High availability enterprise deployment using App Service Environment
Note
App Service Environment version 3 is the main component of this architecture. Versions 1 and 2 was retired on August 31, 2024.
Availability zones are physically separated collections of datacenters in a given region. Deploying resources across zones ensures that outages that are limited to a zone don't affect the availability of your applications. This architecture shows how you can improve the resiliency of an App Service Environment deployment by deploying it in a zone-redudant architecture. These zones aren't related to proximity. They can map to different physical locations for different subscriptions. The architecture assumes a single-subscription deployment.
Azure services that support availability zones can be zonal, zone redundant, or both. Zonal services can be deployed to a specific zone. Zone-redundant services can be automatically deployed across zones. For detailed guidance and recommendations, see Availability zone support. App Service Environment supports zone-redundant deployments.
When you configure App Service Environment to be zone redundant, the platform automatically deploys instances of the Azure App Service plan in three zones in the selected region. Therefore, the minimum App Service plan instance count is always three.
 A reference implementation for this architecture is available on GitHub.
A reference implementation for this architecture is available on GitHub.
Architecture
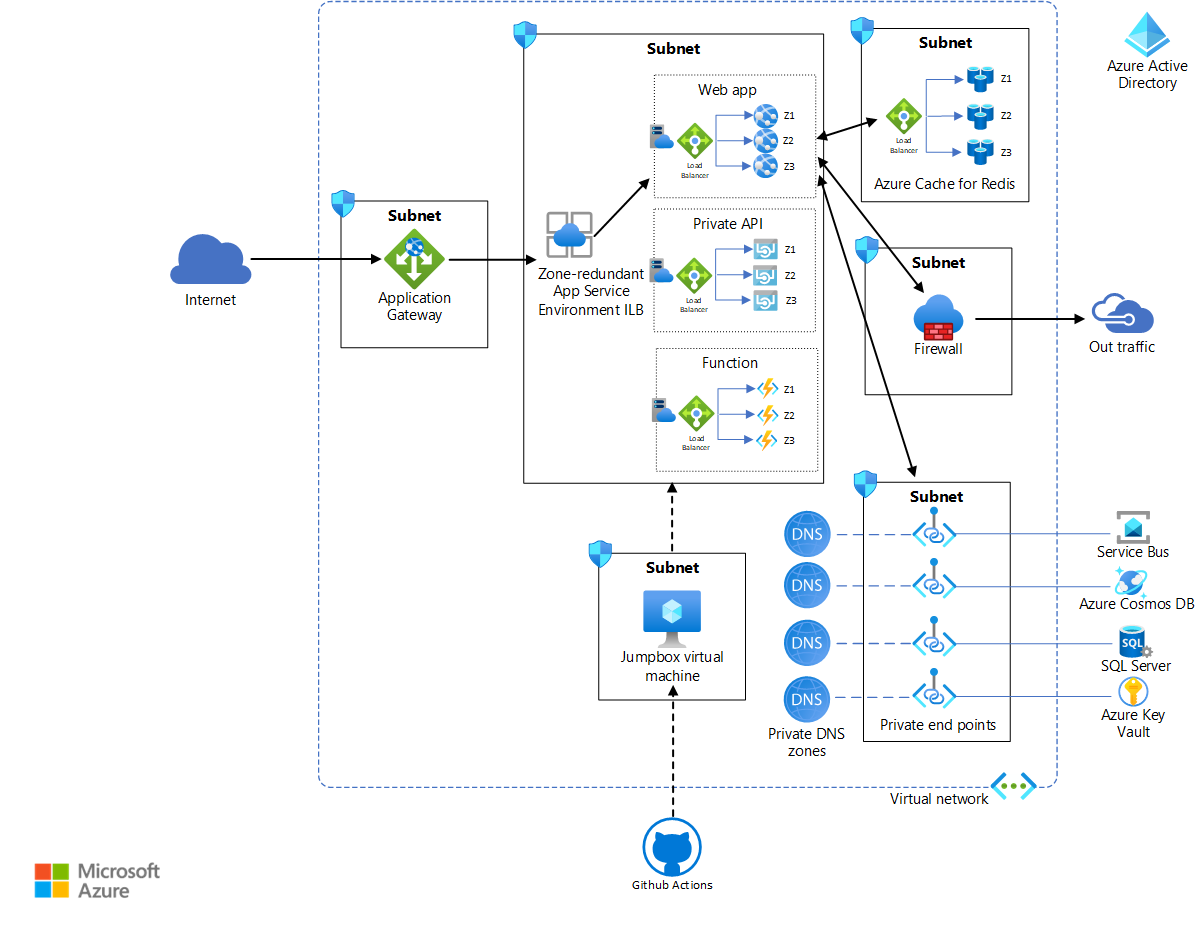
Download a Visio file of this architecture.
The resources in the App Service Environment subnets in this reference implementation are the same as the ones in the standard App Service Environment deployment architecture. This reference implementation uses the zone-redundant capabilities of App Service Environment v3 and Azure Cache for Redis to provide higher availability. Note that the scope of this reference architecture is limited to a single region.
Workflow
This section describes the nature of availability for services used in this architecture:
App Service Environment v3 can be configured for zone redundancy. You can only configure zone redundancy during creation of the App Service Environment and only in regions that support all App Service Environment v3 dependencies. Each App Service plan in a zone-redundant App Service Environment needs to have a minimum of three instances so that they can be deployed in three zones. The minimum charge is for nine instances. For more information, see this pricing guidance. For detailed guidance and recommendations, see App Service Environment Support for Availability Zones.
Azure Virtual Network spans all availability zones that are in a single region. The subnets in the virtual network also cross availability zones. For more information, see the network requirements for App Service Environment.
