Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: ![]() Azure SQL Database
Azure SQL Database
Important
SQL Data Sync will be retired on 30 September 2027. Consider migrating to alternative data replication/synchronization solutions.
Sync data with SQL Server databases by installing and configuring the Data Sync Agent for SQL Data Sync in Azure. For more info about SQL Data Sync, see What is SQL Data Sync for Azure?
SQL Data Sync does not support Azure SQL Managed Instance or Azure Synapse Analytics.
Download and install
Caution
Consider migrating to alternative data replication/synchronization solutions.
To download the Data Sync Agent, go to SQL Data Sync Agent. To upgrade the Data Sync Agent, install the Agent in the same location as the old Agent and it will override the original one.
Install silently
To install the Data Sync Agent silently from the command prompt, enter a command similar to the following example. Check the file name of the downloaded .msi file, and provide your own values for the TARGETDIR and SERVICEACCOUNT arguments.
If you don't provide a value for TARGETDIR, the default value is
C:\Program Files (x86)\Microsoft SQL Data Sync 2.0.If you provide
LocalSystemas the value of SERVICEACCOUNT, use SQL Server authentication when you configure the agent to connect to SQL Server.If you provide a domain user account or a local user account as the value of SERVICEACCOUNT, you also have to provide the password with the SERVICEPASSWORD argument. For example,
SERVICEACCOUNT="<domain>\<user>" SERVICEPASSWORD="<password>".
msiexec /i "SQLDataSyncAgent-2.0-x86-ENU.msi" TARGETDIR="C:\Program Files (x86)\Microsoft SQL Data Sync 2.0" SERVICEACCOUNT="LocalSystem" /qn
Sync data with a SQL Server database
To configure the Data Sync Agent so you can sync data with one or more SQL Server databases, see Add a SQL Server database.
Support for SQL Server on-premises versions
Only the following versions of SQL Server on-premises can be part of a sync group:
- SQL Server 2008
- SQL Server 2008 R2
- SQL Server 2012
- SQL Server 2016
- SQL Server 2017 on Windows
- SQL Server 2019 on Windows
- SQL Server 2022 on Windows
Data Sync Agent FAQ
Why do I need a client agent
The SQL Data Sync service communicates with SQL Server databases via the client agent. This security feature prevents direct communication with databases behind a firewall. When the SQL Data Sync service communicates with the agent, it does so using encrypted connections and a unique token or agent key. The SQL Server databases authenticate the agent using the connection string and agent key. This design provides a high level of security for your data.
How many instances of the local agent UI can be run
Only one instance of the UI can be run.
How can I change my service account
After you install a client agent, the only way to change the service account is to uninstall it and install a new client agent with the new service account.
How do I change my agent key
An agent key can only be used once by an agent. It cannot be reused when you remove then reinstall a new agent, nor can it be used by multiple agents. If you need to create a new key for an existing agent, you must be sure that the same key is recorded with the client agent and with the SQL Data Sync service.
How do I retire a client agent
To immediately invalidate or retire an agent, regenerate its key in the portal but do not submit it in the Agent UI. Regenerating a key invalidates the previous key irrespective if the corresponding agent is online or offline.
How do I move a client agent to another computer
If you want to run the local agent from a different computer than it is currently on, and reuse the same agent, do the following steps:
- Install the agent on desired computer.
- Sign in to the SQL Data Sync portal and regenerate an agent key for the existing agent.
- Use the new agent's UI to submit the agent key.
- Wait while the client agent downloads the list of on-premises databases that were registered earlier.
- Provide database credentials for all databases that display as unreachable. These databases must be reachable from the new computer on which the agent is installed.
How do I delete the Sync metadata database if the Sync agent is still associated with it
In order to delete a Sync metadata database that has a Sync agent associated with it, you must first delete the Sync agent. To delete the agent, do the following things:
- Select the Sync database.
- Go to the Sync to other databases page.
- Select the Sync agent and select Delete.
Troubleshoot Data Sync Agent issues
The client agent install, uninstall, or repair fails
Cause. Many scenarios might cause this failure. To determine the specific cause for this failure, look at the logs.
