This reference architecture provides strategies for the partitioning model that event ingestion services use. Because event ingestion services provide solutions for high-scale event streaming, they need to process events in parallel and be able to maintain event order. They also need to balance loads and offer scalability. Partitioning models meet all of these requirements.
Architecture

At the center of the diagram is a box labeled Kafka Cluster or Event Hub Namespace. Three smaller boxes sit inside that box. Each is labeled Topic or Event Hub, and each contains multiple rectangles labeled Partition. Above the main box are rectangles labeled Producer. Arrows point from the producers to the main box. Below the main box are rectangles labeled Consumer. Arrows point from the main box to the consumers and are labeled with various offset values. A single blue frame labeled Consumer Group surrounds two of the consumers, grouping them together.
Download a Visio file of this architecture.
Dataflow
Producers publish data to the ingestion service, or pipeline. Event Hubs pipelines consist of namespaces. The Kafka equivalents are clusters.
The pipeline distributes incoming events among partitions. Within each partition, events remain in production order. Events don't remain in sequence across partitions, however. The number of partitions can affect throughput, or the amount of data that passes through the system in a set period of time. Pipelines usually measure throughput in bits per second (bps), and sometimes in data packets per second (pps).
Partitions reside within named streams of events. Event Hubs calls these streams event hubs. In Kafka, they're topics.
Consumers are processes or applications that subscribe to topics. Each consumer reads a specific subset of the event stream. That subset can include more than one partition. However, the pipeline can assign each partition to only one consumer per consumer group at a time.
Multiple consumers can make up consumer groups. When a group subscribes to a topic, each consumer in the group has a separate view of the event stream. The applications work independently from each other, at their own pace. The pipeline can also use consumer groups for load sharing.
Consumers process the feed of published events that they subscribe to. Consumers also engage in checkpointing. Through this process, subscribers use offsets to mark their position within a partition event sequence. An offset is a placeholder that works like a bookmark to identify the last event that the consumer read.
Scenario details
Specifically, this document discusses the following strategies:
- How to assign events to partitions.
- How many partitions to use.
- How to assign partitions to subscribers when rebalancing.
Many event ingestion technologies exist, including:
- Azure Event Hubs: A fully managed big data streaming platform.
- Apache Kafka: An open-source stream-processing platform.
- Event Hubs with Kafka: An alternative to running your own Kafka cluster. This Event Hubs feature provides an endpoint that is compatible with Kafka APIs.
Besides offering partitioning strategies, this document also points out differences between partitioning in Event Hubs and Kafka.
Recommendations
Keep the following recommendations in mind when developing a partitioning strategy.
Distribute events to partitions
One aspect of the partitioning strategy is the assignment policy. An event that arrives at an ingestion service goes to a partition. The assignment policy determines that partition.
Each event stores its content in its value. Besides the value, each event also contains a key, as the following diagram shows:

At the center of the diagram are multiple pairs of boxes. A label below the boxes indicates that each pair represents a message. Each message contains a blue box labeled Key and a black box labeled Value. The messages are arranged horizontally. Arrows between messages that point from left to right indicate that the messages form a sequence. Above the messages is the label Stream. Brackets indicate that the sequence forms a stream.
Download a Visio file of this architecture.
The key contains data about the event and can also play a role in the assignment policy.
Multiple approaches exist for assigning events to partitions:
- By default, services distribute events among partitions in a round-robin fashion.
- Producers can specify a partition ID with an event. The event then goes to the partition with that ID.
- Producers can provide a value for the event key. When they do, a hashing-based partitioner determines a hash value from the key. The event then goes to the partition associated with that hash value.
Keep these recommendations in mind when choosing an assignment policy:
- Use partition IDs when consumers are only interested in certain events. When those events flow to a single partition, the consumer can easily receive them by subscribing to that partition.
- Use keys when consumers need to receive events in production order. Since all events with the same key go to the same partition, events with key values can maintain their order during processing. Consumers then receive them in that order.
- With Kafka, if event grouping or ordering isn't required, avoid keys. The producer doesn't know the status of the destination partition in Kafka. If a key routes an event to a partition that's down, delays or lost events can result. In Event Hubs, events with keys first pass through a gateway before proceeding to a partition. This approach prevents events from going to unavailable partitions.
- The shape of the data can influence the partitioning approach. Consider how the downstream architecture will distribute the data when deciding on assignments.
