Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
This article covers how to monitor and manage files in databases in Azure SQL Managed Instance. We review how to monitor database file size, shrink the transaction log, enlarge a transaction log file, and control the growth of a transaction log file.
This article applies to Azure SQL Managed Instance. Though very similar, for information on managing the size of transaction log files in SQL Server, see Manage the size of the transaction log file.
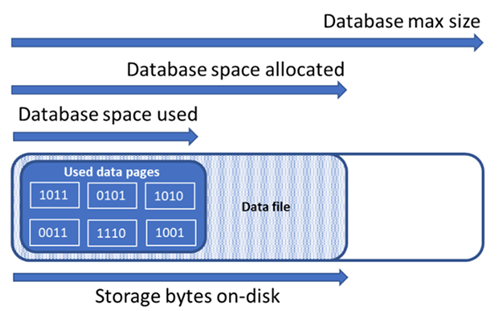
Understand types of storage space for a database
Understanding the following storage space quantities are important for managing the file space of a database.
| Database quantity | Definition | Comments |
|---|---|---|
| Data space used | The amount of space used to store database data. | Generally, space used increases (decreases) on inserts (deletes). In some cases, the space used does not change on inserts or deletes depending on the amount and pattern of data involved in the operation and any fragmentation. For example, deleting one row from every data page does not necessarily decrease the space used. |
| Data space allocated | The amount of formatted file space made available for storing database data. | The amount of space allocated grows automatically, but never decreases after deletes. This behavior ensures that future inserts are faster since space does not need to be reformatted. |
| Data space allocated but unused | The difference between the amount of data space allocated and data space used. | This quantity represents the maximum amount of free space that can be reclaimed by shrinking database data files. |
| Data max size | The maximum amount of space that can be used for storing database data. | The amount of data space allocated cannot grow beyond the data max size. |
The following diagram illustrates the relationship between the different types of storage space for a database.
Query a single database for file space information
Use the following query on sys.database_files to return the amount of database file space allocated and the amount of unused space allocated. Units of the query result are in MB.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Monitor log space use
Monitor log space use by using sys.dm_db_log_space_usage. This DMV returns information about the amount of log space currently used, and indicates when the transaction log needs truncation.
For information about the current log file size, its maximum size, and the autogrow option for the file, you can also use the size, max_size, and growth columns for that log file in sys.database_files.
Storage space metrics displayed in the Azure Resource Manager based metrics APIs only measure the size of used data pages. For examples, see PowerShell get-metrics.
Shrink log file size
To reduce the physical size of a physical log file by removing unused space, shrink the log file. A shrink only makes a difference when a transaction log file contains unused space. If the log file is full, likely because of open transactions, investigate what is preventing transaction log truncation.
Caution
Shrink operations should not be considered a regular maintenance operation. Data and log files that grow due to regular, recurring business operations do not require shrink operations. Shrink commands impact database performance while running, and if possible should be run during periods of low usage. It is not recommended to shrink data files if regular application workload will cause the files to grow to the same allocated size again.
Be aware of the potential negative performance impact of shrinking database files, see Index maintenance after shrink. In rare cases, shrink operations can be affected by automated database backups. If necessary, retry the shrink operation.
Before shrinking the transaction log, keep in mind Factors that can delay log truncation. If the storage space is required again after a log shrink, the transaction log will grow again and by doing that, introduce performance overhead during log growth operations. For more information, see the Recommendations.
You can shrink a log file only while the database is online, and at least one virtual log file (VLF) is free. In some cases, shrinking the log might not be possible until after the next log truncation.
Factors, such as a long-running transaction, can keep VLFs active for an extended period, can restrict log shrinkage, or even prevent the log from shrinking at all. For information, see Factors that can delay log truncation.
Shrinking a log file removes one or more VLFs that hold no part of the logical log (that is, inactive VLFs). When you shrink a transaction log file, inactive VLFs are removed from the end of the log file to reduce the log to approximately the target size.
For more information on shrink operations, review the following:
Shrink a log file (without shrinking database files)
Monitor log-file shrink events
Monitor log space
sys.database_files (Transact-SQL) (See the
size,max_size, andgrowthcolumns for the log file or files.)