Resolution. To find the specific cause of the failure, generate and look at the Windows Installer logs. You can turn on logging at a command prompt. For example, if the downloaded installation file is
SQLDataSyncAgent-2.0-x86-ENU.msi, generate and examine log files by using the following command lines:For installs:
msiexec.exe /i SQLDataSyncAgent-2.0-x86-ENU.msi /l*v LocalAgentSetup.LogFor uninstalls:
msiexec.exe /x SQLDataSyncAgent-2.0-x86-ENU.msi /l*v LocalAgentSetup.LogYou can also turn on logging for all installations that are performed by Windows Installer. The Microsoft Knowledge Base article How to enable Windows Installer logging provides a one-click solution to turn on logging for Windows Installer. It also provides the location of the logs.
The client agent doesn't work after I cancel the uninstall
The client agent doesn't work, even after you cancel its uninstallation.
Cause. This occurs because the SQL Data Sync client agent doesn't store credentials.
Resolution. You can try these two solutions:
- Use services.msc to reenter the credentials for the client agent.
- Uninstall this client agent and then install a new one. Download and install the latest client agent from Download Center.
My database isn't listed in the agent list
When you attempt to add an existing SQL Server database to a sync group, the database doesn't appear in the list of agents.
These scenarios might cause this issue:
Cause. The client agent and sync group are in different datacenters.
Resolution. The client agent and the sync group must be in the same datacenter. To set this up, you have two options:
- Create a new agent in the datacenter where the sync group is located. Then, register the database with that agent.
- Delete the current sync group. Then, re-create the sync group in the datacenter where the agent is located.
Cause. The client agent's list of databases isn't current.
Resolution. Stop and then restart the client agent service.
The local agent downloads the list of associated databases only on the first submission of the agent key. It doesn't download the list of associated databases on subsequent agent key submissions. Databases that are registered during an agent move don't show up in the original agent instance.
Client agent doesn't start (Error 1069)
You discover that the agent isn't running on a computer that hosts SQL Server. When you attempt to manually start the agent, you see a dialog box that displays the message, "Error 1069: The service did not start due to a logon failure."
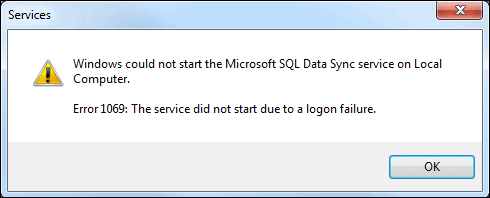
Cause. A likely cause of this error is that the password on the local server has changed since you created the agent and agent password.
Resolution. Update the agent's password to your current server password:
- Locate the SQL Data Sync client agent service.
a. Select Start.
b. In the search box, enter services.msc.
c. In the search results, select Services.
d. In the Services window, scroll to the entry for SQL Data Sync Agent. - Right-click SQL Data Sync Agent, and then select Stop.
- Right-click SQL Data Sync Agent, and then select Properties.
- On SQL Data Sync Agent Properties, select the Log in tab.
- In the Password box, enter your password.
- In the Confirm Password box, reenter your password.
- Select Apply, and then select OK.
- In the Services window, right-click the SQL Data Sync Agent service, and then select Start.
- Close the Services window.
- Locate the SQL Data Sync client agent service.
I can't submit the agent key
After you create or re-create a key for an agent, you try to submit the key through the SqlAzureDataSyncAgent application. The submission fails to complete.
Prerequisites. Before you proceed, check the following prerequisites:
The SQL Data Sync Windows service is running.
The service account for SQL Data Sync Windows service has network access.
The outbound 1433 port is open in your local firewall rule.
The local ip is added to the server or database firewall rule for the sync metadata database.
Cause. The agent key uniquely identifies each local agent. The key must meet two conditions:
- The client agent key on the SQL Data Sync server and the local computer must be identical.
- The client agent key can be used only once.
Resolution. If your agent isn't working, it's because one or both of these conditions are not met. To get your agent to work again:
- Generate a new key.
