Events
Take the Microsoft Learn AI Skills Challenge
Sep 24, 11 PM - Nov 1, 11 PM
Elevate your skills in Microsoft Fabric and earn a digital badge by November 1.
Register nowThis browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
APPLIES TO:
![]() Cassandra
Cassandra
The API for Cassandra in Azure Cosmos DB is a compatibility layer that provides wire protocol support for the open-source Apache Cassandra database.
This article describes common errors and solutions for applications that use the Azure Cosmos DB for Apache Cassandra. If your error isn't listed and you experience an error when you execute a supported operation in Cassandra, but the error isn't present when using native Apache Cassandra, create an Azure support request.
Note
As a fully managed cloud-native service, Azure Cosmos DB provides guarantees on availability, throughput, and consistency for the API for Cassandra. The API for Cassandra also facilitates zero-maintenance platform operations and zero-downtime patching.
These guarantees aren't possible in previous implementations of Apache Cassandra, so many of the API for Cassandra back-end operations differ from Apache Cassandra. We recommend particular settings and approaches to help avoid common errors.
This error is a top-level wrapper exception with a large number of possible causes and inner exceptions, many of which can be client related.
Common causes and solutions:
Idle timeout of Azure LoadBalancers: This issue might also manifest as ClosedConnectionException. To resolve the issue, set the keep-alive setting in the driver (see Enable keep-alive for the Java driver) and increase keep-alive settings in your operating system, or adjust idle timeout in Azure Load Balancer.
Client application resource exhaustion: Ensure that client machines have sufficient resources to complete the request.
You might see this error: "Cannot connect to any host, scheduling retry in 600000 milliseconds."
This error might be caused by source network address translation (SNAT) exhaustion on the client side. Follow the steps at SNAT for outbound connections to rule out this issue.
The error might also be an idle timeout issue where the Azure load balancer has four minutes of idle timeout by default. See Load balancer idle timeout. Enable keep-alive for the Java driver and set the keepAlive interval on the operating system to less than four minutes.
See troubleshoot NoHostAvailableException for more ways of handling the exception.
Requests are throttled because the total number of request units consumed is higher than the number of request units that you provisioned on the keyspace or table.
Consider scaling the throughput assigned to a keyspace or table from the Azure portal (see Elastically scale an Azure Cosmos DB for Apache Cassandra account) or implementing a retry policy.
For Java, see retry samples for the v3.x driver and the v4.x driver. See also Azure Cosmos DB Cassandra Extensions for Java.
The system seems to be throttling requests even though enough throughput is provisioned for request volume or consumed request unit cost. There are two possible causes:
Schema level operations: The API for Cassandra implements a system throughput budget for schema-level operations (CREATE TABLE, ALTER TABLE, DROP TABLE). This budget should be enough for schema operations in a production system. However, if you have a high number of schema-level operations, you might exceed this limit.
Because the budget isn't user-controlled, consider lowering the number of schema operations that you run. If that action doesn't resolve the issue or it isn't feasible for your workload, create an Azure support request.
Data skew: When throughput is provisioned in the API for Cassandra, it's divided equally between physical partitions, and each physical partition has an upper limit. If you have a high amount of data being inserted or queried from one particular partition, it might be rate-limited even if you provision a large amount of overall throughput (request units) for that table.
Review your data model and ensure you don't have excessive skew that might cause hot partitions.
Connection drops or times out unexpectedly.
The Apache Cassandra drivers for Java provide two native reconnection policies: ExponentialReconnectionPolicy and ConstantReconnectionPolicy. The default is ExponentialReconnectionPolicy. However, for Azure Cosmos DB for Apache Cassandra, we recommend ConstantReconnectionPolicy with a two-second delay.
See the documentation for the Java 4.x driver, the documentation for the Java 3.x driver, or Configuring ReconnectionPolicy for the Java driver examples.
You might have implemented a load-balancing policy in v3.x of the Java DataStax driver, with code similar to:
cluster = Cluster.builder()
.addContactPoint(cassandraHost)
.withPort(cassandraPort)
.withCredentials(cassandraUsername, cassandraPassword)
.withPoolingOptions(new PoolingOptions() .setConnectionsPerHost(HostDistance.LOCAL, 1, 2)
.setMaxRequestsPerConnection(HostDistance.LOCAL, 32000).setMaxQueueSize(Integer.MAX_VALUE))
.withSSL(sslOptions)
.withLoadBalancingPolicy(DCAwareRoundRobinPolicy.builder().withLocalDc("West US").build())
.withQueryOptions(new QueryOptions().setConsistencyLevel(ConsistencyLevel.LOCAL_QUORUM))
.withSocketOptions(getSocketOptions())
.build();
If the value for withLocalDc() doesn't match the contact point datacenter, you might experience an intermittent error: com.datastax.driver.core.exceptions.NoHostAvailableException: All host(s) tried for query failed (no host was tried).
Implement the CosmosLoadBalancingPolicy. To make it work, you might need to upgrade DataStax by using the following code:
LoadBalancingPolicy loadBalancingPolicy = new CosmosLoadBalancingPolicy.Builder().withWriteDC("West US").withReadDC("West US").build();
When you run select count(*) from table or similar for a large number of rows, the server times out.
If you're using a local CQLSH client, change the --connect-timeout or --request-timeout settings. See cqlsh: the CQL shell.