Index maintenance after shrink
After a shrink operation is completed against data files, indexes can become fragmented. This reduces their performance optimization effectiveness for certain workloads, such as queries using large scans. If performance degradation occurs after the shrink operation is complete, consider index maintenance to rebuild indexes. Keep in mind that index rebuilds require free space in the database, and hence might cause the allocated space to increase, counteracting the effect of shrink.
For more information about index maintenance, see Optimize index maintenance to improve query performance and reduce resource consumption.
Evaluate index page density
If truncating data files did not result in a sufficient reduction in allocated space, you might decide to shrink database data files to reclaim unused space from those files. However, as an optional but recommended step, you should first determine average page density for indexes in the database. For the same amount of data, shrink will complete faster if page density is high, because it will have to move fewer pages. If page density is low for some indexes, consider performing maintenance on these indexes to increase page density before shrinking data files. This will also let shrink achieve a deeper reduction in allocated storage space.
To determine page density for all indexes in the database, use the following query. Page density is reported in the avg_page_space_used_in_percent column.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
If there are indexes with high page count that have page density lower than 60-70%, consider rebuilding or reorganizing these indexes before shrinking data files.
Note
For larger databases, the query to determine page density can take a long time (hours) to complete. Additionally, rebuilding or reorganizing large indexes also requires substantial time and resource usage. There is a tradeoff between spending extra time on increasing page density on one hand, and reducing shrink duration and achieving higher space savings on another.
If there are multiple indexes with low page density, you might be able to rebuild them in parallel on multiple database sessions to speed up the process. However, make sure that you are not approaching database resource limits by doing so, and leave sufficient resource headroom for application workloads. Monitor resource consumption (CPU, Data IO, Log IO) in Azure portal or using the sys.dm_db_resource_stats view, and start additional parallel rebuilds only if resource utilization on each of these dimensions remains substantially lower than 100%. If CPU, Data IO, or Log IO utilization is at 100%, you can scale up the database to have more CPU cores and increase IO throughput, allowing for additional parallel rebuilds to complete the process faster.
Sample index rebuild command
Following is a sample command to rebuild an index and increase its page density, using the ALTER INDEX statement:
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
This command initiates an online and resumable index rebuild. This lets concurrent workloads continue using the table while the rebuild is in progress, and lets you resume the rebuild if it gets interrupted for any reason. However, this type of rebuild is slower than an offline rebuild, which blocks access to the table. If no other workloads need to access the table during rebuild, set the ONLINE and RESUMABLE options to OFF and remove the WAIT_AT_LOW_PRIORITY clause.
To learn more about index maintenance, see Optimize index maintenance to improve query performance and reduce resource consumption.
Shrink multiple data files
As noted earlier, shrink with data movement is a long-running process. If the database has multiple data files, you can speed up the process by shrinking multiple data files in parallel. You do this by opening multiple database sessions, and using DBCC SHRINKFILE on each session with a different file_id value. Similar to rebuilding indexes earlier, make sure you have sufficient resource headroom (CPU, Data IO, Log IO) before starting each new parallel shrink command.
The following sample command shrinks data file with file_id 4, attempting to reduce its allocated size to 52,000 MB by moving pages within the file:
DBCC SHRINKFILE (4, 52000);
If you want to reduce allocated space for the file to the minimum possible, execute the statement without specifying the target size:
DBCC SHRINKFILE (4);
If a workload is running concurrently with shrink, it might start using the storage space freed by shrink before shrink completes and truncates the file. In this case, shrink will not be able to reduce allocated space to the specified target.
You can mitigate this by shrinking each file in smaller steps. This means that in the DBCC SHRINKFILE command, you set the target that is slightly smaller than the current allocated space for the file. For example, if allocated space for file with file_id 4 is 200,000 MB, and you want to shrink it to 100,000 MB, you can first set the target to 170,000 MB:
DBCC SHRINKFILE (4, 170000);
Once this command completes, it will have truncated the file and reduced its allocated size to 170,000 MB. You can then repeat this command, setting target first to 140,000 MB, then to 110,000 MB, etc., until the file is shrunk to the desired size. If the command completes but the file is not truncated, use smaller steps, for example 15,000 MB rather than 30,000 MB.
