Performance tips for Azure Cosmos DB Java SDK v4
APPLIES TO: ![]() NoSQL
NoSQL
Important
The performance tips in this article are for Azure Cosmos DB Java SDK v4 only. Please view the Azure Cosmos DB Java SDK v4 Release notes, Maven repository, and Azure Cosmos DB Java SDK v4 troubleshooting guide for more information. If you are currently using an older version than v4, see the Migrate to Azure Cosmos DB Java SDK v4 guide for help upgrading to v4.
Azure Cosmos DB is a fast and flexible distributed database that scales seamlessly with guaranteed latency and throughput. You do not have to make major architecture changes or write complex code to scale your database with Azure Cosmos DB. Scaling up and down is as easy as making a single API call or SDK method call. However, because Azure Cosmos DB is accessed via network calls there are client-side optimizations you can make to achieve peak performance when using Azure Cosmos DB Java SDK v4.
So if you're asking "How can I improve my database performance?" consider the following options:
Networking
When possible, place any applications calling Azure Cosmos DB in the same region as the Azure Cosmos DB database. For an approximate comparison, calls to Azure Cosmos DB within the same region complete within 1-2 ms, but the latency between the West and East coast of the US is >50 ms. This latency can likely vary from request to request depending on the route taken by the request as it passes from the client to the Azure datacenter boundary. The lowest possible latency is achieved by ensuring the calling application is located within the same Azure region as the provisioned Azure Cosmos DB endpoint. For a list of available regions, see Azure Regions.
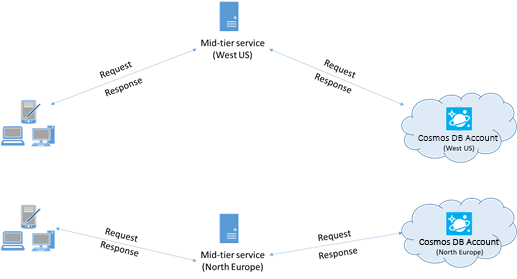
An app that interacts with a multi-region Azure Cosmos DB account needs to configure preferred locations to ensure that requests are going to a collocated region.
Enable accelerated networking to reduce latency and CPU jitter
We strongly recommend following the instructions to enable Accelerated Networking in your Windows (select for instructions) or Linux (select for instructions) Azure VM to maximize the performance by reducing latency and CPU jitter.
Without accelerated networking, IO that transits between your Azure VM and other Azure resources might be routed through a host and virtual switch situated between the VM and its network card. Having the host and virtual switch inline in the datapath not only increases latency and jitter in the communication channel, it also steals CPU cycles from the VM. With accelerated networking, the VM interfaces directly with the NIC without intermediaries. All network policy details are handled in the hardware at the NIC, bypassing the host and virtual switch. Generally you can expect lower latency and higher throughput, as well as more consistent latency and decreased CPU utilization when you enable accelerated networking.
Limitations: accelerated networking must be supported on the VM OS, and can only be enabled when the VM is stopped and deallocated. The VM cannot be deployed with Azure Resource Manager. App Service has no accelerated network enabled.
For more information, see the Windows and Linux instructions.
Tuning direct and gateway connection configuration
For optimizing direct and gateway mode connection configurations, see how to tune connection configurations for java sdk v4.
SDK usage
- Install the most recent SDK
The Azure Cosmos DB SDKs are constantly being improved to provide the best performance. To determine the most recent SDK improvements, visit the Azure Cosmos DB SDK.
Each Azure Cosmos DB client instance is thread-safe and performs efficient connection management and address caching. To allow efficient connection management and better performance by the Azure Cosmos DB client, we strongly recommend using a single instance of the Azure Cosmos DB client for the lifetime of the application.
When you create a CosmosClient, the default consistency used if not explicitly set is Session. If Session consistency is not required by your application logic set the Consistency to Eventual. Note: it is recommended using at least Session consistency in applications employing the Azure Cosmos DB Change Feed processor.
- Use Async API to max out provisioned throughput
Azure Cosmos DB Java SDK v4 bundles two APIs, Sync and Async. Roughly speaking, the Async API implements SDK functionality, whereas the Sync API is a thin wrapper that makes blocking calls to the Async API. This stands in contrast to the older Azure Cosmos DB Async Java SDK v2, which was Async-only, and to the older Azure Cosmos DB Sync Java SDK v2, which was Sync-only and had a separate implementation.
The choice of API is determined during client initialization; a CosmosAsyncClient supports Async API while a CosmosClient supports Sync API.
The Async API implements nonblocking IO and is the optimal choice if your goal is to max out throughput when issuing requests to Azure Cosmos DB.
Using Sync API can be the right choice if you want or need an API, which blocks on the response to each request, or if synchronous operation is the dominant paradigm in your application. For example, you might want the Sync API when you are persisting data to Azure Cosmos DB in a microservices application, provided throughput is not critical.
Note sync API throughput degrades with increasing request response-time, whereas the Async API can saturate the full bandwidth capabilities of your hardware.