- If consumers aggregate data on a certain attribute, you should partition on that attribute, too.
- When storage efficiency is a concern, partition on an attribute that concentrates the data to help speed up storage operations.
- Ingestion pipelines sometimes shard data to get around problems with resource bottlenecks. In these environments, align the partitioning with how the shards are split in the database.
Determine the number of partitions
Use these guidelines to decide how many partitions to use:
- Use more partitions to achieve more throughput. Each consumer reads from its assigned partition. So with more partitions, more consumers can receive events from a topic at the same time.
- Use at least as many partitions as the value of your target throughput in megabytes.
- To avoid starving consumers, use at least as many partitions as consumers. For instance, suppose eight partitions are assigned to eight consumers. Any additional consumers that subscribe will have to wait. Alternatively, you can keep one or two consumers ready to receive events when an existing consumer fails.
- Use more keys than partitions. Otherwise, some partitions won't receive any events, leading to unbalanced partition loads.
- In both Kafka and Event Hubs at the Dedicated tier level, you can change the number of partitions in an operating system. However, avoid making that change if you use keys to preserve event ordering. The reason involves the following facts:
- Consumers rely on certain partitions and the order of the events they contain.
- When the number of partitions changes, the mapping of events to partitions can change. For instance, when the partition count changes, this formula can produce a different assignment:
partition assignment = hash key % number of partitions - Kafka and Event Hubs don't attempt to redistribute events that arrived at partitions before the shuffle. As a result, the guarantee no longer holds that events arrive at a certain partition in publication order.
Besides these guidelines, you can also use this rough formula to determine the number of partitions:
max(t/p, t/c)
It uses the following values:
t: The target throughput.p: The production throughput on a single partition.c: The consumption throughput on a single partition.
For example, consider this situation:
- The ideal throughput is 2 MBps. For the formula,
tis 2 MBps. - A producer sends events at a rate of 1,000 events per second, making
p1 MBps. - A consumer receives events at a rate of 500 events per second, setting
cto 0.5 MBps.
With these values, the number of partitions is 4:
max(t/p, t/c) = max(2/1, 2/0.5) = max(2, 4) = 4
When measuring throughput, keep these points in mind:
The slowest consumer determines the consumption throughput. However, sometimes no information is available about downstream consumer applications. In this case, estimate the throughput by starting with one partition as a baseline. (Use this setup only in testing environments, not in production systems). Event Hubs with Standard tier pricing and one partition should produce throughput between 1 MBps and 20 MBps.
Consumers can consume events from an ingestion pipeline at a high rate only if producers send events at a comparable rate. To determine the total required capacity of the ingestion pipeline, measure the producer's throughput, not just the consumer's.
Assign partitions to consumers when rebalancing
When consumers subscribe or unsubscribe, the pipeline rebalances the assignment of partitions to consumers. By default, Event Hubs and Kafka use a round robin approach for rebalancing. This method distributes partitions evenly across members.
With Kafka, if you don't want the pipeline to automatically rebalance assignments, you can statically assign partitions to consumers. But you need to make sure that all partitions have subscribers and that the loads are balanced.
Besides the default round robin strategy, Kafka offers two other strategies for automatic rebalancing:
- Range assignor: Use this approach to bring together partitions from different topics. This assignment identifies topics that use the same number of partitions and the same key-partitioning logic. Then it joins partitions from those topics when making assignments to consumers.
- Sticky assignor: Use this assignment to minimize partition movement. Like round robin, this strategy ensures a uniform distribution. However, it also preserves existing assignments during rebalancing.
Considerations
Keep these points in mind when using a partitioning model.
Scalability
Using a large number of partitions can limit scalability:
In Kafka, brokers store event data and offsets in files. The more partitions you use, the more open file handles you'll have. If the operating system limits the number of open files, you may need to reconfigure that setting.
In Event Hubs, users don't face file system limitations. However, each partition manages its own Azure blob files and optimizes them in the background. A large number of partitions makes it expensive to maintain checkpoint data. The reason is that I/O operations can be time-consuming, and the storage API calls are proportional to the number of partitions.
Each producer for Kafka and Event Hubs stores events in a buffer until a sizeable batch is available or until a specific amount of time passes. Then the producer sends the events to the ingestion pipeline. The producer maintains a buffer for each partition. When the number of partitions increases, the memory requirement of the client also expands. If consumers receive events in batches, they may also face the same issue. When consumers subscribe to a large number of partitions but have limited memory available for buffering, problems can arise.
