Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() Cassandra
Cassandra
![]() Gremlin
Gremlin
![]() Table
Table
Living in a massively interconnected society means that, at some point in life, you become part of a social network. You use social networks to keep in touch with friends, colleagues, family, or sometimes to share your passion with people with common interests.
As engineers or developers, you might have wondered how do these networks store and interconnect your data. Or you might have even been tasked to create or architect a new social network for a specific niche market. That’s when the significant question arises: How is all this data stored?
Suppose you're creating a new and shiny social network where your users can post articles with related media, like pictures, videos, or even music. Users can comment on posts and give points for ratings. There will be a feed of posts that users will see and interact with on the main website landing page. This method doesn’t sound complex at first, but for the sake of simplicity, let’s stop there. (You can delve into custom user feeds affected by relationships, but it goes beyond the goal of this article.)
So, how do you store this data and where?
You might have experience on SQL databases or have a notion of relational modeling of data. You may start drawing something as follows:
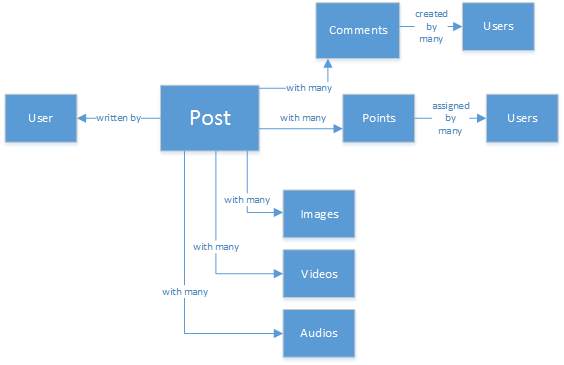
A perfectly normalized and pretty data structure... that doesn't scale.
Don’t get me wrong, I’ve worked with SQL databases all my life. They're great, but like every pattern, practice and software platform, it’s not perfect for every scenario.
Why isn't SQL the best choice in this scenario? Let’s look at the structure of a single post. If I wanted to show the post in a website or application, I’d have to do a query with... by joining eight tables(!) just to show one single post. Now picture a stream of posts that dynamically load and appear on the screen, and you might see where I'm going.
You could use an enormous SQL instance with enough power to solve thousands of queries with many joins to serve your content. But why would you, when a simpler solution exists?
The NoSQL road
This article guides you into modeling your social platform's data with Azure's NoSQL database Azure Cosmos DB cost-effectively. It also tells you how to use other Azure Cosmos DB features like the API for Gremlin. Using a NoSQL approach, storing data, in JSON format and applying denormalization, the previously complicated post can be transformed into a single Document:
{
"id":"ew12-res2-234e-544f",
"title":"post title",
"date":"2016-01-01",
"body":"this is an awesome post stored on NoSQL",
"createdBy":User,
"images":["https://myfirstimage.png","https://mysecondimage.png"],
"videos":[
{"url":"https://myfirstvideo.mp4", "title":"The first video"},
{"url":"https://mysecondvideo.mp4", "title":"The second video"}
],
"audios":[
{"url":"https://myfirstaudio.mp3", "title":"The first audio"},
{"url":"https://mysecondaudio.mp3", "title":"The second audio"}
]
}
And it can be gotten with a single query, and with no joins. This query is much simple and straightforward, and, budget-wise, it requires fewer resources to achieve a better result.
Azure Cosmos DB makes sure that all properties are indexed with its automatic indexing. The automatic indexing can even be customized. The schema-free approach lets us store documents with different and dynamic structures. Maybe tomorrow you want posts to have a list of categories or hashtags associated with them? Azure Cosmos DB handles the new Documents with the added attributes without extra work required by us.
Comments on a post can be treated as other posts with a parent property. (This practice simplifies your object mapping.)
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":User2,
"parent":"ew12-res2-234e-544f"
}
{
"id":"asd2-fee4-23gc-jh67",
"title":"Ditto!",
"date":"2016-01-03",
"createdBy":User3,
"parent":"ew12-res2-234e-544f"
}
And all social interactions can be stored on a separate object as counters:
{
"id":"dfe3-thf5-232s-dse4",
"post":"ew12-res2-234e-544f",
"comments":2,
"likes":10,
"points":200
}
Creating feeds is just a matter of creating documents that can hold a list of post IDs with a given relevance order:
[
{"relevance":9, "post":"ew12-res2-234e-544f"},
{"relevance":8, "post":"fer7-mnb6-fgh9-2344"},
{"relevance":7, "post":"w34r-qeg6-ref6-8565"}
]
You could have a "latest" stream with posts ordered by creation date. Or you could have a "hottest" stream with those posts with more likes in the last 24 hours. You could even implement a custom stream for each user based on logic like followers and interests. It would still be a list of posts. It’s a matter of how to build these lists, but the reading performance stays unhindered. Once you acquire one of these lists, you issue a single query to Azure Cosmos DB using the IN keyword to get pages of posts at a time.
The feed streams could be built using Azure App Services’ background processes: Webjobs. Once a post is created, background processing can be triggered by using Azure Storage Queues and Webjobs triggered using the Azure Webjobs SDK, implementing the post propagation inside streams based on your own custom logic.