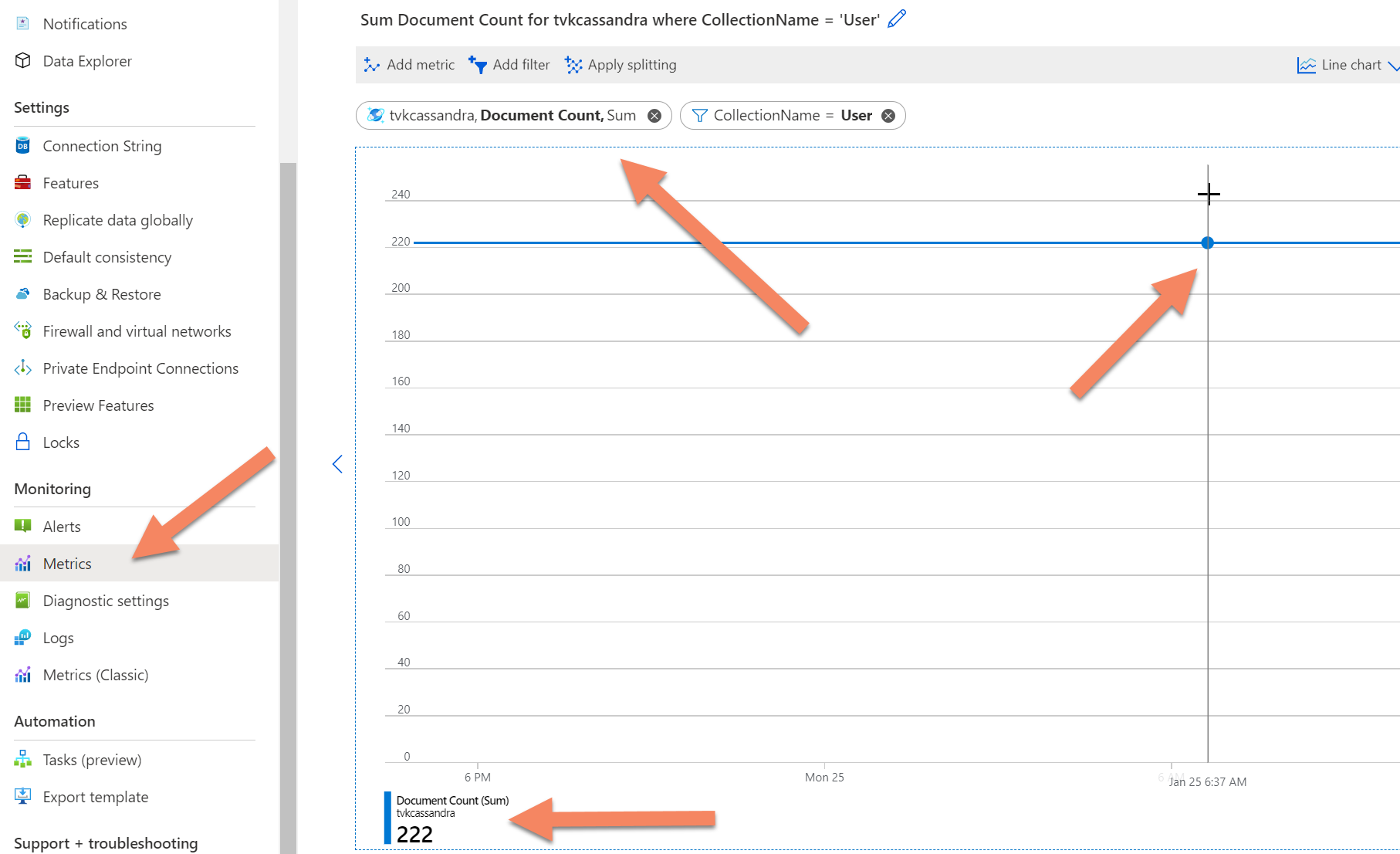
If the count still times out, you can get a count of records from the Azure Cosmos DB back-end telemetry by going to the metrics tab in the Azure portal, selecting the metric document count, and then adding a filter for the database or collection (the analog of the table in Azure Cosmos DB). You can then hover over the resulting graph for the point in time at which you want a count of the number of records.
For version 3.x of the Java driver, configure the reconnection policy when you create a cluster object:
import com.datastax.driver.core.policies.ConstantReconnectionPolicy;
Cluster.builder()
.withReconnectionPolicy(new ConstantReconnectionPolicy(2000))
.build();
For version 4.x of the Java driver, configure the reconnection policy by overriding settings in the reference.conf file:
datastax-java-driver {
advanced {
reconnection-policy{
# The driver provides two implementations out of the box: ExponentialReconnectionPolicy and
# ConstantReconnectionPolicy. We recommend ConstantReconnectionPolicy for API for Cassandra, with
# base-delay of 2 seconds.
class = ConstantReconnectionPolicy
base-delay = 2 second
}
}
For version 3.x of the Java driver, set keep-alive when you create a cluster object, and then ensure that keep-alive is enabled in the operating system:
import java.net.SocketOptions;
SocketOptions options = new SocketOptions();
options.setKeepAlive(true);
cluster = Cluster.builder().addContactPoints(contactPoints).withPort(port)
.withCredentials(cassandraUsername, cassandraPassword)
.withSocketOptions(options)
.build();
For version 4.x of the Java driver, set keep-alive by overriding settings in reference.conf, and then ensure that keep-alive is enabled in the operating system:
datastax-java-driver {
advanced {
socket{
keep-alive = true
}
}
Events
Take the Microsoft Learn AI Skills Challenge
Sep 24, 11 PM - Nov 1, 11 PM
Elevate your skills in Microsoft Fabric and earn a digital badge by November 1.
Register nowTraining
Module
Build a Java app with cloud-scale NoSQL Cosmos DB - Training
Learn how to create a Java application to store and query data in Azure Cosmos DB
Certification
Microsoft Certified: Azure Cosmos DB Developer Specialty - Certifications
Write efficient queries, create indexing policies, manage, and provision resources in the SQL API and SDK with Microsoft Azure Cosmos DB.