Availability
A significant number of partitions can also adversely affect availability:
Kafka generally positions partitions on different brokers. When a broker fails, Kafka rebalances the partitions to avoid losing events. The more partitions there are to rebalance, the longer the failover takes, increasing unavailability. Limit the number of partitions to the low thousands to avoid this issue.
The more partitions you use, the more physical resources you put in operation. Depending on the client response, more failures can then occur.
With more partitions, the load-balancing process has to work with more moving parts and more stress. Transient exceptions can result. These errors can occur when there are temporary disturbances, such as network issues or intermittent internet service. They can appear during an upgrade or load balancing, when Event Hubs sometimes moves partitions to different nodes. Handle transient behavior by incorporating retries to minimize failures. Use the EventProcessorClient in the .NET and Java SDKs or the EventHubConsumerClient in the Python and JavaScript SDKs to simplify this process.
Performance
In Kafka, events are committed after the pipeline has replicated them across all in-sync replicas. This approach ensures a high availability of events. Since consumers only receive committed events, the replication process adds to the latency. In ingestion pipelines, this term refers to the time between when a producer publishes an event and a consumer reads it. According to experiments that Confluent ran, replicating 1,000 partitions from one broker to another can take about 20 milliseconds. The end-to-end latency is then at least 20 milliseconds. When the number of partitions increases further, the latency also grows. This drawback doesn't apply to Event Hubs.
Security
In Event Hubs, publishers use a Shared Access Signature (SAS) token to identify themselves. Consumers connect via an AMQP 1.0 session. This state-aware bidirectional communication channel provides a secure way to transfer messages. Kafka also offers encryption, authorization, and authentication features, but you have to implement them yourself.
Deploy this scenario
The following code examples demonstrate how to maintain throughput, distribute to a specific partition, and preserve event order.
Maintain throughput
This example involves log aggregation. The goal isn't to process events in order, but rather, to maintain a specific throughput.
A Kafka client implements the producer and consumer methods. Since order isn't important, the code doesn't send messages to specific partitions. Instead, it uses the default partitioning assignment:
public static void RunProducer(string broker, string connectionString, string topic)
{
// Set the configuration values of the producer.
var producerConfig = new ProducerConfig
{
BootstrapServers = broker,
SecurityProtocol = SecurityProtocol.SaslSsl,
SaslMechanism = SaslMechanism.Plain,
SaslUsername = "$ConnectionString",
SaslPassword = connectionString,
};
// Set the message key to Null since the code does not use it.
using (var p = new ProducerBuilder<Null, string>(producerConfig).Build())
{
try
{
// Send a fixed number of messages. Use the Produce method to generate
// many messages in rapid succession instead of the ProduceAsync method.
for (int i=0; i < NumOfMessages; i++)
{
string value = "message-" + i;
Console.WriteLine($"Sending message with key: not-specified," +
$"value: {value}, partition-id: not-specified");
p.Produce(topic, new Message<Null, string> { Value = value });
}
// Wait up to 10 seconds for any in-flight messages to be sent.
p.Flush(TimeSpan.FromSeconds(10));
}
catch (ProduceException<Null, string> e)
{
Console.WriteLine($"Delivery failed with error: {e.Error.Reason}");
}
}
}
public static void RunConsumer(string broker, string connectionString, string consumerGroup, string topic)
{
var consumerConfig = new ConsumerConfig
{
BootstrapServers = broker,
SecurityProtocol = SecurityProtocol.SaslSsl,
SocketTimeoutMs = 60000,
SessionTimeoutMs = 30000,
SaslMechanism = SaslMechanism.Plain,
SaslUsername = "$ConnectionString",
SaslPassword = connectionString,
GroupId = consumerGroup,
AutoOffsetReset = AutoOffsetReset.Earliest
};
using (var c = new ConsumerBuilder<string, string>(consumerConfig).Build())
{
c.Subscribe(topic);
CancellationTokenSource cts = new CancellationTokenSource();
Console.CancelKeyPress += (_, e) =>
{
e.Cancel = true;
cts.Cancel();
};
try
{
while (true)
{
try
{
var message = c.Consume(cts.Token);
Console.WriteLine($"Consumed - key: {message.Message.Key}, "+
$"value: {message.Message.Value}, " +
$"partition-id: {message.Partition}," +
$"offset: {message.Offset}");
}
catch (ConsumeException e)
{
Console.WriteLine($"Error occurred: {e.Error.Reason}");
}
}
}
catch(OperationCanceledException)
{
// Close the consumer to ensure that it leaves the group cleanly
// and that final offsets are committed.