Points and likes over a post can be processed in a deferred manner using this same technique to create an eventually consistent environment.
Followers are trickier. Azure Cosmos DB has a document size limit, and reading/writing large documents can impact the scalability of your application. So you may think about storing followers as a document with this structure:
{
"id":"234d-sd23-rrf2-552d",
"followersOf": "dse4-qwe2-ert4-aad2",
"followers":[
"ewr5-232d-tyrg-iuo2",
"qejh-2345-sdf1-ytg5",
//...
"uie0-4tyg-3456-rwjh"
]
}
This structure might work for a user with a few thousands followers. If some celebrity joins the ranks, however, this approach leads to a large document size, and it might eventually hit the document size cap.
To solve this problem, you can use a mixed approach. As part of the User Statistics document you can store the number of followers:
{
"id":"234d-sd23-rrf2-552d",
"user": "dse4-qwe2-ert4-aad2",
"followers":55230,
"totalPosts":452,
"totalPoints":11342
}
You can store the actual graph of followers using Azure Cosmos DB API for Gremlin to create vertexes for each user and edges that maintain the "A-follows-B" relationships. With the API for Gremlin, you can get the followers of a certain user and create more complex queries to suggest people in common. If you add to the graph the Content Categories that people like or enjoy, you can start weaving experiences that include smart content discovery, suggesting content that those people you follow like, or finding people that you might have much in common with.
The User Statistics document can still be used to create cards in the UI or quick profile previews.
The "Ladder" pattern and data duplication
As you might have noticed in the JSON document that references a post, there are many occurrences of a user. And you’d have guessed right, these duplicates mean that the information that describes a user, given this denormalization, might be present in more than one place.
To allow for faster queries, you incur data duplication. The problem with this side effect is that if by some action, a user’s data changes, you need to find all the activities the user ever did and update them all. Doesn’t sound practical, right?
You're going to solve it by identifying the key attributes of a user that you show in your application for each activity. If you visually show a post in your application and show just the creator’s name and picture, why store all of the user’s data in the "createdBy" attribute? If for each comment you just show the user’s picture, you don’t really need the rest of the user's information. That’s where something I call the "Ladder pattern" becomes involved.
Let’s take user information as an example:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"address":"742 Evergreen Terrace",
"birthday":"1983-05-07",
"email":"john@doe.com",
"twitterHandle":"\@john",
"username":"johndoe",
"password":"some_encrypted_phrase",
"totalPoints":100,
"totalPosts":24
}
By looking at this information, you can quickly detect which is critical information and which isn’t, thus creating a "Ladder":

The smallest step is called a UserChunk, the minimal piece of information that identifies a user and it’s used for data duplication. By reducing the duplicated data size to only the information you'll "show", you reduce the possibility of massive updates.
The middle step is called the user. It’s the full data that is used on most performance-dependent queries on Azure Cosmos DB, the most accessed and critical. It includes the information represented by a UserChunk.
The largest is the Extended User. It includes the critical user information and other data that doesn’t need to be read quickly or has eventual usage, like the sign-in process. This data can be stored outside of Azure Cosmos DB, in Azure SQL Database or Azure Storage Tables.
Why would you split the user and even store this information in different places? Because from a performance point of view, the bigger the documents, the costlier the queries. Keep documents slim, with the right information to do all your performance-dependent queries for your social network. Store the other extra information for eventual scenarios like full profile edits, logins, and data mining for usage analytics and Big Data initiatives. You really don’t care if the data gathering for data mining is slower, because it’s running on Azure SQL Database. You do have concern though that your users have a fast and slim experience. A user stored on Azure Cosmos DB would look like this code:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"username":"johndoe"
"email":"john@doe.com",
"twitterHandle":"\@john"
}
And a Post would look like:
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":{
"id":"dse4-qwe2-ert4-aad2",
"username":"johndoe"
}
}
When an edit arises where a chunk attribute is affected, you can easily find the affected documents. Just use queries that point to the indexed attributes, such as SELECT * FROM posts p WHERE p.createdBy.id == "edited_user_id", and then update the chunks.
The search box
Users generate, luckily, much content. And you should be able to provide the ability to search and find content that might not be directly in their content streams, maybe because you don’t follow the creators, or maybe you're just trying to find that old post you did six months ago.
Because you're using Azure Cosmos DB, you can easily implement a search engine using Azure AI Search in a few minutes without typing any code, other than the search process and UI.
Why is this process so easy?
Azure AI Search implements what they call Indexers, background processes that hook in your data repositories and automagically add, update or remove your objects in the indexes. They support an Azure SQL Database indexers, Azure Blobs indexers and thankfully, Azure Cosmos DB indexers. The transition of information from Azure Cosmos DB to Azure AI Search is straightforward. Both technologies store information in JSON format, so you just need to create your Index and map the attributes from your Documents you want indexed. That’s it! Depending on the size of your data, all your content is available to be searched upon within minutes by the best Search-as-a-Service solution in cloud infrastructure.
For more information about Azure AI Search, you can visit the Hitchhiker’s Guide to Search.
