some situations where user counts don't give a good indication of the resources that the customer consumes. For example, when a customer’s marketing team sends out a large number of messages for an email campaign, there might just be one user sending millions of email messages. Similarly, a background process, not a user, imports order details. It's important that customers understand the metrics they're charged for and can predict their bill. You might choose to use meters like the number of contacts they send email messages to or the number of order lines they process each month.
The architecture of Dynamics 365
Identity, authentication, and authorization
Business applications like Dynamics 365 manage high-value business data and automate mission-critical business activities. It's essential to ensure that only authorized users have access to data and the system's actions. By using Microsoft Entra ID, enterprises can manage access to Dynamics 365 with the same tools and platforms that they already use across their IT estate. Customers can take advantage of advanced security features like Conditional Access without more work on our part. The capabilities to secure their Dynamics system continue to evolve with the ongoing investment by Microsoft in the Entra platform.
Dynamics 365 assigns users to roles and assigns permissions for specific data and actions to those roles. This approach follows a common pattern for managing authorization beyond the user authentication provided by Entra. This approach also provides the capability for Dynamics 365 to enforce best-practice business requirements like the separation of duties.
Tenancy model
Each organization that uses Dynamics 365 expects their data to be kept secure and isolated from access by other organizations. We model each organization as a tenant, and each tenant has many users that can each use the products and work with the organization’s data. Sharing resources reduces cost components of running the services, but sharing must be balanced against the requirements to ensure the expected levels of tenant isolation. Fortunately, the Azure platform provides rich capabilities to enable application providers to balance cost as they deliver required isolation.
For example, we felt that it was important to keep each tenant’s business data in a separate SQL database. This separation allows us, among other capabilities, to implement Azure SQL transparent data encryption (TDE) with customer-managed keys—an important component of our enterprise trust promises regarding data. Azure SQL, specifically including elastic pools, gives us cost efficiency while still allowing a separate database per customer. In addition to increasing infrastructure costs, the decision to keep a separate database per tenant increases the management complexity. There aren’t enough database administrators (DBAs) to manage databases manually at the scale of the Dynamics service, and that led to significant investment in automation of management tasks. For more information about how Dynamics 365 works with databases at scale, see Running 1M databases on Azure SQL for a large SaaS provider: Microsoft Dynamics 365 and Power Platform.
For every tier of our solution, our strategy has been to use native Azure platform capabilities to enforce tenant isolation and deliver scale and resiliency while simultaneously gaining cost efficiencies where we can. We’re always looking at places where we can optimize our system, while prioritizing tenant security and providing an outstanding customer experience.
Deployment stamps
Dynamics 365 operates at hyperscale. There are hundreds of thousands of customers, with millions of users, each depending on our products. These numbers continue to grow over time. SaaS solutions typically need to be architected to scale and need to support customers across the planet.
In the cloud, it's critical to move from scaling up to scaling out wherever possible. If additional demand can be met by adding more nodes (scaling out) instead of making existing nodes more powerful (scaling up), and that relationship is close to linear, then an approach based on scale-out provides the potential to drive even higher scale. Dynamics 365 uses a scale-out model at the application tier. Integrated monitoring detects increases in load for specific tenants and adds more nodes to meet the demand.
In conjunction with your tenant model and scale-out architecture, you can follow the Deployment Stamps pattern, with each stamp supporting a set of customers. When a stamp approaches its maximum capacity, you can provision a new stamp and start to deploy new customers there. By using stamps, you can support continued customer growth, and you can expand your regional presence to new geographies.
