Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Azure Cosmos DB distributes your data across logical and physical partitions based on your partition keys to support horizontal scaling. By using hierarchical partition keys (also called subpartitoning), you can configure up to a three-level hierarchy for your partition keys to further optimize data distribution and for a higher level of scaling.
If you use synthetic keys today, have scenarios in which partition keys can exceed 20 GB of data, or would like to ensure that each tenant's document maps to its own logical partition, subpartitioning can help. If you use this feature, logical partition key prefixes can exceed 20 GB and 10,000 request units per second (RU/s). Queries by prefix are efficiently routed to the subset of partitions that hold the data.
Choose your hierarchical partition keys
If you have multitenant applications and currently isolate tenants by partition key, hierarchical partitions might benefit you. Hierarchical partitions allow you to scale beyond the logical partition key limit of 20 GB, and are a good solution if you'd like to ensure each of your tenants' documents can scale infinitely. If your current partition key or if a single partition key is frequently reaching 20 GB, hierarchical partitions are a great choice for your workload.
However, depending on the nature of your workload and how cardinal your first-level key is, there can be some tradeoffs, which we cover in depth in our hierarchical partition scenarios page.
When you choose each level of your hierarchical partition key, it's important to keep the following general partitioning concepts in mind and understand how each one can affect your workload:
For all containers, each level of the full path (starting with the first level) of your hierarchical partition key should:
Have a high cardinality. The first, second, and third (if applicable) keys of the hierarchical partition should all have a wide range of possible values.
- Having low cardinality at the first level of the hierarchical partition key limits all of your write operations at the time of ingestion to just one physical partition until it reaches 50 GB and splits into two physical partitions. For example, suppose your first-level key is on
TenantIdand you only have five unique tenants. Each of these tenants' operations are scoped to just one physical partition, limiting your throughput consumption to just what is on that one physical partition. This is because hierarchical partitions optimize for all documents with the same first-level key to be collocated on the same physical partition to avoid full-fanout queries. - While this might be okay for workloads where we do a one-time ingest of all our tenants' data and the following operations are primarily read-heavy afterwards, this can be unideal for workloads where your business requirements involve ingestion of data within a specific time. For example, if you have strict business requirements to avoid latencies, the maximum throughput your workload can theoretically achieve to ingest data is number of physical partitions * 10k. If your top-level key has low cardinality, your number of physical partitions is likely 1, unless there's sufficient data for the level-1 key for it to be spread across multiple partitions after splits, which can take between 4-6 hours to complete.
- Having low cardinality at the first level of the hierarchical partition key limits all of your write operations at the time of ingestion to just one physical partition until it reaches 50 GB and splits into two physical partitions. For example, suppose your first-level key is on
Spread RU consumption and data storage evenly across all logical partitions. This spread ensures even RU consumption and storage distribution across your physical partitions.
- If you choose a first-level key that seems to have high cardinality like
UserId, but in practice your workload performs operations on just one specificUserId, then you're likely to run into a hot partition as all of your operations are scoped to just one or few physical partitions.
- If you choose a first-level key that seems to have high cardinality like
Read-heavy workloads: We recommend that you choose hierarchical partition keys that appear frequently in your queries.
- For example, a workload that frequently runs queries to filter out specific user sessions in a multitenant application can benefit from hierarchical partition keys of
TenantId,UserId, andSessionId, in that order. Queries can be efficiently routed to only the relevant physical partitions by including the partition key in the filter predicate. For more information about choosing partition keys for read-heavy workloads, see the partitioning overview.
- For example, a workload that frequently runs queries to filter out specific user sessions in a multitenant application can benefit from hierarchical partition keys of
Write-heavy workloads: We recommend using a high cardinal value for the first level of your hierarchical partition key. High cardinality means that the first-level key (and subsequent levels as well) has at least thousands of unique values and more unique values than the number of your physical partitions.
For example, suppose we have a workload that isolates tenants by partition key, and has a few large tenants that are more write-heavy than others. Today, Azure Cosmos DB stops ingesting data on any partition key value if it exceeds 20 GB of data. In this workload, Microsoft and Contoso are large tenants and we anticipate it growing much faster than our other tenants. To avoid the risk of not being able to ingest data for these tenants, hierarchical partition keys allows us to scale these tenants beyond the 20-GB limit. We can add more levels like
UserIdandSessionIdto ensure higher scalability across tenants.To ensure that your workload can accommodate writes for all documents with the same first-level key, consider using item ID as a second or third level key.
