Moving data between scaled-out cloud databases
Applies to: ![]() Azure SQL Database
Azure SQL Database
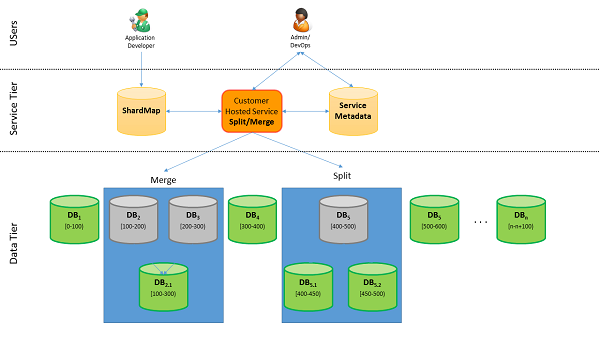
If you are a Software as a Service developer, and suddenly your app undergoes tremendous demand, you need to accommodate the growth. So you add more databases (shards). How do you redistribute the data to the new databases without disrupting the data integrity? Use the split-merge tool to move data from constrained databases to the new databases.
The split-merge tool runs as an Azure web service. An administrator or developer uses the tool to move shardlets (data from a shard) between different databases (shards). The tool uses shard map management to maintain the service metadata database, and ensure consistent mappings.
Download
Microsoft.Azure.SqlDatabase.ElasticScale.Service.SplitMerge
Documentation
- Elastic database split-merge tool tutorial
- Split-merge security configuration
- Split-merge security considerations
- Shard map management
- Migrate existing databases to scale-out
- Elastic database tools
- Elastic database tools glossary
Why use the split-merge tool
Flexibility
Applications need to stretch flexibly beyond the limits of a single database in Azure SQL Database. Use the tool to move data as needed to new databases while retaining integrity.
Split to grow
To increase overall capacity to handle explosive growth, create additional capacity by sharding the data and by distributing it across incrementally more databases until capacity needs are fulfilled. This is a prime example of the split feature.
Merge to shrink
Capacity needs shrink due to the seasonal nature of a business. The tool lets you scale down to fewer scale units when business slows. The merge feature in the Elastic Scale Split-Merge Service covers this requirement.
Manage hotspots by moving shardlets
With multiple tenants per database, the allocation of shardlets to shards can lead to capacity bottlenecks on some shards. This requires re-allocating shardlets or moving busy shardlets to new or less utilized shards.
Concepts & key features
Customer-hosted services
The split-merge is delivered as a customer-hosted service. You must deploy and host the service in your Microsoft Azure subscription. The package you download from NuGet contains a configuration template to complete with the information for your specific deployment. See the split-merge tutorial for details. Since the service runs in your Azure subscription, you can control and configure most security aspects of the service. The default template includes the options to configure TLS, certificate-based client authentication, encryption for stored credentials, DoS guarding and IP restrictions. You can find more information on the security aspects in the following document split-merge security configuration.
The default deployed service runs with one worker and one web role. Each uses the A1 VM size in Azure Cloud Services. While you cannot modify these settings when deploying the package, you could change them after a successful deployment in the running cloud service, (through the Azure portal). Note that the worker role must not be configured for more than a single instance for technical reasons.
Shard map integration
The split-merge service interacts with the shard map of the application. When using the split-merge service to split or merge ranges or to move shardlets between shards, the service automatically keeps the shard map up-to-date. To do so, the service connects to the shard map manager database of the application and maintains ranges and mappings as split/merge/move requests progress. This ensures that the shard map always presents an up-to-date view when split-merge operations are going on. Split, merge and shardlet movement operations are implemented by moving a batch of shardlets from the source shard to the target shard. During the shardlet movement operation the shardlets subject to the current batch are marked as offline in the shard map and are unavailable for data-dependent routing connections using the OpenConnectionForKey API.