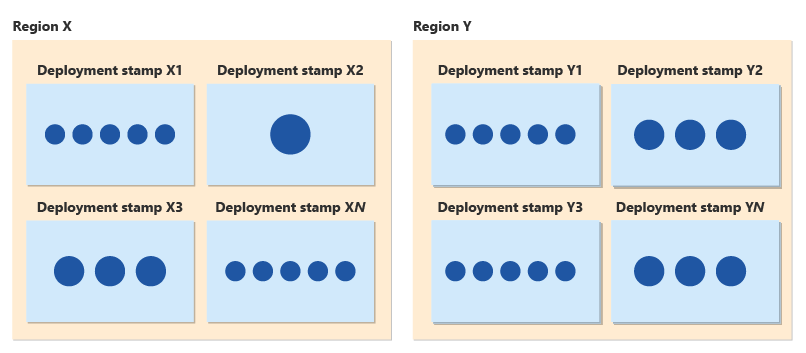
By using deployment stamps, you also gain reliability benefits. You can roll out our updates progressively, and safe deployment processes help you to gradually roll changes out across a global fleet. Each stamp is independent of others, so if a stamp experiences a problem, only the subset of customers allocated to that stamp are affected. Stamps help you to reduce the blast radius of a problem or fault and contribute to an overall disaster recovery strategy.
As with every architectural decision, base your use of deployment stamps on your business needs. Deploying a stamp requires deploying a set of infrastructure to support it. If the minimum size of a stamp is too large, it’s difficult to justify deploying a new stamp into a new market because you need to reach a critical mass of customers first. It’s also important to understand how your customers’ growth affects their use of the product because as they grow, they use more of the stamp’s resources. These considerations are as important for a small ISV as they are for a hyperscale platform like Dynamics 365.
Control planes and configuration
When an ISV moves to a cloud-based SaaS delivery model, one of the most dramatic changes is that they take responsibility for the operation of the service. In most on-premises software, customers’ IT departments are responsible for deploying, configuring, and managing the systems. Customers themselves take care of monitoring systems and make decisions about when to roll out updates. They’re also responsible for executing all the steps involved. Often, specialist service integration partners help customers to operate complex products in their environment. The software provider becomes responsible for all these activities across all their customers by moving to a cloud and SaaS model. With the transition to SaaS, it's necessary to build the ISV’s service and also a control plane to automate the work of onboarding and managing tenants. Control planes and automation are important, even with a relatively small number of customers.
It’s good practice to design a control plane that’s resilient, reliable, and highly available. Too often, control planes are treated as an afterthought in the journey to building a SaaS product. But if a control plane isn’t designed with the same care as the rest of the product, you’re at risk of it being a single point of failure. Without proper attention to the resiliency of the control plane, a control plane failure could affect all customers.
In Dynamics 365, we have a service-level control plane, which handles operations like onboarding new tenants. We also have a tenant-level control plane, which enables a customer’s administration team to initiate maintenance activities and change configurations themselves because they can perform these operations through the service.
Customization and extensibility
A core value proposition of the SaaS model is that all customers run one version of the service code. When customers run one version of the service code, issues are identified and fixed once, and all customers get the benefit of those solutions quickly. The goal is to be able to continuously evolve the one version of the service without customers having to plan for testing and deployment of updates.
To achieve this benefit, there are many changes required compared to running software in the on-premises world. For example, you need to plan processes and procedures to reduce the likelihood of regressions.
In the Dynamics 365 transformation, one area we invested in was the development of rich model-driven extensibility. ERP applications demand extensibility to support integration with other critical business systems and to meet the unique functional needs of specific customers. Instead of customization at a source code level, which was typical with on-premises applications, we introduced capabilities to extend data models through tenant-specific metadata and to trigger extended logic based on events that occur in the system.
We added isolation and governance capabilities to protect the service and other tenants from issues in another tenant’s extended logic. Our approach gave customers the required level of extensibility but enabled them all to still run with the same product version. Additionally, updates could be delivered to the product without customers having to merge our changes and rebuild their code to make their extensions work with newer versions of the product.
Customization might not be a requirement for every product, but if a product does require it, customization becomes a critical design factor. You must meet the requirement without compromising the core benefits of the SaaS model. This requirement was a significant focus for Dynamics 365. The model-driven extensibility both preserved the SaaS value proposition and improved the ability of customers to create and maintain their extensions.
