Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Resiliency and disaster recovery is a common need for online systems. Azure SignalR Service already provides 99.9% availability, however it's still a regional service. When there's a region-wide outage, your service instance doesn't fail over to another region because it's always running in the one region.
For regional disaster recovery, we recommend the following two approaches:
- Enable Geo-Replication (Easy way). This feature handles regional failover for you automatically. When enabled, there's only one Azure SignalR instance and no code changes are introduced. Check geo-replication for details.
- Utilize Multiple Endpoints in Service SDK. Our service SDK supports multiple SignalR service instances and automatically switches to other instances when some of them are unavailable. With this feature, you're able to recover when a disaster takes place, but you need to set up the right system topology by yourself. You learn how to do so in this document.
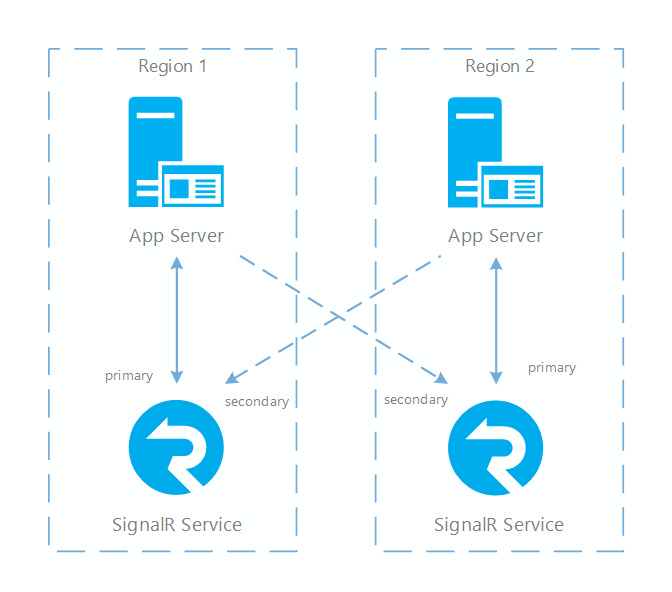
High available architecture for SignalR service
To ensure cross region resiliency for SignalR service, you need to set up multiple service instances in different regions. So when one region is down, the others can be used as backup. When app servers connect to multiple service instances, there are two roles, primary and secondary. Primary is an instance responsible for receiving online traffic, while secondary serves as a fallback instance that is fully functional. In our SDK implementation, negotiate only returns primary endpoints, so clients only connect to primary endpoints in normal cases. But when primary instance is down, negotiate returns secondary endpoints so client can still make connections. Primary instance and app server are connected through normal server connections but secondary instance and app server are connected through a special type of connection called weak connection. One distinguishing characteristic of a weak connection is that it's unable to accept client connection routing due to the location of secondary instance in another region. Routing a client to another region isn't an optimal choice (increases latency).
One service instance can have different roles when connecting to multiple app servers. One typical setup for cross region scenario is to have two or more pairs of SignalR service instances and app servers. Inside each pair app server and SignalR service are located in the same region, and SignalR service is connected to the app server as a primary role. Between each pairs app server and SignalR service are also connected, but SignalR becomes a secondary when connecting to server in another region.
With this topology, message from one server can still be delivered to all clients as all app servers and SignalR service instances are interconnected. But when a client is connected, it routes to the app server in the same region to achieve optimal network latency.
The following diagram illustrates such topology:
Configure multiple SignalR service instances
Multiple SignalR service instances are supported on both app servers and Azure Functions.
Once you have SignalR service and app servers/Azure Functions created in each region, you can configure your app servers/Azure Functions to connect to all SignalR service instances.
Through config
You should already know how to set SignalR service connection string through environment variables/app settings/web.config, in a config entry named Azure:SignalR:ConnectionString.
If you have multiple endpoints, you can set them in multiple config entries, each in the following format:
Azure:SignalR:ConnectionString:<name>:<role>
In the ConnectionString, <name> is the name of the endpoint and <role> is its role (primary or secondary).
Name is optional but it's useful if you want to further customize the routing behavior among multiple endpoints.
Through code
If you prefer to store the connection strings somewhere else, you can also read them in your code and use them as parameters when calling AddAzureSignalR() (in ASP.NET Core) or MapAzureSignalR() (in ASP.NET).