Geographic collocation can give you higher and more consistent throughput when using Sync API (see Collocate clients in same Azure region for performance) but still is not expected to exceed Async API attainable throughput.
Some users might also be unfamiliar with Project Reactor, the Reactive Streams framework used to implement Azure Cosmos DB Java SDK v4 Async API. If this is a concern, we recommend you read our introductory Reactor Pattern Guide and then take a look at this Introduction to Reactive Programming in order to familiarize yourself. If you have already used Azure Cosmos DB with an Async interface, and the SDK you used was Azure Cosmos DB Async Java SDK v2, then you might be familiar with ReactiveX/RxJava but be unsure what has changed in Project Reactor. In that case, take a look at our Reactor vs. RxJava Guide to become familiarized.
The following code snippets show how to initialize your Azure Cosmos DB client for Async API or Sync API operation, respectively:
Java SDK V4 (Maven com.azure::azure-cosmos) Async API
CosmosAsyncClient client = new CosmosClientBuilder()
.endpoint(HOSTNAME)
.key(MASTERKEY)
.consistencyLevel(CONSISTENCY)
.buildAsyncClient();
- Scale out your client-workload
If you are testing at high throughput levels, the client application might become the bottleneck due to the machine capping out on CPU or network utilization. If you reach this point, you can continue to push the Azure Cosmos DB account further by scaling out your client applications across multiple servers.
A good rule of thumb is not to exceed >50% CPU utilization on any given server, to keep latency low.
- Use Appropriate Scheduler (Avoid stealing Event loop IO Netty threads)
The asynchronous functionality of Azure Cosmos DB Java SDK is based on netty non-blocking IO. The SDK uses a fixed number of IO netty event loop threads (as many CPU cores your machine has) for executing IO operations. The Flux returned by API emits the result on one of the shared IO event loop netty threads. So it is important to not block the shared IO event loop netty threads. Doing CPU intensive work or blocking operation on the IO event loop netty thread might cause deadlock or significantly reduce SDK throughput.
For example the following code executes a cpu intensive work on the event loop IO netty thread:
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub.subscribe(
itemResponse -> {
//this is executed on eventloop IO netty thread.
//the eventloop thread is shared and is meant to return back quickly.
//
// DON'T do this on eventloop IO netty thread.
veryCpuIntensiveWork();
});
After the result is received, you should avoid doing any CPU intensive work on the result on the event loop IO netty thread. You can instead provide your own Scheduler to provide your own thread for running your work, as shown below (requires import reactor.core.scheduler.Schedulers).
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub
.publishOn(Schedulers.parallel())
.subscribe(
itemResponse -> {
//this is now executed on reactor scheduler's parallel thread.
//reactor scheduler's parallel thread is meant for CPU intensive work.
veryCpuIntensiveWork();
});
Based on the type of your work, you should use the appropriate existing Reactor Scheduler for your work. Read here
Schedulers.
To further understand the threading and scheduling model of project Reactor, refer to this blog post by Project Reactor.
For more information on Azure Cosmos DB Java SDK v4, look at the Azure Cosmos DB directory of the Azure SDK for Java monorepo on GitHub.
- Optimize logging settings in your application
For various reasons, you should add logging in a thread that is generating high request throughput. If your goal is to fully saturate a container's provisioned throughput with requests generated by this thread, logging optimizations can greatly improve performance.
- Configure an async logger
The latency of a synchronous logger necessarily factors into the overall latency calculation of your request-generating thread. An async logger such as log4j2 is recommended to decouple logging overhead from your high-performance application threads.
- Disable netty's logging
Netty library logging is chatty and needs to be turned off (suppressing sign in the configuration might not be enough) to avoid additional CPU costs. If you are not in debugging mode, disable netty's logging altogether. So if you are using Log4j to remove the additional CPU costs incurred by org.apache.log4j.Category.callAppenders() from netty add the following line to your codebase:
org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);
- OS Open files Resource Limit
Some Linux systems (like Red Hat) have an upper limit on the number of open files and so the total number of connections. Run the following to view the current limits:
ulimit -a
The number of open files (nofile) needs to be large enough to have enough room for your configured connection pool size and other open files by the OS. It can be modified to allow for a larger connection pool size.
Open the limits.conf file:
vim /etc/security/limits.conf
Add/modify the following lines:
* - nofile 100000
- Specify partition key in point writes
To improve the performance of point writes, specify item partition key in the point write API call, as shown below:
Java SDK V4 (Maven com.azure::azure-cosmos) Async API
asyncContainer.createItem(item,new PartitionKey(pk),new CosmosItemRequestOptions()).block();
Rather than providing only the item instance, as shown below:
Java SDK V4 (Maven com.azure::azure-cosmos) Async API
asyncContainer.createItem(item).block();
The latter is supported but will add latency to your application; the SDK must parse the item and extract the partition key.
Query operations
For query operations, see the performance tips for queries.