How we designed Dynamics 365 for resiliency
As you consider your deployment model on Azure, a critical component to consider is your resiliency if there are issues in a dependent service—for example, a networking issue, a power problem, or the maintenance of a virtual machine. In the on-premises world, where the infrastructure serves a single customer tenant, many customers rely on high availability strategies for each infrastructure component. But when you consider resiliency at cloud scale, high availability is often necessary but not sufficient. With enough scale, failures happen.
A core focus area for Dynamics 365 today is targeting redundancy across Azure availability zones to allow the mission-critical Dynamics services to seamlessly continue operating, even if an outage impacts a datacenter or an entire availability zone.
To apply this mindset to your own solution, there are some important practices to follow.
- Make sure that you invest in monitoring tools to quickly identify problems. With SaaS, your customers expect you to know about outages and to engage rapidly to restore service.
- Use platform capabilities like availability zones and zone redundancy if they're appropriate for your service.
- Design your applications for resiliency at every layer. For example, it's important to also consider other cloud best practices like using retries, circuit breakers, and bulkheads, and adopting asynchronous communication practices. These practices can keep your service healthy even when other services you depend on are under stress.
- Consider the availability of your control plane, especially because it has a role in the recovery of your solution when infrastructure assets are impacted.
- When you've implemented capabilities for resiliency, run tests. You never know if your plans and features are complete until you try to use them. It can be useful to exercise your failover processes as part of your normal maintenance activities, which can give you both an approach to maintenance without downtime and a validation of your failover mechanisms.
The reliability pillar of the Azure Well-Architected Framework provides great guidance on these topics.
How we adapted to a cloud environment
Dynamics 365 has evolved into a sophisticated cloud-native architecture, but it's common for ISVs to make more limited lift-and-shift transitions from on-premises environments into the cloud. We discussed the model of defining an MVP to get your SaaS service into customers' hands quickly, which begins the cycle of learning and continuous improvement. But there's a balance. Lift and shift should really be Lift, shift, and adapt.
Earlier in this article, we discussed designing for resiliency with availability zones and other cloud best practices. There are other areas where common on-premises design patterns lead to challenges or higher costs in the cloud, too. For example, in on-premises applications, it's common to store binary large objects in a relational database. For example, you might store a PDF document related to a sales order as part of the sales order in an SQL database. In the on-premises world, this approach simplifies consistency across backups and point-in-time restore functions. However, in the cloud, large objects stored in the database can be costly. Additionally, Azure Storage blobs simplify storing large binary objects, with straightforward logic required to preserve consistent backups.
It's important to think about the things that you need to do as part of a cloud transformation. You should do those things that produce a stronger cloud product. But you should also use that as an opportunity to get to market quickly and begin the virtuous cycle of learning and continuous improvement.
The cloud can also make entirely new solutions practical that weren’t an option in an on-premises environment. One of the most performance-intensive processes in an ERP system is manufacturing resource planning, or MRP II. MRP II looks at inventory on hand, the expected incoming and outgoing orders, and manufacturing requirements. Then it determines what a business must buy or make to satisfy expected orders. In the on-premises Dynamics, this functionality was implemented in application code that worked directly against the relational store. The planning function consumed a lot of system capacity and ran for an extended time. In the first cloud versions, the on-premises functionality was brought forward unchanged—it worked, but with the same scale and performance challenges. Then, a few years ago, we introduced a new in-memory microservice that could complete the same planning run in a fraction of the time and without the performance impact. Importantly, because the microservice is a critical core of a manufacturing system, we introduced it as a capability that customers could opt in to after verifying in their sandbox environments that it produced the correct results. As more customers pivoted to the new microservice, we triggered efforts to get every customer to use the microservice so that the old capability could be deprecated. With MRP II becoming something that could be run in minutes at any time, organizations could be nimbler. The cloud made creating and connecting an in-memory microservice practical, and good SaaS engineering principles allowed even this most critical part of the service to evolve without disrupting customers.
How we migrated existing customers to the cloud
Migration of an existing customer base can be the fastest way to grow a cloud service to scale. However, when we brought Dynamics 365 to the cloud, we focused initially on new customers. There were two key reasons:
- This approach gave us a way to gauge whether we had delivered a SaaS solution that won on its own merits and not just one that appealed to on-premises customers looking for a simple cloud migration.