c.Close();
}
}
}
This code example produces the following results:
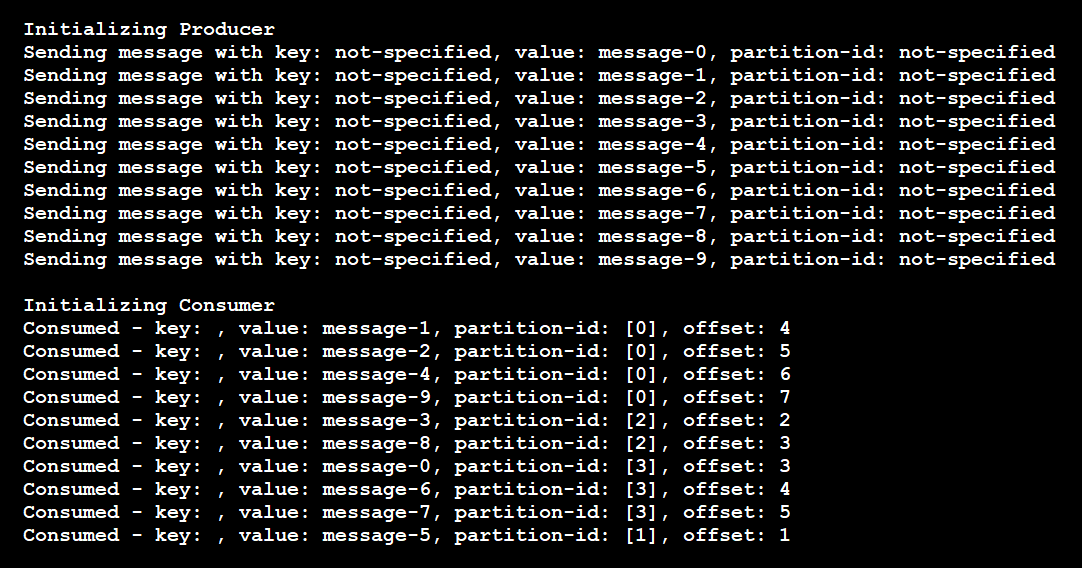
In this case, the topic has four partitions. The following events took place:
- The producer sent 10 messages, each without a partition key.
- The messages arrived at partitions in a random order.
- A single consumer listened to all four partitions and received the messages out of order.
If the code had used two instances of the consumer, each instance would have subscribed to two of the four partitions.
Distribute to a specific partition
This example involves error messages. Suppose certain applications need to process error messages, but all other messages can go to a common consumer. In this case, the producer sends error messages to a specific partition. Consumers who want to receive error messages listen to that partition. The following code shows how to implement this scenario:
// Producer code.
var topicPartition = new TopicPartition(topic, partition);
...
p.Produce(topicPartition, new Message<Null, string> { Value = value });
// Consumer code.
// Subscribe to one partition.
c.Assign(new TopicPartition(topic, partition));
// Use this code to subscribe to a list of partitions.
c.Assign(new List<TopicPartition> {
new TopicPartition(topic, partition1),
new TopicPartition(topic, partition2)
});
As these results show, the producer sent all messages to partition 2, and the consumer only read messages from partition 2:
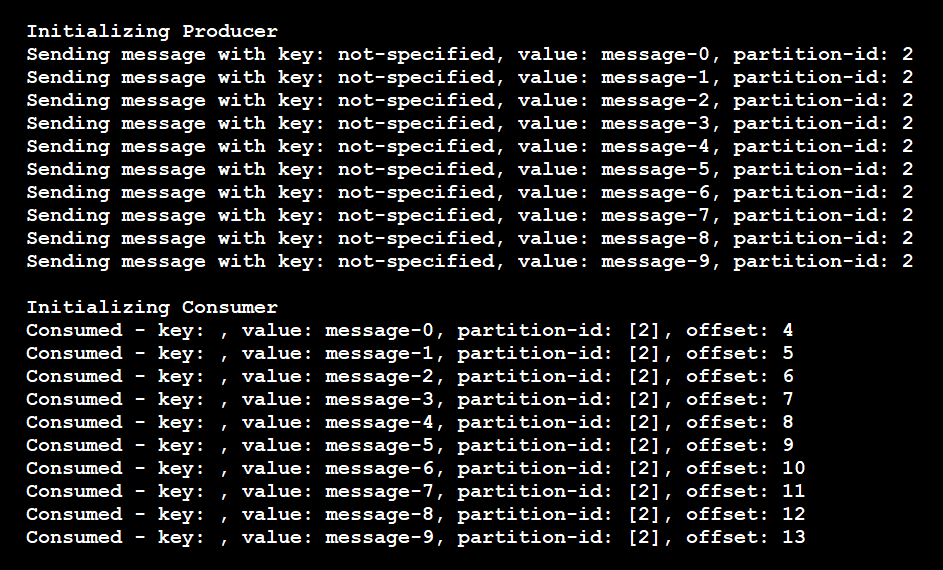
In this scenario, if you add another consumer instance to listen to this topic, the pipeline won't assign any partitions to it. The new consumer will starve until the existing consumer shuts down. The pipeline will then assign a different, active consumer to read from the partition. But the pipeline will only make that assignment if the new consumer isn't dedicated to another partition.
