Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Data mesh is an exciting new approach to data architecture design and development. Unlike traditional data architecture, data mesh separates responsibility between functional data domains that focus on creating data products and a platform team that focuses on technical capabilities. This separation of responsibilities must be reflected in your platform. You must strike a balance between providing domain-agnostic capabilities and enabling your domain teams to model, process, and distribute their data across your organization.
Choosing the right level of domain granularity and rules for decoupling using platforms isn't easy. This article contains several scenarios that provide you with detailed guidance.
Cloud-scale analytics
When you want to build a data mesh with Azure, we recommend you adopt cloud-scale analytics. This framework is a deployable reference architecture and comes with open-source templates and best practices. Cloud-scale analytics architecture has two main building blocks that are fundamental for all deployment choices:
- Data management landing zone: The foundation of your data architecture. It contains all critical capabilities for data management, like data catalog, data lineage, API catalog, master data management, and so on.
- Data landing zones: Subscriptions that host your analytics and AI solutions. They include key capabilities for hosting an analytics platform.
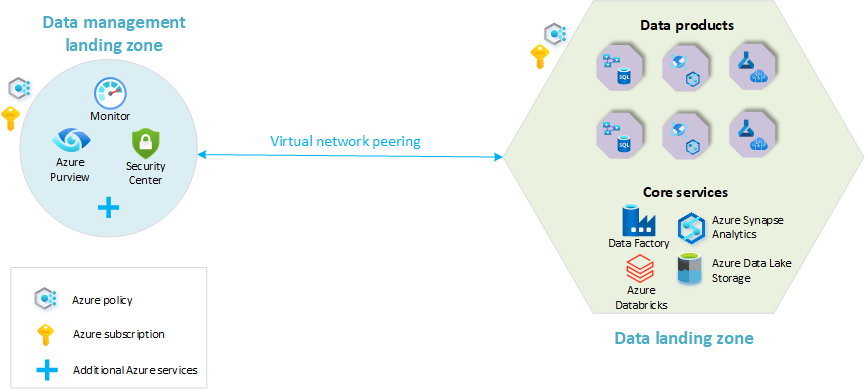
The following diagram provides an overview of a cloud-scale analytics platform with a data management landing zone and a single data landing zone. Not all Azure services are represented in the diagram. It has been simplified to highlight the core concepts resource organization within this architecture.
The cloud-based analytics framework isn't explicit on what exact type of data architecture you must provision. You can use it for many common cloud-scale analytics solutions, including (enterprise) data warehouses, data lakes, data lake houses and data meshes. All example solutions in this article use data mesh architecture.
Understand that all architectures adhere to the data mesh principles: domain ownership, data as product, self-serve data platform and federated computational governance. Different paths can all lead to a data mesh. There is no single right or wrong answer. You must make the right trade-offs for your organization's needs.
Single data landing zone
The simplest deployment pattern for building a data mesh architecture involves one data management landing zone and one data landing zone. The data architecture in such a scenario would look like the following:

In this model, all your functional data domains reside same data landing zone. A single subscription contains a standard set of services. Resource groups segregate different data domains and data products. Standard data services, like Azure Data Lake Store and Azure Logic Apps, apply to all domains.
All data domains follow data mesh principles: data follows domain ownership, and data is treated like products. The platform is fully self-service, though there are limited variations of services. All domains should strongly adhere and conform to the same data management principles.
This deployment option can be useful for smaller companies or greenfield projects who want to embrace data mesh but not over-complicate things. This deployment can also be a starting point for an organization that plans to build something more complex. In this case, plan for expanding into multiple landing zones at a later time.
Source system aligned and consumer aligned landing zones
In the previous model, we didn't take into account other subscriptions or on-premises applications. You can slightly alter the previous model by adding a source system-aligned landing zone to manage all incoming data. Data onboarding is a difficult process, so having two data landing zones is useful. Onboarding remains one of the most challenging parts of using data at large. Onboarding also often requires extra tools to address integration, because its challenges differ from those of integration. It helps to distinguish between providing data and consuming data.

In the architecture on the left of this diagram, services facilitate all data onboarding, like CDC, services for pulling APIs, or data lake services for dynamically building datasets. Services in this platform can pull data from on-premises, cloud environments or SaaS vendors. This type of platform typically also has more overhead, because there's more coupling with underlying operational applications. You might want to treat this differently from any data usage.
In the architecture on the right of the diagram, the organization optimizes for consumption and has services focused on turning data into value. These services can include machine learning, reporting, and so on.
These architecture domains follow all principles of data mesh. Domains take ownership of data and are allowed to directly distribute data to other domains.
Hub, generic, and special data landing zones
The next deployment option is another iteration of the previous design. This deployment follows a governed mesh topology: data is distributed via a central hub, in which data is partitioned per domain, logically isolated, and not integrated. This model's hub uses its own (domain-agnostic) data landing zone, and can be owned by a central data governance team overseeing which data is distributed to which other domains. The hub also carries services that facilitate data onboarding.

For domains that require standard services for consuming, using, analyzing and creating new data, use generic data landing zone. This single subscription holds a standard set of services. Also apply data virtualization, as most of your data products are already persisted in the hub and you don't need more data duplication.
This deployment allows for 'specials': extra landing zones that you can provision when it's not possible to logically group domains. They could be needed when regional or legal boundaries apply, or when your domains have unique and contrasting requirements. You might also need them in situations where a strong global subsidiary governance is applied with exceptions for overseas activities.
If your organization needs to control which data is distributed and consumed by which domains, hub deployment is a good option. It's also an option if you're addressing time-variant and non-volatile concerns for large data consumers. You can strongly standardize data product design, which allows your domains to time travel and perform redeliveries. This model is especially common within the financial industry.
Functional and regionally aligned data landing zones
Provisioning multiple data landing zones can help you group functional domains based on cohesion and efficiency for working and sharing data. All your data landing zones adhere to the same auditing and controls, but you can still have flexibility and design changes between different data landing zones.

Determine the functional data domains that you want to logically group together for a shared data landing zone. For example, you might implement the same templates if you have regional boundaries. Ownership, security, or legal boundaries can force you to segregate domains. Flexibility, the pace of change, and separation or selling of your capabilities are also important factors to consider.
Further guidance and best practices can be found in data domains.
Different landing zones don't stand alone. They can connect to data lakes hosted in other zones. This allows domains to collaborate across your enterprise. You can also apply polyglot persistence to mix different data store technologies. Polyglot persistence allows your domains to directly read data from other domains without duplicating data.
When deploying multiple data landing zones, know that there's management overhead attached to each data landing zone. You must apply VNet peering between all data landing zones, you must manage extra private endpoints, and so on.
Deploying multiple data landing zones is good option if your data architecture is large. You can add more landing zones to your architecture to address common needs of various domains. These extra landing zones use virtual network peering to connect to both the data management landing zone and all other landing zones. Peering allows you to share datasets and resources across your landing zones. Splitting data across separate zones lets you spread workloads across your Azure subscriptions and resources. This approach helps organically implement the data mesh.
Large scale enterprise requiring different data management zones
Large enterprises operating on a global scale can have contrasting data management requirements between different parts of their organization. You can deploy multiple data management and data landing zones together to address this issue. The following diagram shows an example of this type of architecture:

Multiple data management landing zones should justify your overhead and integration complexity. For example, another data management landing zone might make sense for situations where your organization's (meta)data must not be seen by anyone outside your organization.
Conclusion
The transition towards data mesh is a cultural shift involving nuances, trade offs and considerations. You can use cloud-scale analytics to obtain best practices and executable resources. This article's reference architectures offer starting points for you to kick-start your implementation.