Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
In the fast-evolving realm of generative AI, large language models (LLMs) like GPT have transformed natural language processing. However, an emerging trend in AI is the use of vector stores, which play a pivotal role in enhancing AI applications.
This tutorial explores how to use Azure DocumentDB, LangChain, and OpenAI to implement retrieval-augmented generation (RAG) for superior AI performance, alongside discussing LLMs and their limitations. We explore the rapidly adopted paradigm of RAG, and briefly discuss the LangChain framework and Azure OpenAI models. Finally, we integrate these concepts into a real-world application. By the end, readers will have a solid understanding of these concepts.
Understand LLMs and their limitations
LLMs are advanced deep neural network models trained on extensive text datasets, enabling them to understand and generate human-like text. While revolutionary in natural language processing, LLMs have inherent limitations:
- Hallucinations: LLMs sometimes generate factually incorrect or ungrounded information, known as "hallucinations."
- Stale data: LLMs are trained on static datasets that might not include the most recent information, limiting their current relevance.
- No access to user's local data: LLMs don't have direct access to personal or localized data, restricting their ability to provide personalized responses.
- Token limits: LLMs have a maximum token limit per interaction, constraining the amount of text they can process at once. For example, OpenAI’s gpt-3.5-turbo has a token limit of 4,096.
Use retrieval-augmented generation
RAG is an architecture designed to overcome LLM limitations. RAG uses vector search to retrieve relevant documents based on an input query, providing these documents as context to the LLM for generating more accurate responses. Instead of relying solely on pretrained patterns, RAG enhances responses by incorporating up-to-date, relevant information. This approach helps to:
- Minimize hallucinations: Grounding responses in factual information.
- Ensure current information: Retrieving the most recent data to ensure up-to-date responses.
- Utilize external databases: Though it doesn't grant direct access to personal data, RAG allows integration with external, user-specific knowledge bases.
- Optimize token usage: By focusing on the most relevant documents, RAG makes token usage more efficient.
This tutorial demonstrates how RAG can be implemented using Azure DocumentDB to build a question-answering application tailored to your data.
Application architecture overview
The following architecture diagram illustrates the key components of our RAG implementation:

Key components and frameworks
We'll now discuss the various frameworks, models, and components used in this tutorial, emphasizing their roles and nuances.
Azure DocumentDB
Azure DocumentDB supports semantic similarity searches, essential for AI-powered applications. It allows data in various formats to be represented as vector embeddings, which can be stored alongside source data and metadata. Using an approximate nearest neighbors algorithm, like hierarchical navigable small world (HNSW), these embeddings can be queried for fast semantic similarity searches.
LangChain framework
LangChain simplifies the creation of LLM applications by providing a standard interface for chains, multiple tool integrations, and end-to-end chains for common tasks. It enables AI developers to build LLM applications that use external data sources.
Key aspects of LangChain:
- Chains: Sequences of components solving specific tasks.
- Components: Modules like LLM wrappers, vector store wrappers, prompt templates, data loaders, text splitters, and retrievers.
- Modularity: Simplifies development, debugging, and maintenance.
- Popularity: An open-source project rapidly gaining adoption and evolving to meet user needs.
Azure App Services interface
App services provide a robust platform for building user-friendly web interfaces for Gen-AI applications. This tutorial uses Azure App services to create an interactive web interface for the application.
OpenAI models
OpenAI is a leader in AI research, providing various models for language generation, text vectorization, image creation, and audio-to-text conversion. For this tutorial, we'll use OpenAI’s embedding and language models, crucial for understanding and generating language-based applications.
Embedding models vs. language generation models
| Category | Text embedding model | Language model |
|---|---|---|
| Purpose | Converts text into vector embeddings. | Understands and generates natural language. |
| Function | Transforms textual data into high-dimensional arrays of numbers, capturing the semantic meaning of the text. | Comprehends and produces human-like text based on given input. |
| Output | Array of numbers (vector embeddings). | Text, answers, translations, code, etc. |
| Example output | Each embedding represents the semantic meaning of the text in numerical form, with a dimensionality determined by the model. For example, text-embedding-ada-002 generates vectors with 1,536 dimensions. |
Contextually relevant and coherent text generated based on the input provided. For example, gpt-3.5-turbo can generate responses to questions, translate text, write code, and more. |
| Typical use cases | - Semantic search | - Chatbots |
| - Recommendation systems | - Automated content creation | |
| - Clustering and classification of text data | - Language translation | |
| - Information retrieval | - Summarization | |
| Data representation | Numerical representation (embeddings) | Natural language text |
| Dimensionality | The length of the array corresponds to the number of dimensions in the embedding space, for example, 1,536 dimensions. | Typically represented as a sequence of tokens, with the context determining the length. |
Main components of the application
- Azure DocumentDB: Storing and querying vector embeddings.