To monitor shrink progress for all concurrently running shrink sessions, you can use the following query:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Note
Shrink progress can be non-linear, and the value in the percent_complete column might remain virtually unchanged for long periods of time, even though shrink is still in progress.
Once shrink has completed for all data files, use the space usage query to determine the resulting reduction in allocated storage size. If there is still a large difference between used space and allocated space, you can rebuild indexes. This can temporarily increase allocated space further, however shrinking data files again after rebuilding indexes should result in a deeper reduction in allocated space.
Enlarge a log file
In Azure SQL Managed Instance, add space to a log file by enlarging the existing log file (if disk space permits). Adding a log file to the database is not supported. One transaction log file is sufficient unless log space is running out, and disk space is also running out on the volume that holds the log file.
To enlarge the log file, use the MODIFY FILE clause of the ALTER DATABASE statement, specifying the SIZE and MAXSIZE syntax. For more information, see ALTER DATABASE (Transact-SQL) File and Filegroup options.
For more information, see the Recommendations.
Control transaction log file growth
Use the ALTER DATABASE (Transact-SQL) File and Filegroup options statement to manage the growth of a transaction log file. Note the following:
- To change the current file size in KB, MB, GB, and TB units, use the
SIZEoption. - To change the growth increment, use the
FILEGROWTHoption. A value of 0 indicates that automatic growth is set to off and no additional space is permitted. - To control the maximum size of a log file in KB, MB, GB, and TB units or to set growth to UNLIMITED, use the
MAXSIZEoption.
Recommendations
Following are some general recommendations when you are working with transaction log files:
The automatic growth (autogrow) increment of the transaction log, as set by the
FILEGROWTHoption, must be large enough to stay ahead of the needs of the workload transactions. The file growth increment on a log file should be sufficiently large to avoid frequent expansion. A good pointer to properly size a transaction log is monitoring the amount of log occupied during:- The time required to execute a full backup, because log backups cannot occur until it finishes.
- The time required for the largest index maintenance operations.
- The time required to execute the largest batch in a database.
When setting autogrow for data and log files using the
FILEGROWTHoption, it might be preferred to set it insizeinstead ofpercentage, to allow better control on the growth ratio, as percentage is an ever-growing amount.- In Azure SQL Managed Instance, instant file initialization can benefit transaction log growth events up to 64 MB. The default auto growth size increment for new databases is 64 MB. Transaction log file autogrowth events larger than 64 MB cannot benefit from instant file initialization.
- As a best practice, do not set the
FILEGROWTHoption value above 1,024 MB for transaction logs.
A small autogrowth increment can generate too many small VLFs and can reduce performance. To determine the optimal VLF distribution for the current transaction log size of all databases in a given instance, and the required growth increments to achieve the required size, see this script for analyzing and fixing VLFs, provided by the SQL Tiger Team.
A large autogrowth increment can cause two problems:
- A large autogrowth increment can cause the database to pause while the new space is allocated, potentially causing query timeouts.
- A large autogrowth increment can generate too few and large VLFs and can also affect performance. To determine the optimal VLF distribution for the current transaction log size of all databases in a given instance, and the required growth increments to achieve the required size, see this script for analyzing and fixing VLFs, provided by the SQL Tiger Team.
Even with autogrow enabled, you can receive a message that the transaction log is full, if it cannot grow fast enough to satisfy the needs of your query. For more information on changing the growth increment, see ALTER DATABASE (Transact-SQL) File and Filegroup options.
Log files can be set to shrink automatically. However this is not recommended, and the auto_shrink database property is set to FALSE by default. If auto_shrink is set to TRUE, automatic shrinking reduces the size of a file only when more than 25 percent of its space is unused.
- The file is shrunk either to the size at which only 25 percent of the file is unused space or to the original size of the file, whichever is larger.
- For information about changing the setting of the auto_shrink property, see View or Change the Properties of a Database and ALTER DATABASE SET Options (Transact-SQL).