Consistent shardlet connections
When data movement starts for a new batch of shardlets, any shard-map provided data-dependent routing connections to the shard storing the shardlet are killed and subsequent connections from the shard map APIs to the shardlets are blocked while the data movement is in progress in order to avoid inconsistencies. Connections to other shardlets on the same shard will also get killed, but will succeed again immediately on retry. Once the batch is moved, the shardlets are marked online again for the target shard and the source data is removed from the source shard. The service goes through these steps for every batch until all shardlets have been moved. This will lead to several connection kill operations during the course of the complete split/merge/move operation.
Managing shardlet availability
Limiting the connection killing to the current batch of shardlets as discussed above restricts the scope of unavailability to one batch of shardlets at a time. This is preferred over an approach where the complete shard would remain offline for all its shardlets during the course of a split or merge operation. The size of a batch, defined as the number of distinct shardlets to move at a time, is a configuration parameter. It can be defined for each split and merge operation depending on the application's availability and performance needs. Note that the range that is being locked in the shard map may be larger than the batch size specified. This is because the service picks the range size such that the actual number of sharding key values in the data approximately matches the batch size. This is important to remember in particular for sparsely populated sharding keys.
Metadata storage
The split-merge service uses a database to maintain its status and to keep logs during request processing. The user creates this database in their subscription and provides the connection string for it in the configuration file for the service deployment. Administrators from the user's organization can also connect to this database to review request progress and to investigate detailed information regarding potential failures.
Sharding-awareness
The split-merge service differentiates between (1) sharded tables, (2) reference tables, and (3) normal tables. The semantics of a split/merge/move operation depend on the type of the table used and are defined as follows:
Sharded tables
Split, merge, and move operations move shardlets from source to target shard. After successful completion of the overall request, those shardlets are no longer present on the source. Note that the target tables need to exist on the target shard and must not contain data in the target range prior to processing of the operation.
Reference tables
For reference tables, the split, merge and move operations copy the data from the source to the target shard. Note, however, that no changes occur on the target shard for a given table if any row is already present in this table on the target. The table has to be empty for any reference table copy operation to get processed.
Other tables
Other tables can be present on either the source or the target of a split and merge operation. The split-merge service disregards these tables for any data movement or copy operations. Note, however, that they can interfere with these operations in case of constraints.
The information on reference vs. sharded tables is provided by the
SchemaInfoAPIs on the shard map. The following example illustrates the use of these APIs on a given shard map manager object:// Create the schema annotations SchemaInfo schemaInfo = new SchemaInfo(); // reference tables schemaInfo.Add(new ReferenceTableInfo("dbo", "region")); schemaInfo.Add(new ReferenceTableInfo("dbo", "nation")); // sharded tables schemaInfo.Add(new ShardedTableInfo("dbo", "customer", "C_CUSTKEY")); schemaInfo.Add(new ShardedTableInfo("dbo", "orders", "O_CUSTKEY")); // publish smm.GetSchemaInfoCollection().Add(Configuration.ShardMapName, schemaInfo);The tables
regionandnationare defined as reference tables and will be copied with split/merge/move operations.customerandordersin turn are defined as sharded tables.C_CUSTKEYandO_CUSTKEYserve as the sharding key.
Referential integrity
The split-merge service analyzes dependencies between tables and uses foreign key-primary key relationships to stage the operations for moving reference tables and shardlets. In general, reference tables are copied first in dependency order, then shardlets are copied in order of their dependencies within each batch. This is necessary so that FK-PK constraints on the target shard are honored as the new data arrives.
Shard map consistency and eventual completion
In the presence of failures, the split-merge service resumes operations after any outage and aims to complete any in progress requests. However, there may be unrecoverable situations, e.g., when the target shard is lost or compromised beyond repair. Under those circumstances, some shardlets that were supposed to be moved may continue to reside on the source shard. The service ensures that shardlet mappings are only updated after the necessary data has been successfully copied to the target. Shardlets are only deleted on the source once all their data has been copied to the target and the corresponding mappings have been updated successfully. The deletion operation happens in the background while the range is already online on the target shard. The split-merge service always ensures correctness of the mappings stored in the shard map.