Here's the sample code:
ASP.NET Core:
services.AddSignalR()
.AddAzureSignalR(options => options.Endpoints = new ServiceEndpoint[]
{
new ServiceEndpoint("<connection_string1>", EndpointType.Primary, "region1"),
new ServiceEndpoint("<connection_string2>", EndpointType.Secondary, "region2"),
});
ASP.NET:
app.MapAzureSignalR(GetType().FullName, hub, options => options.Endpoints = new ServiceEndpoint[]
{
new ServiceEndpoint("<connection_string1>", EndpointType.Primary, "region1"),
new ServiceEndpoint("<connection_string2>", EndpointType.Secondary, "region2"),
};
You can configure multiple primary or secondary instances. If there are multiple primary and/or secondary instances, negotiate returns an endpoint in the following order:
- If there is at least one primary instance online, return a random primary online instance.
- If all primary instances are down, return a random secondary online instance.
For Azure Functions SignalR bindings
To enable multiple SignalR Service instances, you should:
Use
Persistenttransport type.The default transport type is
Transientmode. You should add the following entry to yourlocal.settings.jsonfile or the application setting on Azure.{ "AzureSignalRServiceTransportType":"Persistent" }Note
When switching from
Transientmode toPersistentmode, there may be JSON serialization behavior change, because underTransientmode,Newtonsoft.Jsonlibrary is used to serialize arguments of hub methods, however, underPersistentmode,System.Text.Jsonlibrary is used as default.System.Text.Jsonhas some key differences in default behavior withNewtonsoft.Json. If you want to useNewtonsoft.JsonunderPersistentmode, you can add a configuration item:"Azure:SignalR:HubProtocol":"NewtonsoftJson"inlocal.settings.jsonfile orAzure__SignalR__HubProtocol=NewtonsoftJsonon Azure portal.Configure multiple SignalR Service endpoints entries in your configuration.
We use a
ServiceEndpointobject to represent a SignalR Service instance. You can define a service endpoint with its<EndpointName>and<EndpointType>in the entry key, and the connection string in the entry value. The keys are in the following format:Azure:SignalR:Endpoints:<EndpointName>:<EndpointType><EndpointType>is optional and defaults toprimary. See samples below:{ "Azure:SignalR:Endpoints:EastUs":"<ConnectionString>", "Azure:SignalR:Endpoints:EastUs2:Secondary":"<ConnectionString>", "Azure:SignalR:Endpoints:WestUs:Primary":"<ConnectionString>" }Note
When you configure Azure SignalR endpoints in the App Service on Azure portal, don't forget to replace
":"with"__", the double underscore in the keys. For reasons, see Environment variables.Connection string configured with the key
{ConnectionStringSetting}(defaults to "AzureSignalRConnectionString") is also recognized as a primary service endpoint with empty name. But this configuration style is not recommended for multiple endpoints.
For Management SDK
Add multiple endpoints from config
Configure with key Azure:SignalR:Endpoints for SignalR Service connection string. The key should be in the format Azure:SignalR:Endpoints:{Name}:{EndpointType}, where Name and EndpointType are properties of the ServiceEndpoint object, and are accessible from code.
You can add multiple instance connection strings using the following dotnet commands:
dotnet user-secrets set Azure:SignalR:Endpoints:east-region-a <ConnectionString1>
dotnet user-secrets set Azure:SignalR:Endpoints:east-region-b:primary <ConnectionString2>
dotnet user-secrets set Azure:SignalR:Endpoints:backup:secondary <ConnectionString3>
Add multiple endpoints from code
A ServiceEndpoint class describes the properties of an Azure SignalR Service endpoint.
You can configure multiple instance endpoints when using Azure SignalR Management SDK through:
var serviceManager = new ServiceManagerBuilder()
.WithOptions(option =>
{
options.Endpoints = new ServiceEndpoint[]
{
// Note: this is just a demonstration of how to set options.Endpoints
// Having ConnectionStrings explicitly set inside the code is not encouraged
// You can fetch it from a safe place such as Azure KeyVault
new ServiceEndpoint("<ConnectionString0>"),
new ServiceEndpoint("<ConnectionString1>", type: EndpointType.Primary, name: "east-region-a"),
new ServiceEndpoint("<ConnectionString2>", type: EndpointType.Primary, name: "east-region-b"),
new ServiceEndpoint("<ConnectionString3>", type: EndpointType.Secondary, name: "backup"),
};
})
.BuildServiceManager();
Failover sequence and best practice
Now you have the right system topology setup. Whenever one SignalR service instance is down, online traffic is routed to other instances. Here's what happens when a primary instance is down (and recovers after some time):
- Primary service instance is down, all server connections on this instance drop.