Preserve event order
This example involves bank transactions that a consumer needs to process in order. In this scenario, you can use the customer ID of each event as the key. For the event value, use the details of the transaction. The following code shows a simplified implementation of this case:
Producer code
// This code assigns the key an integer value. You can also assign it any other valid key value.
using (var p = new ProducerBuilder<int, string>(producerConfig).Build())
...
p.Produce(topic, new Message<int, string> { Key = i % 2, Value = value });
This code produces the following results:
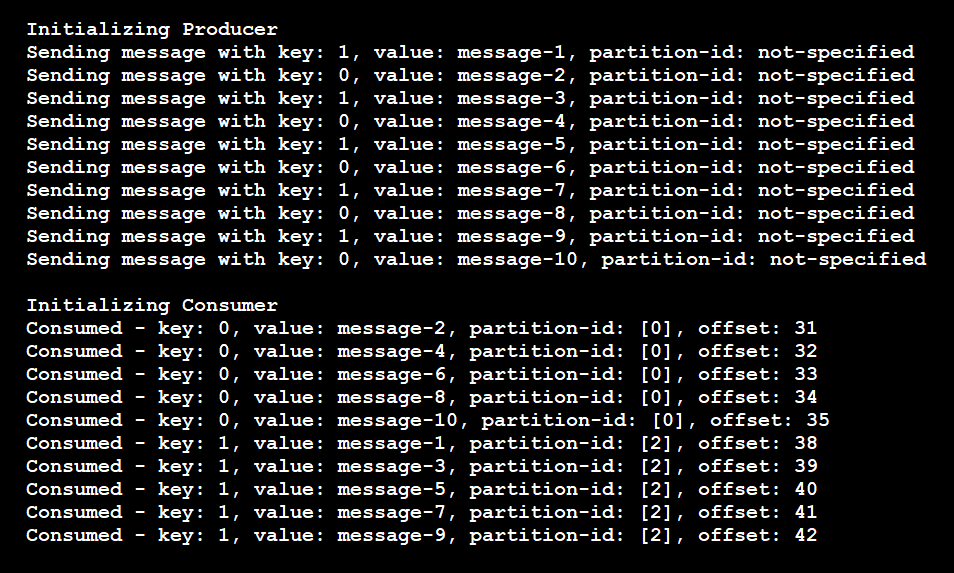
As these results show, the producer only used two unique keys. The messages then went to only two partitions instead of all four. The pipeline guarantees that messages with the same key go to the same partition.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal author:
- Rajasa Savant | Senior Software Engineer
To see non-public LinkedIn profiles, sign in to LinkedIn.
Next steps
- Use Azure Event Hubs from Apache Kafka applications
- Apache Kafka developer guide for Azure Event Hubs
- Quickstart: Data streaming with Event Hubs using the Kafka protocol
- Send events to and receive events from Azure Event Hubs - .NET (Azure.Messaging.EventHubs)
- Balance partition load across multiple instances of your application
- Dynamically add partitions to an event hub (Apache Kafka topic) in Azure Event Hubs
- Availability and consistency in Event Hubs
- Azure Event Hubs Event Processor client library for .NET
- Effective strategies for Kafka topic partitioning
- Confluent blog post: How to choose the number of topics/partitions in a Kafka cluster?