- We could focus on the MVP and defer tasks like building tools for migrating existing customers.
After we saw traction with new customers, we then were able to focus on migrating existing on-premises customers.
We found that customers are often afraid of the cost and complexity of the move. It was important for us to provide tools that reduce the cost and remove the unknown factors. We developed tools to help with analyzing the effort involved in migrating their data to new schemas that had evolved in our cloud product and to understand the impact of the migration on the customer's extensions and integrations. We also found that it was helpful to build out other tools and programs that put boundaries around the time and cost to migrate.
Moving to the cloud alone benefits customers by removing much of the systems management burden they face with on-premises products, but highlighting the benefits of your cloud version is an important motivator, too.
How we learned to operate Dynamics 365 as SaaS
After you've defined an MVP and done the engineering to lift, shift, and adapt, you need to focus on operating the SaaS service on behalf of your customers. This transformation is enormous. In the on-premises world, software providers create and ship the software, system integrators deploy it, and the customer’s IT organization or outsourced provider runs it. With SaaS, not only is the SaaS provider principally responsible for operating the service, but they're also responsible for operating it for hundreds to thousands of customers at the same time.
We learned a lot by operating Dynamics 365 in the cloud for a large and growing number of customers.
Monitor: As a service provider, customers expect you to detect service health issues before they do, and they expect you to immediately work on resolutions. A health issue isn't just when the service is down. A customer's view of a service being unhealthy includes the service performing slowly or behaving incorrectly. It's essential that you develop adequate monitoring tools—this development is part of your service, not an optional accessory.
Communicate: In the on-premises world, the customer can see their IT team working on a problem. In the cloud, they can’t. It's essential to communicate when you detect a service health issue, to keep communicating on the progress to resolution, and to confirm the all clear when the issue is resolved. The nature of the communications varies with the severity of the issue. Your communications pipeline is also a core part of your SaaS service, and you need to ensure that communications can succeed even when core parts of your SaaS service’s infrastructure are compromised.
Whole-stack view: In the on-premises world, the application provider is generally responsible for the application component, and the customer owns the underlying infrastructure. In the cloud, you're responsible for the whole stack. If the service has a health issue, the customer looks to you to detect, communicate, and repair, whether the issue is in the application or in the cloud platform it runs on.
Automate: If humans are required to perform manual steps in the operation of the service, mistakes will inevitably be made. Every possible action should be automated and logged. If an action is required on enough service nodes, automation is the only option. A great example is the database administration for Dynamics 365. With our decision to keep each tenant’s data in a separate Azure SQL database, we needed to develop automation to handle all the tasks typically performed by a DBA, for example, index maintenance and query optimization. For more information on how we manage databases at scale, see Running 1M databases on Azure SQL for a large SaaS provider.
Safe deployment: Wherever possible, changes should follow a safe deployment process. First, changes are introduced to low-risk environments—for example, a cloud region with only smaller customers or less critical workloads. Next, they progress to a group of slightly larger, more complex customers, and so on, until all customers have been updated. At every step, there needs to be monitoring to evaluate whether the change is successful. If there's an issue, the process should stop the change rollout and mitigate issues, or roll it back where it has already been deployed. Safe deployment practices apply to both code and configuration changes. For more information, see Advancing safe deployment practices.
Live-site incident management: For us, a live-site incident means that a customer is having an issue with our service in production that requires engineering engagement. It might be a health issue that we detect or an issue reported by the customer that our support teams aren't able to resolve on their own. Live-site excellence is critical to SaaS success. Here are a few key points from our experience:
- The engineering team should handle live-site incidents. In the past, many companies had separate operations or support engineering teams. We made an explicit choice to have our core engineering teams cover live-site incidents. They have the best expertise, and seeing issues first-hand inspires the right creativity and energy to drive real, rapid improvement and better future designs. It's something that needs to be considered when planning development schedules, but it drives great results.