- All servers connected to this instance mark it as offline, and negotiate stops returning this endpoint and start returning secondary endpoint.
- All client connections on this instance are also closed, clients then reconnect. Since app servers now return secondary endpoint, clients connect to secondary instance.
- Now secondary instance takes all online traffic. All messages from server to clients can still be delivered as secondary is connected to all app servers. But client to server messages are only routed to the app server in the same region.
- After primary instance is recovered and back online, app server will reestablish connections to it and mark it as online. Negotiate now returns primary endpoint again so new clients are connected back to primary. But existing clients don't drop and are still routed to secondary until they disconnect themselves.
Below diagrams illustrate how failover is done in SignalR service:
Fig.1 Before failover
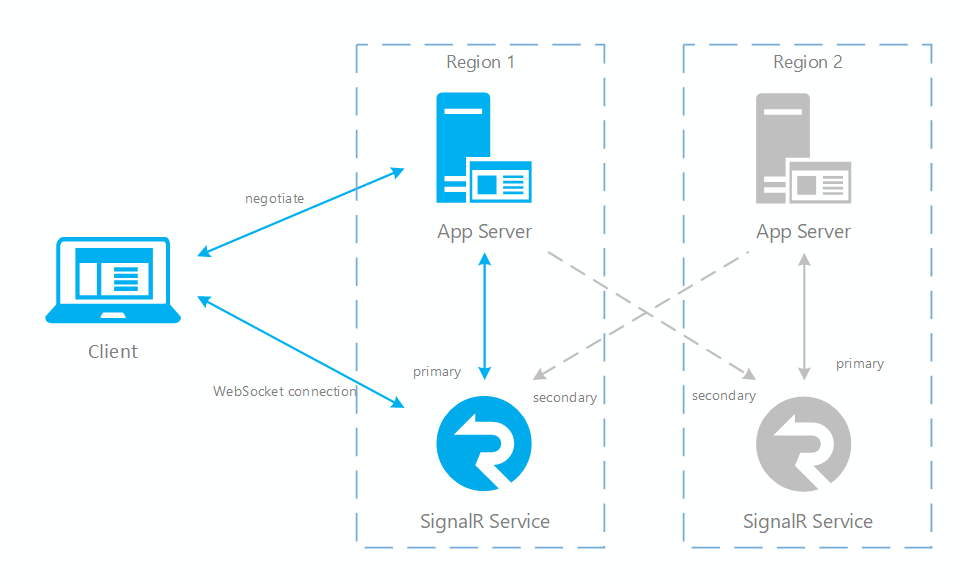
Fig.2 After failover
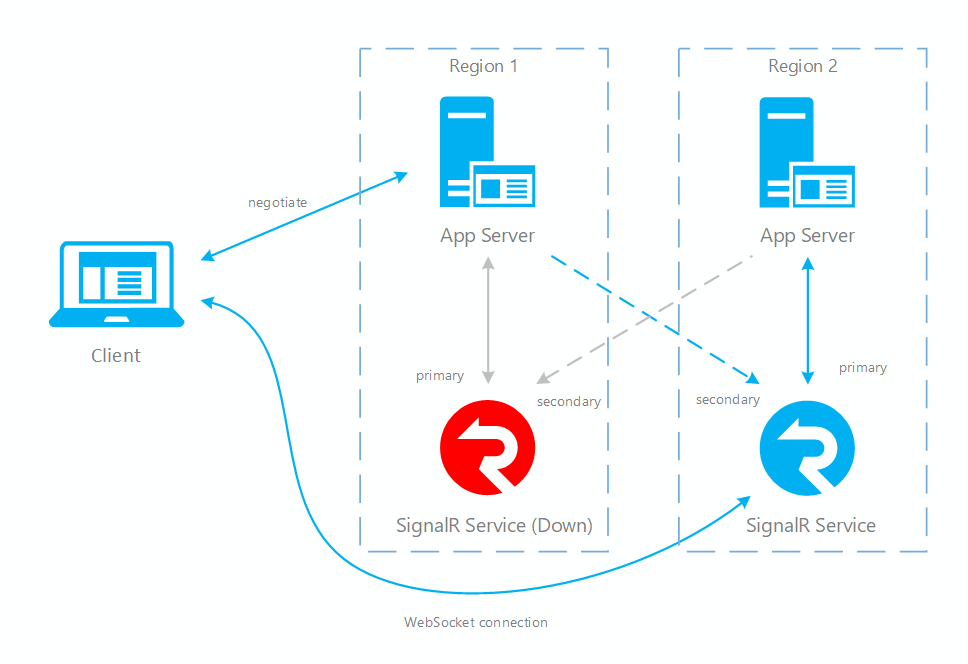
Fig.3 Short time after primary recovers
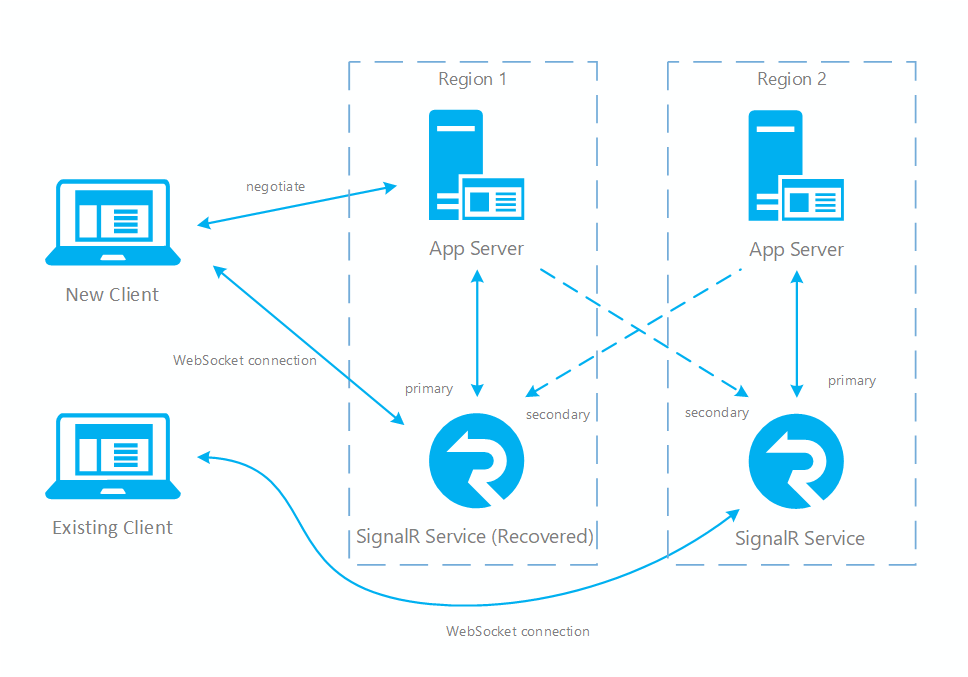
You can see in normal case only primary app server and SignalR service have online traffic (in blue). After failover, secondary app server and SignalR service also become active. After primary SignalR service is back online, new clients will connect to primary SignalR. But existing clients still connect to secondary so both instances have traffic. After all existing clients disconnect, your system will be back to normal (Fig.1).
There are two main patterns for implementing a cross region high available architecture:
- The first one is to have a pair of app server and SignalR service instance taking all online traffic, and have another pair as a backup (called active/passive, illustrated in Fig.1).