If your first level doesn't have high cardinality and you're hitting the 20-GB logical partition limit on your partition key today, we suggest using a synthetic partition key instead of a hierarchical partition key.
Example use case
Suppose you have a multitenant scenario in which you store event information for users in each tenant. The event information might have event occurrences including but not limited to sign-in, clickstream, or payment events.
In a real-world scenario, some tenants can grow large, with thousands of users, while the many other tenants are smaller and have a few users. Partitioning by /TenantId might lead to exceeding the Azure Cosmos DB 20-GB storage limit on a single logical partition. Partitioning by /UserId makes all queries on a tenant cross-partition. Both approaches have significant downsides.
Using a synthetic partition key that combines TenantId and UserId adds complexity to the application. Additionally, the synthetic partition key queries for a tenant are still cross-partition, unless all users are known and specified in advance.
If your workload has tenants with roughly the same workload patterns, hierarchical partition key can help. With hierarchical partition keys, you can partition first on TenantId, and then on UserId. If you expect the TenantId and UserId combination to produce partitions that exceed 20 GB, you can even partition further down to another level, such as on SessionId. The overall depth can't exceed three levels. When a physical partition exceeds 50 GB of storage, Azure Cosmos DB automatically splits the physical partition so that roughly half of the data is on one physical partition, and half is on the other. Effectively, subpartitioning means that a single TenantId value can exceed 20 GB of data, and it's possible for TenantId data to span multiple physical partitions.
Queries that specify either TenantId, or both TenantId and UserId, are efficiently routed to only the subset of physical partitions that contain the relevant data. Specifying the full or prefix subpartitioned partition key path effectively avoids a full fan-out query. For example, if the container had 1,000 physical partitions, but a specific TenantId value was only on five physical partitions, the query would be routed to the smaller number of relevant physical partitions.
Use item ID in hierarchy
If your container has a property that has a large range of possible values, the property is likely a great partition key choice for the last level of your hierarchy. One possible example of this type of property is the item ID. The system property item ID exists in every item in your container. Adding the item ID as another level guarantees that you can scale beyond the logical partition key limit of 20 GB. You can scale beyond this limit for the first level or for the first and second levels of keys.
For example, you might have a container for a multitenant workload that's partitioned by TenantId and UserId. If it's possible for a single combination of TenantId and UserId to exceed 20 GB, then we recommend that you partition by using three levels of keys, and in which the third-level key has high cardinality. An example of this scenario is if the third-level key is a GUID that has naturally high cardinality. It's unlikely that the combination of TenantId, UserId, and a GUID exceeds 20 GB, so the combination of TenantId and UserId can effectively scale beyond 20 GB.
For more information about using item ID as a partition key, see the partitioning overview.
Get started
Important
Working with containers that use hierarchical partition keys is supported only in the following SDK versions. You must use a supported SDK to create new containers with hierarchical partition keys and to perform create, read, update, and delete (CRUD) or query operations on the data. If you want to use an SDK or connector that isn't currently supported, file a request on our community forum.
Find the latest preview version of each supported SDK:
| SDK | Supported versions | Package manager link |
|---|---|---|
| .NET SDK v3 | >= 3.33.0 | https://www.nuget.org/packages/Microsoft.Azure.Cosmos/3.33.0/ |
| Java SDK v4 | >= 4.42.0 | https://github.com/Azure/azure-sdk-for-java/blob/main/sdk/cosmos/azure-cosmos/CHANGELOG.md#4420-2023-03-17/ |
| JavaScript SDK v4 | 4.0.0 | https://www.npmjs.com/package/@azure/cosmos/ |
| Python SDK | >= 4.6.0 | https://pypi.org/project/azure-cosmos/4.6.0/ |
Create a container by using hierarchical partition keys
To get started, create a new container by using a predefined list of subpartitioning key paths up to three levels of depth.