The split-merge user interface
The split-merge service package includes a worker role and a web role. The web role is used to submit split-merge requests in an interactive way. The main components of the user interface are as follows:
Operation type
The operation type is a radio button that controls the kind of operation performed by the service for this request. You can choose between the split, merge and move scenarios. You can also cancel a previously submitted operation. You can use split, merge and move requests for range shard maps. List shard maps only support move operations.
Shard map
The next section of request parameters covers information about the shard map and the database hosting your shard map. In particular, you need to provide the name of the server and database hosting the shardmap, credentials to connect to the shard map database, and finally the name of the shard map. Currently, the operation only accepts a single set of credentials. These credentials need to have sufficient permissions to perform changes to the shard map as well as to the user data on the shards.
Source range (split and merge)
A split and merge operation processes a range using its low and high key. To specify an operation with an unbounded high key value, check the "High key is max" check box and leave the high key field empty. The range key values that you specify do not need to precisely match a mapping and its boundaries in your shard map. If you do not specify any range boundaries at all the service will infer the closest range for you automatically. You can use the GetMappings.ps1 PowerShell script to retrieve the current mappings in a given shard map.
Split source behavior (split)
For split operations, define the point to split the source range. You do this by providing the sharding key where you want the split to occur. Use the radio button specify whether you want the lower part of the range (excluding the split key) to move, or whether you want the upper part to move (including the split key).
Source shardlet (move)
Move operations are different from split or merge operations as they do not require a range to describe the source. A source for move is simply identified by the sharding key value that you plan to move.
Target shard (split)
Once you have provided the information on the source of your split operation, you need to define where you want the data to be copied to by providing the server and database name for the target.
Target range (merge)
Merge operations move shardlets to an existing shard. You identify the existing shard by providing the range boundaries of the existing range that you want to merge with.
Batch size
The batch size controls the number of shardlets that will go offline at a time during the data movement. This is an integer value where you can use smaller values when you are sensitive to long periods of downtime for shardlets. Larger values will increase the time that a given shardlet is offline but may improve performance.
Operation ID (cancel)
If you have an ongoing operation that is no longer needed, you can cancel the operation by providing its operation ID in this field. You can retrieve the operation ID from the request status table (see Section 8.1) or from the output in the web browser where you submitted the request.
Requirements and limitations
The current implementation of the split-merge service is subject to the following requirements and limitations:
- The shards need to exist and be registered in the shard map before a split-merge operation on these shards can be performed.
- The service does not create tables or any other database objects automatically as part of its operations. This means that the schema for all sharded tables and reference tables needs to exist on the target shard prior to any split/merge/move operation. Sharded tables in particular are required to be empty in the range where new shardlets are to be added by a split/merge/move operation. Otherwise, the operation will fail the initial consistency check on the target shard. Also note that reference data is only copied if the reference table is empty and that there are no consistency guarantees with regard to other concurrent write operations on the reference tables. We recommend this: when running split/merge operations, no other write operations make changes to the reference tables.
- The service relies on row identity established by a unique index or key that includes the sharding key to improve performance and reliability for large shardlets. This allows the service to move data at an even finer granularity than just the sharding key value. This helps to reduce the maximum amount of log space and locks that are required during the operation. Consider creating a unique index or a primary key including the sharding key on a given table if you want to use that table with split/merge/move requests. For performance reasons, the sharding key should be the leading column in the key or the index.
- During the course of request processing, some shardlet data may be present both on the source and the target shard. This is necessary to protect against failures during the shardlet movement. The integration of split-merge with the shard map ensures that connections through the data-dependent routing APIs using the OpenConnectionForKey method on the shard map do not see any inconsistent intermediate states. However, when connecting to the source or the target shards without using the OpenConnectionForKey method, inconsistent intermediate states might be visible when split/merge/move requests are going on. These connections may show partial or duplicate results depending on the timing or the shard underlying the connection. This limitation currently includes the connections made by Elastic Scale Multi-Shard-Queries.