- The other one is to have two (or more) pairs of app servers and SignalR service instances, each one taking part of the online traffic and serves as backup for other pairs (called active/active, similar to Fig.3).
SignalR service can support both patterns, the main difference is how you implement app servers. If app servers are active/passive, SignalR service is also active/passive (as the primary app server only returns its primary SignalR service instance). If app servers are active/active, SignalR service is also active/active (as all app servers return their own primary SignalR instances, so all of them can get traffic).
Be noted no matter which patterns you choose to use, you need to connect each SignalR service instance to an app server as primary.
Also due to the nature of SignalR connection (it's a long connection), clients experience connection drops when there's a disaster and failover take place. You need to handle such cases at client side to make it transparent to your end customers. For example, do reconnect after a connection is closed.
How to test a failover
Follow the steps to trigger the failover:
- In the Networking tab for the primary resource in the portal, disable public network access. If the resource has private network enabled, use access control rules to deny all the traffic.
- Restart the primary resource.
Next steps
In this article, you learned how to configure your application to achieve resiliency for SignalR service. To understand more details about server/client connection and connection routing in SignalR service, you can read this article for SignalR service internals.
For scaling scenarios such as sharding that uses multiple instances together to handle large number of connections read how to scale multiple instances.
For details on how to configure Azure Functions with multiple SignalR service instances, read multiple Azure SignalR Service instances support in Azure Functions.