You can create a new container by using one of these options:
- Azure portal
- SDK
- Azure Resource Manager template
- Azure Cosmos DB emulator
Azure portal
The simplest way to create a container and specify hierarchical partition keys is by using the Azure portal.
Sign in to the Azure portal.
Go to the existing Azure Cosmos DB for NoSQL account page.
On the left menu, select Data Explorer.
On Data Explorer, select the New Container option.
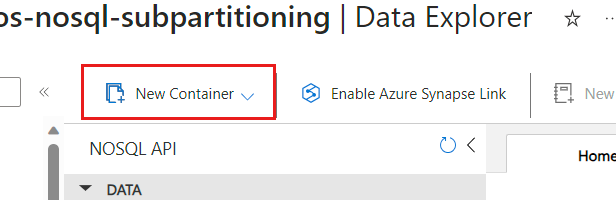
In New Container, for Partition key, enter
/TenantId. For the remaining fields, enter any value that matches your scenario.Note
We use
/TenantIdas an example here. You can specify any key for the first level when you implement hierarchical partition keys on your own containers.Select Add hierarchical partition key twice.
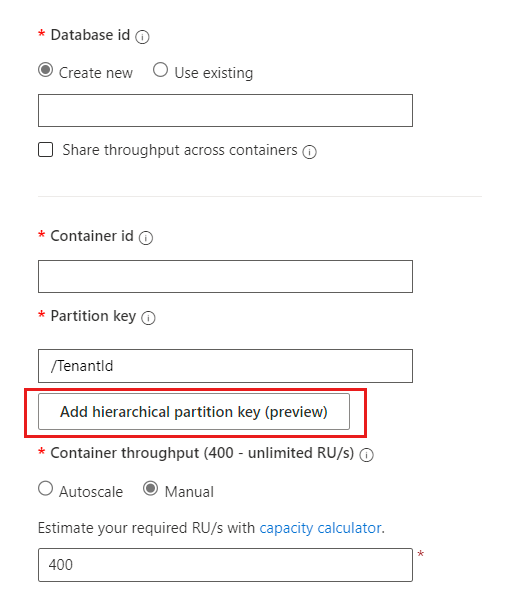
For the second and third tiers of subpartitioning, enter
/UserIdand/SessionIdrespectively.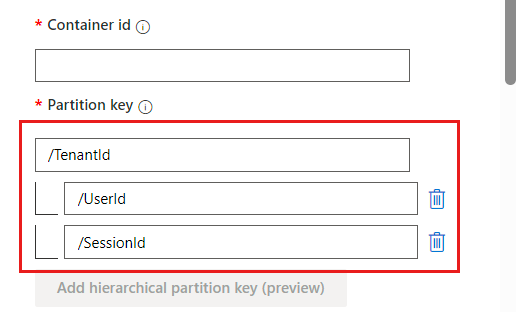
Select OK to create the container.




SDK
When you create a new container by using the SDK, define a list of subpartitioning key paths up to three levels of depth. Use the list of subpartition keys when you configure the properties of the new container.
// List of partition keys, in hierarchical order. You can have up to three levels of keys.
List<string> subpartitionKeyPaths = new List<string> {
"/TenantId",
"/UserId",
"/SessionId"
};
// Create a container properties object
ContainerProperties containerProperties = new ContainerProperties(
id: "<container-name>",
partitionKeyPaths: subpartitionKeyPaths
);
// Create a container that's subpartitioned by TenantId > UserId > SessionId
Container container = await database.CreateContainerIfNotExistsAsync(containerProperties, throughput: 400);
Azure Resource Manager templates
The Azure Resource Manager template for a subpartitioned container is almost identical to a standard container. The only key difference is the value of the properties/partitionKey path. For more information about creating an Azure Resource Manager template for an Azure Cosmos DB resource, see the Azure Resource Manager template reference for Azure Cosmos DB.
Configure the partitionKey object by using the values in the following table to create a subpartitioned container:
| Path | Value |
|---|---|
paths |
List of hierarchical partition keys (max three levels of depth) |
kind |
MultiHash |
version |
2 |
Example partition key definition
For example, assume that you have a hierarchical partition key that's composed of TenantId > UserId > SessionId. The partitionKey object would be configured to include all three values in the paths property, a kind value of MultiHash, and a version value of 2.
partitionKey: {
paths: [
'/TenantId'
'/UserId'
'/SessionId'
]
kind: 'MultiHash'
version: 2
}
For more information about the partitionKey object, see the ContainerPartitionKey specification.