- The metadata database for the split-merge service must not be shared between different roles. For example, a role of the split-merge service running in staging needs to point to a different metadata database than the production role.
Billing
The split-merge service runs as a cloud service in your Microsoft Azure subscription. Therefore charges for cloud services apply to your instance of the service. Unless you frequently perform split/merge/move operations, we recommend you delete your split-merge cloud service. That saves costs for running or deployed cloud service instances. You can re-deploy and start your readily runnable configuration whenever you need to perform split or merge operations.
Monitoring
Status tables
The split-merge Service provides the RequestStatus table in the metadata store database for monitoring of completed and ongoing requests. The table lists a row for each split-merge request that has been submitted to this instance of the split-merge service. It gives the following information for each request:
Timestamp
The time and date when the request was started.
OperationId
A GUID that uniquely identifies the request. This request can also be used to cancel the operation while it is still ongoing.
Status
The current state of the request. For ongoing requests, it also lists the current phase in which the request is.
CancelRequest
A flag that indicates whether the request has been canceled.
Progress
A percentage estimate of completion for the operation. A value of 50 indicates that the operation is approximately 50% complete.
Details
An XML value that provides a more detailed progress report. The progress report is periodically updated as sets of rows are copied from source to target. In case of failures or exceptions, this column also includes more detailed information about the failure.
Azure Diagnostics
The split-merge service uses Azure Diagnostics based on Azure SDK 2.5 for monitoring and diagnostics. You control the diagnostics configuration as explained here: Enabling Diagnostics in Azure Cloud Services and Virtual Machines. The download package includes two diagnostics configurations - one for the web role and one for the worker role. It includes the definitions to log Performance Counters, IIS logs, Windows Event Logs, and split-merge application event logs.
Deploy Diagnostics
Note
This article uses the Azure Az PowerShell module, which is the recommended PowerShell module for interacting with Azure. To get started with the Az PowerShell module, see Install Azure PowerShell. To learn how to migrate to the Az PowerShell module, see Migrate Azure PowerShell from AzureRM to Az.
Important
The PowerShell Azure Resource Manager module is still supported, but all future development is for the Az.Sql module. For these cmdlets, see AzureRM.Sql. The arguments for the commands in the Az module and in the AzureRm modules are substantially identical.
To enable monitoring and diagnostics using the diagnostic configuration for the web and worker roles provided by the NuGet package, run the following commands using Azure PowerShell:
$storageName = "<azureStorageAccount>"
$key = "<azureStorageAccountKey"
$storageContext = New-AzStorageContext -StorageAccountName $storageName -StorageAccountKey $key
$configPath = "<filePath>\SplitMergeWebContent.diagnostics.xml"
$serviceName = "<cloudServiceName>"
Set-AzureServiceDiagnosticsExtension -StorageContext $storageContext `
-DiagnosticsConfigurationPath $configPath -ServiceName $serviceName `
-Slot Production -Role "SplitMergeWeb"
Set-AzureServiceDiagnosticsExtension -StorageContext $storageContext `
-DiagnosticsConfigurationPath $configPath -ServiceName $serviceName `
-Slot Production -Role "SplitMergeWorker"
You can find more information on how to configure and deploy diagnostics settings here: Enabling Diagnostics in Azure Cloud Services and Virtual Machines.
Retrieve diagnostics
You can easily access your diagnostics from the Visual Studio Server Explorer in the Azure part of the Server Explorer tree. Open a Visual Studio instance, and in the menu bar click View, and Server Explorer. Click the Azure icon to connect to your Azure subscription. Then navigate to Azure -> Storage -> <your storage account> -> Tables -> WADLogsTable. For more information, see Server Explorer.