Indexing policy
- Exclude unused paths from indexing for faster writes
Azure Cosmos DB’s indexing policy allows you to specify which document paths to include or exclude from indexing by using Indexing Paths (setIncludedPaths and setExcludedPaths). The use of indexing paths can offer improved write performance and lower index storage for scenarios in which the query patterns are known beforehand, as indexing costs are directly correlated to the number of unique paths indexed. For example, the following code shows how to include and exclude entire sections of the documents (also known as a subtree) from indexing using the "*" wildcard.
CosmosContainerProperties containerProperties = new CosmosContainerProperties(containerName, "/lastName");
// Custom indexing policy
IndexingPolicy indexingPolicy = new IndexingPolicy();
indexingPolicy.setIndexingMode(IndexingMode.CONSISTENT);
// Included paths
List<IncludedPath> includedPaths = new ArrayList<>();
includedPaths.add(new IncludedPath("/*"));
indexingPolicy.setIncludedPaths(includedPaths);
// Excluded paths
List<ExcludedPath> excludedPaths = new ArrayList<>();
excludedPaths.add(new ExcludedPath("/name/*"));
indexingPolicy.setExcludedPaths(excludedPaths);
containerProperties.setIndexingPolicy(indexingPolicy);
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
database.createContainerIfNotExists(containerProperties, throughputProperties);
CosmosAsyncContainer containerIfNotExists = database.getContainer(containerName);
For more information, see Azure Cosmos DB indexing policies.
Throughput
- Measure and tune for lower request units/second usage
Azure Cosmos DB offers a rich set of database operations including relational and hierarchical queries with UDFs, stored procedures, and triggers – all operating on the documents within a database collection. The cost associated with each of these operations varies based on the CPU, IO, and memory required to complete the operation. Instead of thinking about and managing hardware resources, you can think of a request unit (RU) as a single measure for the resources required to perform various database operations and service an application request.
Throughput is provisioned based on the number of request units set for each container. Request unit consumption is evaluated as a rate per second. Applications that exceed the provisioned request unit rate for their container are limited until the rate drops below the provisioned level for the container. If your application requires a higher level of throughput, you can increase your throughput by provisioning additional request units.
The complexity of a query impacts how many request units are consumed for an operation. The number of predicates, nature of the predicates, number of UDFs, and the size of the source data set all influence the cost of query operations.
To measure the overhead of any operation (create, update, or delete), inspect the x-ms-request-charge header to measure the number of request units consumed by these operations. You can also look at the equivalent RequestCharge property in ResourceResponse<T> or FeedResponse<T>.
Java SDK V4 (Maven com.azure::azure-cosmos) Async API
CosmosItemResponse<CustomPOJO> response = asyncContainer.createItem(item).block();
response.getRequestCharge();
The request charge returned in this header is a fraction of your provisioned throughput. For example, if you have 2000 RU/s provisioned, and if the preceding query returns 1,000 1KB documents, the cost of the operation is 1000. As such, within one second, the server honors only two such requests before rate limiting subsequent requests. For more information, see Request units and the request unit calculator.
- Handle rate limiting/request rate too large
When a client attempts to exceed the reserved throughput for an account, there is no performance degradation at the server and no use of throughput capacity beyond the reserved level. The server will preemptively end the request with RequestRateTooLarge (HTTP status code 429) and return the x-ms-retry-after-ms header indicating the amount of time, in milliseconds, that the user must wait before reattempting the request.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
The SDKs all implicitly catch this response, respect the server-specified retry-after header, and retry the request. Unless your account is being accessed concurrently by multiple clients, the next retry will succeed.
If you have more than one client cumulatively operating consistently above the request rate, the default retry count currently set to 9 internally by the client might not suffice; in this case, the client throws a CosmosClientException with status code 429 to the application. The default retry count can be changed by using setMaxRetryAttemptsOnThrottledRequests() on the ThrottlingRetryOptions instance. By default, the CosmosClientException with status code 429 is returned after a cumulative wait time of 30 seconds if the request continues to operate above the request rate. This occurs even when the current retry count is less than the max retry count, be it the default of 9 or a user-defined value.
While the automated retry behavior helps to improve resiliency and usability for the most applications, it might come at odds when doing performance benchmarks, especially when measuring latency. The client-observed latency will spike if the experiment hits the server throttle and causes the client SDK to silently retry. To avoid latency spikes during performance experiments, measure the charge returned by each operation and ensure that requests are operating below the reserved request rate. For more information, see Request units.
- Design for smaller documents for higher throughput
The request charge (the request processing cost) of a given operation is directly correlated to the size of the document. Operations on large documents cost more than operations for small documents. Ideally, architect your application and workflows to have your item size be ~1 KB, or similar order or magnitude. For latency-sensitive applications large items should be avoided - multi-MB documents slow down your application.
Next steps
To learn more about designing your application for scale and high performance, see Partitioning and scaling in Azure Cosmos DB.
Trying to do capacity planning for a migration to Azure Cosmos DB? You can use information about your existing database cluster for capacity planning.
- If all you know is the number of vCores and servers in your existing database cluster, read about estimating request units using vCores or vCPUs
- If you know typical request rates for your current database workload, read about estimating request units using Azure Cosmos DB capacity planner
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for