- Live-site incident leadership is a skill, and it's hard work—recognize it, train for it, learn to hire for it, and reward it.
- The priority should be detection, isolation, and mitigation. Get the customer healthy again, and then worry about longer term improvements.
Learn and improve: Someone once said, “Never waste a good crisis.” Every live-site incident is an opportunity to improve. After mitigation is completed, make sure that you ask how to detect similar issues faster, how to correct the underlying issue to fully cure it, how to minimize the impact of similar issues, whether other similar issues might exist elsewhere in the service, and how to prevent the entire class of issues. Prioritizing these corrective actions improves service quality and reduces the demand for future live-site incidents. Service quality must improve over time, otherwise as you grow, the impact of every issue also gets higher.
Shift left: Issues that require the engagement of the live-site team are expensive. It takes time for issues to get to them, and the live-site team is a scarce resource that needs to be available for the most serious service health issues and management tasks.
Wherever possible, the best solution is eliminating an issue altogether, followed quickly by automated detection and automated mitigation. When that’s not possible, shifting left helps to empower the frontline support team to detect and correct the issue or perform the task, or even better, empower the customer to self-serve and perform the task themselves. The following diagram shows how support cases start with a customer, go to a frontline support team, and then to the engineering team. An arrow indicates that we shift the resolution action to the left to reduce the impact of incidents.

Keep things standard: It can be tempting to mitigate an issue by making special arrangements for one customer. At scale, everything that's special becomes a corner case that causes something else to fail. Aim to keep all tenants using standard code, settings, and configuration.
Continuous innovation
Throughout this article, we’ve talked about the need to get your product to the cloud and start the virtuous cycle of continuous learning and continuous improvement. Continuous innovation is an expectation for most SaaS products. But when a SaaS product is the successor to a long-standing on-premises product, it likely takes significant change management to prepare customers for continuous innovation.
Here are three key focus areas from our Dynamics 365 transformation:
Near-zero downtime maintenance: As the number of customers in various businesses and locations increases, it becomes impossible to find universally acceptable maintenance windows. You need to build engineering maturity so that maintenance activities can happen while the system is online. In particular, deployment of service updates needs to happen with downtime that's as close to zero as possible.
Eliminate regressions: It takes customer trust to depend on a mission-critical service with a continuous innovation policy. That trust is earned in small drops with every day of successful operation and every seamless service update. Unfortunately, it's lost in buckets—quickly and in large amounts—with any regression, no matter how small. It's worthwhile to do everything you can do that eliminates regressions in the engineering process, especially by using safe deployment processes.
Feature flags: The Dynamics 365 team has invested extensively in a feature flags framework. A feature flag can be enabled or disabled for the entire service, for subsets of tenants, or even for a single tenant. By using feature flags, we enable the introduction of new capabilities without disrupting the operation of the mission-critical business processes that Dynamics 365 supports.
Here's how feature flags can help:
- A simple performance or security fix can be introduced with the flag enabled by default. Everyone should get the benefit of the change immediately.
- Something that changes a user’s experience, a business process, or the behavior of an externally visible API is introduced with the flag turned off by default.
- Changing a feature flag is effectively changing the code that runs, so feature flag changes should be managed through safe deployment as well. For example, suppose you introduce a fix for an issue, and you turn the feature flag for the fix off by default. You can enable the flag for customers that reported the original bug. You can then slowly progress through enabling the flag on widening rings of customers until it's turned on for everyone.
- If a fix is introduced when the flag is turned on by default, and the fix has a problem, it can logically be rolled back instantly by switching the flag off.
- Feature flags can also be used to selectively disclose features in preview or to selectively hide features from new customers as part of a deprecation process.
- You can provide visibility of new feature flags and tenant-specific feature flag settings to frontline support and live-site teams. This information helps teams quickly rule in or rule out a new feature change when they investigate an issue. If necessary, teams can also adjust the settings of feature flags to mitigate the issue.
- Finally, you need to manage the lifecycle of feature flags to prevent making the code base unsupportable. Establish a process to remove feature flags from the code after they're fully deployed and proven.