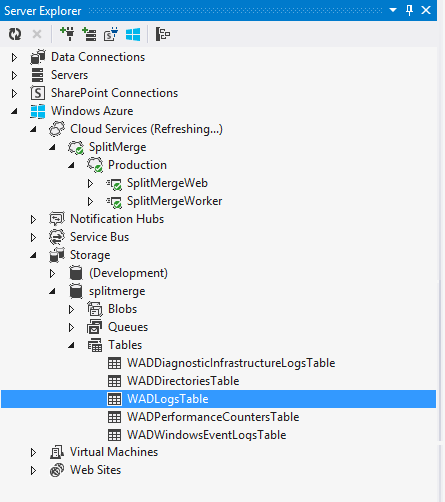
The WADLogsTable highlighted in the figure above contains the detailed events from the split-merge service's application log. Note that the default configuration of the downloaded package is geared towards a production deployment. Therefore the interval at which logs and counters are pulled from the service instances is large (5 minutes). For test and development, lower the interval by adjusting the diagnostics settings of the web or the worker role to your needs. Right-click on the role in the Visual Studio Server Explorer (see above) and then adjust the Transfer Period in the dialog for the Diagnostics configuration settings:

Performance
In general, better performance is to be expected from higher, more performant service tiers. Higher IO, CPU and memory allocations for the higher service tiers benefit the bulk copy and delete operations that the split-merge service uses. For that reason, increase the service tier just for those databases for a defined, limited period of time.
The service also performs validation queries as part of its normal operations. These validation queries check for unexpected presence of data in the target range and ensure that any split/merge/move operation starts from a consistent state. These queries all work over sharding key ranges defined by the scope of the operation and the batch size provided as part of the request definition. These queries perform best when an index is present that has the sharding key as the leading column.
In addition, a uniqueness property with the sharding key as the leading column will allow the service to use an optimized approach that limits resource consumption in terms of log space and memory. This uniqueness property is required to move large data sizes (typically above 1GB).
How to upgrade
- Follow the steps in Deploy a split-merge service.
- Change your cloud service configuration file for your split-merge deployment to reflect the new configuration parameters. A new required parameter is the information about the certificate used for encryption. An easy way to do this is to compare the new configuration template file from the download against your existing configuration. Make sure you add the settings for
DataEncryptionPrimaryCertificateThumbprintandDataEncryptionPrimaryfor both the web and the worker role. - Before deploying the update to Azure, ensure that all currently running split-merge operations have finished. You can easily do this by querying the RequestStatus and PendingWorkflows tables in the split-merge metadata database for ongoing requests.
- Update your existing cloud service deployment for split-merge in your Azure subscription with the new package and your updated service configuration file.
You do not need to provision a new metadata database for split-merge to upgrade. The new version will automatically upgrade your existing metadata database to the new version.
Best practices & troubleshooting
- Define a test tenant and exercise your most important split/merge/move operations with the test tenant across several shards. Ensure that all metadata is defined correctly in your shard map and that the operations do not violate constraints or foreign keys.
- Keep the test tenant data size above the maximum data size of your largest tenant to ensure you are not encountering data size related issues. This helps you assess an upper bound on the time it takes to move a single tenant around.
- Make sure that your schema allows deletions. The split-merge service requires the ability to remove data from the source shard once the data has been successfully copied to the target. For example, delete triggers can prevent the service from deleting the data on the source and may cause operations to fail.
- The sharding key should be the leading column in your primary key or unique index definition. That ensures the best performance for the split or merge validation queries, and for the actual data movement and deletion operations which always operate on sharding key ranges.
- Collocate your split-merge service in the region and data center where your databases reside.
Additional resources
Not using elastic database tools yet? Check out our Getting Started Guide. For questions, contact us on the Microsoft Q&A question page for SQL Database and for feature requests, add new ideas or vote for existing ideas in the SQL Database feedback forum.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for