Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Important
Cloud Services (classic) is now deprecated for all customers as of September 1st, 2024. Any existing running deployments will be stopped and shut down by Microsoft and the data will be permanently lost starting October 2024. New deployments should use the new Azure Resource Manager based deployment model Azure Cloud Services (extended support).
At Microsoft, we work hard to make sure that our services are always available to you when you need them. Forces beyond our control sometimes affect us in ways that cause unplanned service disruptions.
Microsoft provides a Service Level Agreement (SLA) for its services as a commitment for uptime and connectivity. The SLA for individual Azure services can be found at Azure Service Level Agreements.
Azure already has many built-in platform features that support highly available applications. For more about these services, read Disaster recovery and high availability for Azure applications.
This article covers a true disaster recovery scenario, when a whole region experiences an outage due to major natural disaster or widespread service interruption. These scenarios are rare occurrences, but you must prepare for the possibility that there's an outage of an entire region. If an entire region experiences a service disruption, the locally redundant copies of your data would temporarily be unavailable. If you enabled geo-replication, three extra copies of your Azure Storage blobs and tables are stored in a different region. If a complete regional outage or a disaster in which the primary region isn't recoverable occurs, Azure remaps all of the Domain Name System (DNS) entries to the geo-replicated region.
Note
Be aware that you do not have any control over this process, and it will only occur for datacenter-wide service disruptions. Because of this, you must also rely on other application-specific backup strategies to achieve the highest level of availability. For more information, see Disaster recovery and high availability for applications built on Microsoft Azure. If you would like to be able to affect your own failover, you might want to consider the use of read-access geo-redundant storage (RA-GRS), which creates a read-only copy of your data in another region.
Option 1: Use a backup deployment through Azure Traffic Manager
The most robust disaster recovery solution involves maintaining multiple deployments of your application in different regions, then using Azure Traffic Manager to direct traffic between them. Azure Traffic Manager provides multiple routing methods, so you can choose whether to manage your deployments using a primary/backup model or to split traffic between them.
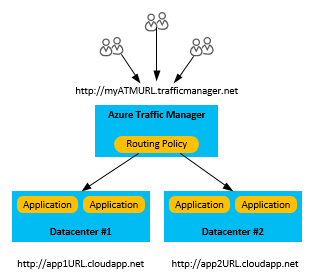
For the fastest response to the loss of a region, it's important that you configure Traffic Manager's endpoint monitoring.
Option 2: Deploy your application to a new region
Maintaining multiple active deployments as described in the previous option incurs additional ongoing costs. If your recovery time objective (RTO) is flexible enough and you have the original code or compiled Cloud Services package, you can create a new instance of your application in another region and update your DNS records to point to the new deployment.
For more detail about how to create and deploy a cloud service application, see How to create and deploy a cloud service.
Depending on your application data sources, you may need to check the recovery procedures for your application data source.
- For Azure Storage data sources, see Azure Storage redundancy to check on the options that are available based on the chosen redundancy model for your application.
- For SQL Database sources, read Overview: Cloud business continuity and database disaster recovery with SQL Database to check on the options that are available based on the chosen replication model for your application.
Option 3: Wait for recovery
In this case, no action on your part is required, but your service is unavailable until the region is restored. You can see the current service status on the Azure Service Health Dashboard.
Next steps
To learn more about how to implement a disaster recovery and high availability strategy, see Disaster recovery and high availability for Azure applications.
To develop a detailed technical understanding of a cloud platform’s capabilities, see Azure resiliency technical guidance.