- LangChain: Constructing the application’s LLM workflow. Utilizes tools such as:
- Document loader: For loading and processing documents from a directory.
- Vector store integration: For storing and querying vector embeddings in Azure DocumentDB.
- AzureDocumentDBVectorSearch: Wrapper around Azure DocumentDB vector search
- Azure App Services: Building the user interface for Cosmic Food app.
- Azure OpenAI: For providing LLM and embedding models, including:
- text-embedding-ada-002: A text embedding model that converts text into vector embeddings with 1,536 dimensions.
- gpt-3.5-turbo: A language model for understanding and generating natural language.
Set up the environment
To get started with optimizing RAG using Azure DocumentDB, follow these steps:
- Create the following resources on Microsoft Azure:
- Azure DocumentDB cluster: For more information, see create a cluster
- Azure OpenAI resource with:
- Embedding model deployment (for example,
text-embedding-ada-002). - Chat model deployment (for example,
gpt-35-turbo).
- Embedding model deployment (for example,
Sample documents
In this tutorial, you load a single text file using document loaders. The file should be saved in a directory named data in the src folder. The contents of the file are as follows:
food_items.json
{
"category": "Cold Dishes",
"name": "Hamachi Fig",
"description": "Hamachi sashimi lightly tossed in a fig sauce with rum raisins, and serrano peppers then topped with fried lotus root.",
"price": "16.0 USD"
},
Load documents
Set the Azure DocumentDB connection string, database name, collection name, and index:
mongo_client = MongoClient(mongo_connection_string) database_name = "Contoso" db = mongo_client[database_name] collection_name = "ContosoCollection" index_name = "ContosoIndex" collection = db[collection_name]Initialize the embedding client.
from langchain_openai import AzureOpenAIEmbeddings openai_embeddings_model = os.getenv("AZURE_OPENAI_EMBEDDINGS_MODEL_NAME", "text-embedding-ada-002") openai_embeddings_deployment = os.getenv("AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME", "text-embedding") azure_openai_embeddings: AzureOpenAIEmbeddings = AzureOpenAIEmbeddings( model=openai_embeddings_model, azure_deployment=openai_embeddings_deployment, )Create embeddings from the data, save to the database, and return a connection to your vector store, Azure DocumentDB.
vector_store: AzureDocumentDBVectorSearch = AzureDocumentDBVectorSearch.from_documents( json_data, azure_openai_embeddings, collection=collection, index_name=index_name, )Create the following HNSW vector index on the collection. (Note that the name of the index is the same.)
num_lists = 100 dimensions = 1536 similarity_algorithm = DocumentDBSimilarityType.COS kind = DocumentDBVectorSearchType.VECTOR_HNSW m = 16 ef_construction = 64 vector_store.create_index( num_lists, dimensions, similarity_algorithm, kind, m, ef_construction )
Perform vector search using Azure DocumentDB
Connect to your vector store.
vector_store: AzureDocumentDBVectorSearch = AzureDocumentDBVectorSearch.from_connection_string( connection_string=mongo_connection_string, namespace=f"{database_name}.{collection_name}", embedding=azure_openai_embeddings, )Define a function that performs semantic similarity search using Azure DocumentDB Vector Search on a query. (Note that this code snippet is just a test function.)
query = "beef dishes" docs = vector_store.similarity_search(query) print(docs[0].page_content)Initialize the chat client to implement a RAG function.
azure_openai_chat: AzureChatOpenAI = AzureChatOpenAI( model=openai_chat_model, azure_deployment=openai_chat_deployment, )Create a RAG function.
history_prompt = ChatPromptTemplate.from_messages( [ MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ( "user", """Given the above conversation, generate a search query to look up to get information relevant to the conversation""", ), ] ) context_prompt = ChatPromptTemplate.from_messages( [ ("system", "Answer the user's questions based on the below context:\n\n{context}"), MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ] )Convert the vector store into a retriever, which can search for relevant documents based on specified parameters.
vector_store_retriever = vector_store.as_retriever( search_type=search_type, search_kwargs={"k": limit, "score_threshold": score_threshold} )Create a retriever chain that's aware of the conversation history, ensuring contextually relevant document retrieval using the azure_openai_chat model and vector_store_retriever.
retriever_chain = create_history_aware_retriever(azure_openai_chat, vector_store_retriever, history_prompt)Create a chain that combines retrieved documents into a coherent response using the language model (azure_openai_chat) and a specified prompt (context_prompt).
context_chain = create_stuff_documents_chain(llm=azure_openai_chat, prompt=context_prompt)Create a chain that handles the entire retrieval process, integrating the history-aware retriever chain and the document combination chain. This RAG chain can be executed to retrieve and generate contextually accurate responses.
rag_chain: Runnable = create_retrieval_chain( retriever=retriever_chain, combine_docs_chain=context_chain, )
Sample outputs
The following screenshot illustrates the outputs for various questions. A purely semantic-similarity search returns the raw text from the source documents, while the question-answering app using the RAG architecture generates precise and personalized answers by combining retrieved document contents with the language model.