Conclusion
Transitioning from an on-premises product to SaaS requires significant changes in every part of how you deliver software to customers, and in every part of your business. The cultural changes are as significant as the technical changes: moving from an occasional on-premises release cadence to a regular release cadence is a major shift, and adopting a live-site culture and processes takes effort. You need to ensure that your team is well-prepared for the journey and that you expand your talent pool beyond engineers to ensure that you have people who know how to operate SaaS at scale.
Many organizations don’t survive transitions of this magnitude, especially if a new competitor comes along who is natively in the cloud already. To set yourself up for success, you should carefully scope an MVP, get it to production as quickly as possible, and then iterate and improve on it rapidly. The transition process is often the most difficult time, so it’s good to make the transition to the cloud as quickly as possible.
Here are key considerations that we hope you take away from our experiences and some of the decisions you need to make for your own journey.
- Decide on your own path. If you have an existing application with rich functionality and an established on-premises customer base, it can make sense to move to a cloud-based SaaS model. Every product’s journey is different, and you need to consider the decisions and questions separately, based on your own needs. Take inspiration from other journeys, but forge your own path.
- Determine a strategy. Having a product with established customers means you need to decide how to create your priorities. You might focus on building a product that works well for new customers immediately. You might focus on getting your existing customer base migrated to your new service as quickly as possible. The reason you’re moving, and your capacity to make significant changes, influences the direction you take.
- Decide whether you’re going to use a single-cloud or multicloud. Consider whether it makes more sense for you to build on top of a single cloud or to spread your engineering efforts across multiple clouds. If you’re building a platform component, a multicloud strategy can make sense. If you’re building an application, a single-cloud strategy can provide benefits over using a consistent and integrated platform.
- Plan specifically for the cloud. A lift-and-shift approach to migrate to the cloud isn’t sufficient. You need to plan how to take advantage of the elasticity of the cloud, and how to operate a service in a cloud environment. Automation, resiliency, scale, security, performance, and observability are all important considerations. You don’t need to do everything upfront, but you need to know the destination so that you can plan a roadmap.
- Plan specifically for SaaS. A SaaS business model looks different compared to an on-premises software delivery approach. Customers expect trial accounts, understandable billing models, a fully managed service, and dynamic scale based on their needs.
- Land, learn, and iterate. Plan an MVP scope, identify the baseline wins that you can achieve, and then get there fast. Once you’re there, commit to continuous improvement.
- When you’re in the cloud, take advantage of it. The cloud provides many capabilities that on-premises solutions don’t have. The capabilities include massive scale, elasticity, and the ability to use cloud platform components to rapidly create and iterate on your ideas. Consider how you can use technologies like generative AI, microservices, and other approaches that are hard to use outside a cloud environment.
- Become the customer’s IT department. Customer expectations shift when you’re providing an end-to-end service. Plan how you can shift left. Ensure you have a comprehensive monitoring and self-healing capability.
- Learn from customer usage. When you run a service, you collect a large quantity of useful data about how customers use your product. Adopt a data culture. Learn about your customers, what they do, and how they do it. Experiment and be agile enough to change your approach when the data indicates something isn’t as you expect.
- Provide ongoing value through updates. Think about when and how to deploy updates. Plan to fix issues quickly or fall back to previous versions. Decide how to handle breaking changes. Avoid one-off changes for specific customers, because every point of difference is an opportunity for something to go wrong.
The biggest lesson we’ve learned is that the journey to SaaS never ends. A product roadmap is a living document that's constantly evolving. You always have many items in the backlog to improve your product, both for adding new features and for improving how you operate and deliver the product. Delivering SaaS requires continuous improvement to your processes, investment in quality, and vigilance to ensure that you provide a reliable, secure, performant, and trustworthy service for your customers. Advances in technologies, like generative AI, bring along tremendous opportunity for you to provide capabilities that were unimaginable before.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
- Mike Ehrenberg | CTO, Microsoft Dynamics
- John Downs | Principal Program Manager
- Arsen Vladimirsky | Principal Customer Engineer
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for