Azure Cosmos DB emulator
You can test the subpartitioning feature by using the latest version of the local emulator for Azure Cosmos DB. To enable subparitioning on the emulator, start the emulator from the installation directory with the /EnablePreview flag:
.\CosmosDB.Emulator.exe /EnablePreview
Warning
The emulator doesn't currently support all of the hierarchical partition key features as the portal. The emulator currently doesn't support:
- Using the Data Explorer to create containers with hierarchical partition keys
- Using the Data Explorer to navigate to and interact with items using hierarchical partition keys
For more information, see Azure Cosmos DB emulator.
Use the SDKs to work with containers that have hierarchical partition keys
When you have a container that has hierarchical partition keys, use the previously specified versions of the .NET or Java SDKs to perform operations and execute queries on that container.
Add an item to a container
There are two options to add a new item to a container with hierarchical partition keys enabled:
- Automatic extraction
- Manually specify the path
Automatic extraction
If you pass in an object with the partition key value set, the SDK can automatically extract the full partition key path.
// Create a new item
UserSession item = new UserSession()
{
id = "f7da01b0-090b-41d2-8416-dacae09fbb4a",
TenantId = "Microsoft",
UserId = "00aa00aa-bb11-cc22-dd33-44ee44ee44ee",
SessionId = "0000-11-0000-1111"
};
// Pass in the object, and the SDK automatically extracts the full partition key path
ItemResponse<UserSession> createResponse = await container.CreateItemAsync(item);
Manually specify the path
The PartitionKeyBuilder class in the SDK can construct a value for a previously defined hierarchical partition key path. Use this class when you add a new item to a container that has subpartitioning enabled.
Tip
At scale, performance might be improved if you specify the full partition key path, even if the SDK can extract the path from the object.
// Create a new item object
PaymentEvent item = new PaymentEvent()
{
id = Guid.NewGuid().ToString(),
TenantId = "Microsoft",
UserId = "00aa00aa-bb11-cc22-dd33-44ee44ee44ee",
SessionId = "0000-11-0000-1111"
};
// Specify the full partition key path when creating the item
PartitionKey partitionKey = new PartitionKeyBuilder()
.Add(item.TenantId)
.Add(item.UserId)
.Add(item.SessionId)
.Build();
// Create the item in the container
ItemResponse<PaymentEvent> createResponse = await container.CreateItemAsync(item, partitionKey);
Perform a key/value lookup (point read) of an item
Key/value lookups (point reads) are performed in a way that's similar to a non-subpartitioned container. For example, assume you have a hierarchical partition key that consists of TenantId > UserId > SessionId. The unique identifier for the item is a GUID. It's represented as a string that serves as a unique document transaction identifier. To perform a point read on a single item, pass in the id property of the item and the full value for the partition key, including all three components of the path.
// Store the unique identifier
string id = "f7da01b0-090b-41d2-8416-dacae09fbb4a";
// Build the full partition key path
PartitionKey partitionKey = new PartitionKeyBuilder()
.Add("Microsoft") //TenantId
.Add("00aa00aa-bb11-cc22-dd33-44ee44ee44ee") //UserId
.Add("0000-11-0000-1111") //SessionId
.Build();
// Perform a point read
ItemResponse<UserSession> readResponse = await container.ReadItemAsync<UserSession>(
id,
partitionKey
);
Run a query
The SDK code that you use to run a query on a subpartitioned container is identical to running a query on a non-subpartitioned container.
When the query specifies all values of the partition keys in the WHERE filter or in a prefix of the key hierarchy, the SDK automatically routes the query to the corresponding physical partitions. Queries that provide only the "middle" of the hierarchy are cross-partition queries.