The underlying knowledge
After storing all this content that grows and grows every day, you might find thinking: What can I do with all this stream of information from my users?
The answer is straightforward: Put it to work and learn from it.
But what can you learn? A few easy examples include sentiment analysis, content recommendations based on a user’s preferences, or even an automated content moderator that makes sure the content published by your social network is safe for the family.
Now that I got you hooked, you’ll probably think you need some PhD in math science to extract these patterns and information out of simple databases and files, but you’d be wrong.
Azure Machine Learning, is a fully managed cloud service that lets you create workflows using algorithms in a simple drag-and-drop interface, code your own algorithms in R, or use some of the already-built and ready to use APIs such as: Text Analytics, Content Moderator, or Recommendations.
To achieve any of these Machine Learning scenarios, you can use Azure Data Lake to ingest the information from different sources. You can also use U-SQL to process the information and generate an output that can be processed by Azure Machine Learning.
Another available option is to use Azure AI services to analyze your users content; not only can you understand them better (through analyzing what they write with Text Analytics API), but you could also detect unwanted or mature content and act accordingly with Computer Vision API. Azure AI services include many out-of-the-box solutions that don't require any kind of Machine Learning knowledge to use.
A planet-scale social experience
There's a last, but not least, important article I must address: scalability. When you design an architecture, each component should scale on its own. You'll eventually need to process more data, or you'll want to have a bigger geographical coverage. Thankfully, achieving both tasks is a turnkey experience with Azure Cosmos DB.
Azure Cosmos DB supports dynamic partitioning out-of-the-box. It automatically creates partitions based on a given partition key, which is defined as an attribute in your documents. Defining the correct partition key must be done at design time. For more information, see Partitioning in Azure Cosmos DB.
For a social experience, you must align your partitioning strategy with the way you query and write. (For example, reads within the same partition are desirable, and avoid "hot spots" by spreading writes on multiple partitions.) Some options are: partitions based on a temporal key (day/month/week), by content category, by geographical region, or by user. It all really depends on how you query the data and show the data in your social experience.
Azure Cosmos DB runs your queries (including aggregates) across all your partitions transparently, so you don't need to add any logic as your data grows.
With time, you'll eventually grow in traffic and your resource consumption (measured in RUs, or Request Units) will increase. You'll read and write more frequently as your user base grows. The user base starts creating and reading more content. So the ability of scaling your throughput is vital. Increasing your RUs is easy. You can do it with a few select on the Azure portal or by issuing commands through the API.
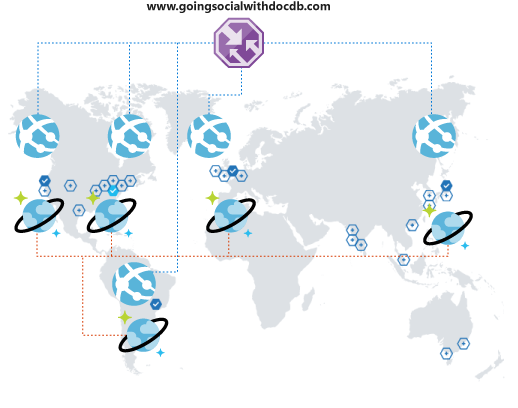
What happens if things keep getting better? Suppose users from another country/region or continent notice your platform and start using it. What a great surprise!
But wait! You soon realize their experience with your platform isn't optimal. They're so far away from your operational region that the latency is terrible. You obviously don't want them to quit. If only there was an easy way of extending your global reach? There is!
Azure Cosmos DB lets you replicate your data globally and transparently with a couple of select and automatically select among the available regions from your client code. This process also means that you can have multiple failover regions.
When you replicate your data globally, you need to make sure that your clients can take advantage of it. If you're using a web frontend or accessing APIs from mobile clients, you can deploy Azure Traffic Manager and clone your Azure App Service on all the desired regions, using a performance configuration to support your extended global coverage. When your clients access your frontend or APIs, they are routed to the closest App Service, which in turn, will connect to the local Azure Cosmos DB replica.
Conclusion
This article sheds some light into the alternatives of creating social networks completely on Azure with low-cost services. It delivers results by encouraging the use of a multi-layered storage solution and data distribution called "Ladder".
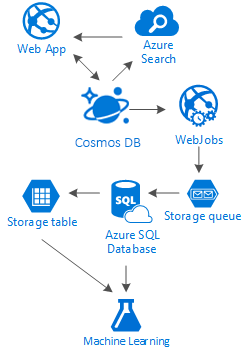
The truth is that there's no silver bullet for this kind of scenarios. It’s the synergy created by the combination of great services that allow us to build great experiences: the speed and freedom of Azure Cosmos DB to provide a great social application, the intelligence behind a first-class search solution like Azure AI Search, the flexibility of Azure App Services to host not even language-agnostic applications but powerful background processes and the expandable Azure Storage and Azure SQL Database for storing massive amounts of data and the analytic power of Azure Machine Learning to create knowledge and intelligence that can provide feedback to your processes and help us deliver the right content to the right users.
Next steps
To learn more about use cases for Azure Cosmos DB, see Common Azure Cosmos DB use cases.