- Apply the new key to the agent.
To apply the new key to the agent:
- In File Explorer, go to your agent installation directory. The default installation directory is C:\Program Files (x86)\Microsoft SQL Data Sync.
- Double-click the bin subdirectory.
- Open the SqlAzureDataSyncAgent application.
- Select Submit Agent Key.
- In the space provided, paste the key from your clipboard.
- Select OK.
- Close the program.
The client agent can't be deleted from the portal if its associated on-premises database is unreachable
If a local endpoint (that is, a database) that is registered with a SQL Data Sync client agent becomes unreachable, the client agent can't be deleted.
Cause. The local agent can't be deleted because the unreachable database is still registered with the agent. When you try to delete the agent, the deletion process tries to reach the database, which fails.
Resolution. Use "force delete" to delete the unreachable database.
Note
If sync metadata tables remain after a "force delete", use deprovisioningutil.exe to clean them up.
Local Sync Agent app can't connect to the local sync service
Resolution. Try the following steps:
- Exit the app.
- Open the Component Services Panel.
a. In the search box on the taskbar, enter services.msc.
b. In the search results, double-click Services. - Stop the SQL Data Sync service.
- Restart the SQL Data Sync service.
- Reopen the app.
Run the Data Sync Agent from the command prompt
You can run the following Data Sync Agent commands from the command prompt:
Ping the service
Usage
SqlDataSyncAgentCommand.exe -action pingsyncservice
Example
SqlDataSyncAgentCommand.exe -action "pingsyncservice"
Display registered databases
Usage
SqlDataSyncAgentCommand.exe -action displayregistereddatabases
Example
SqlDataSyncAgentCommand.exe -action "displayregistereddatabases"
Submit the agent key
Usage
Usage: SqlDataSyncAgentCommand.exe -action submitagentkey -agentkey [agent key] -username [user name] -password [password]
Example
SqlDataSyncAgentCommand.exe -action submitagentkey -agentkey [agent key generated from portal, PowerShell, or API] -username [user name to sync metadata database] -password [user name to sync metadata database]
Register a database
Usage
SqlDataSyncAgentCommand.exe -action registerdatabase -servername [on-premisesdatabase server name] -databasename [on-premisesdatabase name] -username [domain\\username] -password [password] -authentication [sql or windows] -encryption [true or false]
Examples
SqlDataSyncAgentCommand.exe -action "registerdatabase" -serverName localhost -databaseName testdb -authentication sql -username <user name> -password <password> -encryption true
SqlDataSyncAgentCommand.exe -action "registerdatabase" -serverName localhost -databaseName testdb -authentication windows -encryption true
Unregister a database
When you use this command to unregister a database, it deprovisions the database completely. If the database participates in other sync groups, this operation breaks the other sync groups.
Usage
SqlDataSyncAgentCommand.exe -action unregisterdatabase -servername [on-premisesdatabase server name] -databasename [on-premisesdatabase name]
Example
SqlDataSyncAgentCommand.exe -action "unregisterdatabase" -serverName localhost -databaseName testdb
Update credentials
Usage
SqlDataSyncAgentCommand.exe -action updatecredential -servername [on-premisesdatabase server name] -databasename [on-premisesdatabase name] -username [domain\\username] -password [password] -authentication [sql or windows] -encryption [true or false]
Examples
SqlDataSyncAgentCommand.exe -action "updatecredential" -serverName localhost -databaseName testdb -authentication sql -username <user name> -password <password> -encryption true
SqlDataSyncAgentCommand.exe -action "updatecredential" -serverName localhost -databaseName testdb -authentication windows -encryption true
Related content
For more info about SQL Data Sync, see the following articles:
- Overview - Sync data across multiple cloud and on-premises databases with SQL Data Sync in Azure
- Set up Data Sync
- Best practices - Best practices for Azure SQL Data Sync
- Monitor - Monitor SQL Data Sync with Azure Monitor logs
- Troubleshoot - Troubleshoot issues with Azure SQL Data Sync