Application Gateway v2 is zone-redundant. Like the virtual network, it spans multiple availability zones per region. Therefore, a single application gateway is sufficient for a highly available system, as shown in the reference architecture. The reference architecture uses the WAF SKU of Application Gateway, which provides increased protection against common threats and vulnerabilities, based on an implementation of the Core Rule Set (CRS) of the Open Web Application Security Project (OWASP). For more information, see Scaling Application Gateway v2 and WAF v2.
Azure Firewall has built-in support for high availability. It can cross multiple zones without any additional configuration.
If you need to, you can also configure a specific availability zone when you deploy the firewall. See Azure Firewall and Availability Zones for more information. (This configuration isn't used in the reference architecture.)
Microsoft Entra ID is a highly available, highly redundant global service, spanning availability zones and regions. For more information, see Advancing Microsoft Entra availability.
GitHub Actions provides continuous integration and continuous deployment (CI/CD) capabilities in this architecture. Because App Service Environment is in the virtual network, a virtual machine is used as a jumpbox in the virtual network to deploy apps in the App Service plans. The action builds the apps outside the virtual network. For enhanced security and seamless RDP/SSH connectivity, consider using Azure Bastion for the jumpbox.
Azure Cache for Redis is a zone-redundant service. A zone-redundant cache runs on VMs deployed across multiple availability zones. This service provides higher resilience and availability.
Considerations
These considerations implement the pillars of the Azure Well-Architected Framework, which is a set of guiding tenets that can be used to improve the quality of a workload. For more information, see Microsoft Azure Well-Architected Framework.
Reliability
Reliability ensures your application can meet the commitments you make to your customers. For more information, see Design review checklist for Reliability.
Jump boxes
This reference implementation uses the same production-level CI/CD pipeline as the standard deployment, with only one jump box VM. You might, however, decide to use one jump box for each of the three zones. This architecture uses just one jump box because the jump box doesn't affect the availability of the app. The jump box is used only for deployment and testing.
App Service Environment
You can deploy App Service Environment across availability zones to provide resiliency and reliability for your business-critical workloads. This configuration is also known as zone redundancy.
When you implement zone redundancy, the platform automatically deploys the instances of the App Service plan across three zones in the selected region. Therefore, the minimum App Service plan instance count is always three. If you specify a capacity larger than three, and the number of instances is divisible by three, the instances are deployed evenly. Otherwise, any remaining instances are added to the remaining zone or deployed across the remaining two zones.
- You configure availability zones when you create your App Service Environment.
- All App Service plans created in that App Service Environment require a minimum of three instances. They'll automatically be zone redundant.
- You can specify availability zones only when you create a new App Service Environment. You can't convert a pre-existing App Service Environment to use availability zones.
- Availability zones are supported only in a subset of regions.
For more information, see Reliability in Azure App Service.
Resiliency
The applications that run in App Service Environment form the backend pool for Application Gateway. When a request to the application comes from the public internet, the gateway forwards the request to the application running in App Service Environment. This reference architecture implements health checks within the main web frontend, votingApp. This health probe checks whether the web API and the Redis cache are healthy. You can see the code that implements this probe in Startup.cs:
var uriBuilder = new UriBuilder(Configuration.GetValue<string>("ConnectionEndpoints:VotingDataAPIBaseUri"))
{
Path = "/health"
};
services.AddHealthChecks()
.AddUrlGroup(uriBuilder.Uri, timeout: TimeSpan.FromSeconds(15))
.AddRedis(Configuration.GetValue<string>("ConnectionEndpoints:RedisConnectionEndpoint"));
The following code shows how the commands_ha.azcli script configures the backend pools and the health probe for the application gateway:
# Generates parameters file for appgw script
cat <<EOF > appgwApps.parameters.json
[
{
"name": "votapp",
"routingPriority": 100,
"hostName": "${APPGW_APP1_URL}",
"backendAddresses": [
{
"fqdn": "${INTERNAL_APP1_URL}"
}
],
"probePath": "/health"
}
]
If any of the components (the web frontend, the API, or the cache) fails the health probe, Application Gateway routes the request to the other application in the backend pool. This configuration ensures that the request is always routed to the application in a completely available App Service Environment subnet.
The health probe is also implemented in the standard reference implementation. There, the gateway simply returns an error if the health probe fails. However, the highly available implementation improves the resiliency of the application and the quality of the user experience.
Cost Optimization
Cost Optimization is about looking at ways to reduce unnecessary expenses and improve operational efficiencies. For more information, see Design review checklist for Cost Optimization.
The cost considerations for the high availability architecture are similar to those of the standard deployment.
The following differences can affect the cost:
- You're charged for at least nine App Service plan instances in a zone-redundant App Service Environment. For more information, see App Service Environment pricing.
- Azure Cache for Redis is also a zone-redundant service. A zone-redundant cache runs on VMs that are deployed across multiple availability zones to provide higher resilience and availability.
The tradeoff for a highly available, resilient, and highly secure system is increased cost. Use the pricing calculator to evaluate your needs with respect to pricing.
Deploy this scenario
For information about deploying the reference implementation for this architecture, see the GitHub readme. Use the script for high-availability deployment.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal authors:
- Deep Bhattacharya | Cloud Solution Architect
- Suhas Rao | Cloud Solution Architect
To see non-public LinkedIn profiles, sign in to LinkedIn.
Next steps
You can modify this architecture by horizontally scaling your applications, within the same region or across several regions, based on the expected peak load capacity. Replicating your applications on multiple regions might help mitigate the risks of wider geographical datacenter failures, like those caused by earthquakes or other natural disasters. To learn more about horizontal scaling, see Geo Distributed Scale with App Service Environments. For a global and highly available routing solution, consider using Azure Front Door.