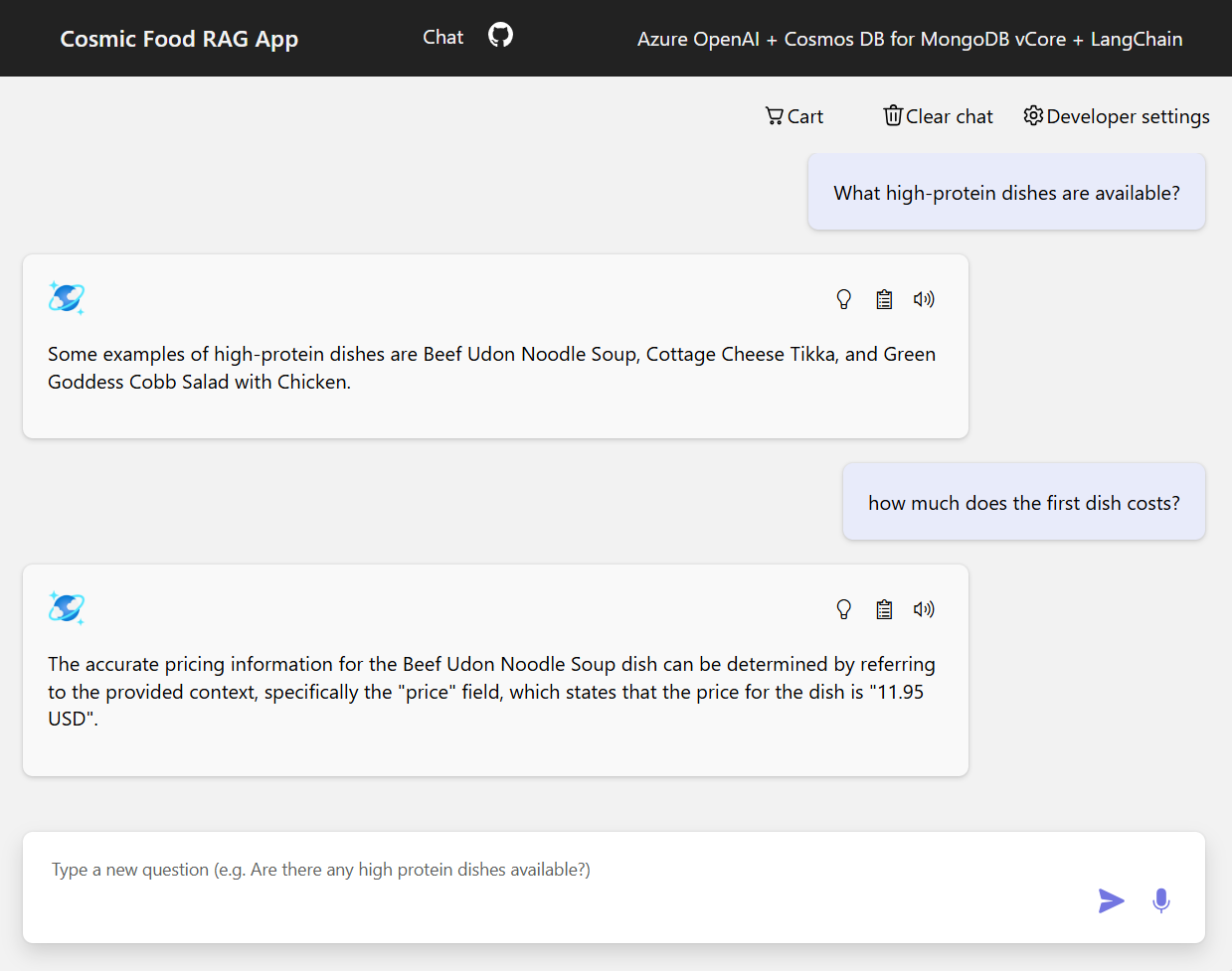
Conclusion
In this tutorial, we explored how to build a question-answering app that interacts with your private data using Azure DocumentDB as a vector store. By using RAG architecture with LangChain and Azure OpenAI, we demonstrated how vector stores are essential for LLM applications.
RAG is a significant advancement in AI, particularly in natural language processing, and combining these technologies allows for the creation of powerful AI-driven applications for various use cases.