For example, consider a hierarchical partition key that's composed of TenantId > UserId > SessionId. The components of the query's filter determines if the query is a single-partition query, a targeted cross-partition query, or a fan-out query.
| Query | Routing |
|---|---|
SELECT * FROM c WHERE c.TenantId = 'Microsoft' AND c.UserId = '00aa00aa-bb11-cc22-dd33-44ee44ee44ee' AND c.SessionId = '0000-11-0000-1111' |
Routed to the single logical and physical partition that contains the data for the specified values of TenantId, UserId, and SessionId. |
SELECT * FROM c WHERE c.TenantId = 'Microsoft' AND c.UserId = '00aa00aa-bb11-cc22-dd33-44ee44ee44ee' |
Routed to only the targeted subset of logical and physical partition(s) that contain data for the specified values of TenantId and UserId. This query is a targeted cross-partition query that returns data for a specific user in the tenant. |
SELECT * FROM c WHERE c.TenantId = 'Microsoft' |
Routed to only the targeted subset of logical and physical partition(s) that contain data for the specified value of TenantId. This query is a targeted cross-partition query that returns data for all users in a tenant. |
SELECT * FROM c WHERE c.UserId = '00aa00aa-bb11-cc22-dd33-44ee44ee44ee' |
Routed to all physical partitions, resulting in a fan-out cross-partition query. |
SELECT * FROM c WHERE c.SessionId = '0000-11-0000-1111' |
Routed to all physical partitions, resulting in a fan-out cross-partition query. |
Single-partition query on a subpartitioned container
Here's an example of running a query that includes all the levels of subpartitioning, effectively making the query a single-partition query.
// Define a single-partition query that specifies the full partition key path
QueryDefinition query = new QueryDefinition(
"SELECT * FROM c WHERE c.TenantId = @tenant-id AND c.UserId = @user-id AND c.SessionId = @session-id")
.WithParameter("@tenant-id", "Microsoft")
.WithParameter("@user-id", "00aa00aa-bb11-cc22-dd33-44ee44ee44ee")
.WithParameter("@session-id", "0000-11-0000-1111");
// Retrieve an iterator for the result set
using FeedIterator<PaymentEvent> results = container.GetItemQueryIterator<PaymentEvent>(query);
while (results.HasMoreResults)
{
FeedResponse<UserSession> resultsPage = await resultSet.ReadNextAsync();
foreach(UserSession result in resultsPage)
{
// Process result
}
}
Targeted multi-partition query on a subpartitioned container
Here's an example of a query that includes a subset of the levels of subpartitioning, effectively making this query a targeted multi-partition query.
// Define a targeted cross-partition query specifying prefix path[s]
QueryDefinition query = new QueryDefinition(
"SELECT * FROM c WHERE c.TenantId = @tenant-id")
.WithParameter("@tenant-id", "Microsoft")
// Retrieve an iterator for the result set
using FeedIterator<PaymentEvent> results = container.GetItemQueryIterator<PaymentEvent>(query);
while (results.HasMoreResults)
{
FeedResponse<UserSession> resultsPage = await resultSet.ReadNextAsync();
foreach(UserSession result in resultsPage)
{
// Process result
}
}
Limitations and known issues
- Working with containers that use hierarchical partition keys is supported only in the .NET v3 SDK, in the Java v4 SDK, in the Python SDK, and in the preview version of the JavaScript SDK. You must use a supported SDK to create new containers that have hierarchical partition keys and to perform CRUD or query operations on the data. Support for other SDKs, including Python, isn't available currently.
- There are limitations with various Azure Cosmos DB connectors (for example, with Azure Data Factory).
- You can specify hierarchical partition keys only up to three layers in depth.
- Hierarchical partition keys can currently be enabled only on new containers. You must set partition key paths at the time of container creation, and you can't change them later. To use hierarchical partitions on existing containers, create a new container with the hierarchical partition keys set and move the data by using container copy jobs.
- Hierarchical partition keys are currently supported only for the API for NoSQL accounts. The APIs for MongoDB and Cassandra aren't currently supported.
- Hierarchical partition keys aren't currently supported with the users and permissions feature. You can't assign a permission to a partial prefix of the hierarchical partition key path. Permissions can only be assigned to the entire logical partition key path. For example, if you have partitioned by
TenantId- >UserId, you can't assign a permission that is for a specific value ofTenantId. However, you can assign a permission for a partition key if you specify both the value forTenantIdandUserId.