Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Azure Data Lake Storage is a highly scalable and cost-effective data lake solution for big data analytics. It combines the power of a high-performance file system with massive scale and economy to help you reduce your time to insight. Data Lake Storage Gen2 extends Azure Blob Storage capabilities and is optimized for analytics workloads.
Azure Data Explorer integrates with Azure Blob Storage and Azure Data Lake Storage (Gen1 and Gen2), providing fast, cached, and indexed access to data stored in external storage. You can analyze and query data without prior ingestion into Azure Data Explorer. You can also query across ingested and uningested external data simultaneously. For more information, see how to create an external table using the Azure Data Explorer web UI wizard. For a brief overview, see external tables.
Tip
The best query performance necessitates data ingestion into Azure Data Explorer. The capability to query external data without prior ingestion should only be used for historical data or data that are rarely queried. Optimize your external data query performance for best results.
Create an external table
Let's say you have lots of CSV files containing historical info on products stored in a warehouse, and you want to do a quick analysis to find the five most popular products from last year. In this example, the CSV files look like:
| Timestamp | ProductId | ProductDescription |
|---|---|---|
| 2019-01-01 11:21:00 | TO6050 | 3.5in DS/HD Floppy Disk |
| 2019-01-01 11:30:55 | YDX1 | Yamaha DX1 Synthesizer |
| ... | ... | ... |
The files are stored in Azure Blob storage mycompanystorage under a container named archivedproducts, partitioned by date:
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00000-7e967c99-cf2b-4dbb-8c53-ce388389470d.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00001-ba356fa4-f85f-430a-8b5a-afd64f128ca4.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00002-acb644dc-2fc6-467c-ab80-d1590b23fc31.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00003-cd5fad16-a45e-4f8c-a2d0-5ea5de2f4e02.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/02/part-00000-ffc72d50-ff98-423c-913b-75482ba9ec86.csv.gz
...
To run a KQL query on these CSV files directly, use the .create external table command to define an external table in Azure Data Explorer. For more information on external table create command options, see external table commands.
.create external table ArchivedProducts(Timestamp:datetime, ProductId:string, ProductDescription:string)
kind=blob
partition by (Date:datetime = bin(Timestamp, 1d))
dataformat=csv
(
h@'https://mycompanystorage.blob.core.windows.net/archivedproducts;StorageSecretKey'
)
The external table is now visible in the left pane of the Azure Data Explorer web UI:
External table permissions
Review the following table permissions:
- The database user can create an external table. The table creator automatically becomes the table administrator.
- The cluster, database, or table administrator can edit an existing table.
- Any database user or reader can query an external table.
Querying an external table
Once an external table is defined, the external_table() function can be used to refer to it. The rest of the query is standard Kusto Query Language.
external_table("ArchivedProducts")
| where Timestamp > ago(365d)
| summarize Count=count() by ProductId,
| top 5 by Count
Querying external and ingested data together
You can query both external tables and ingested data tables within the same query. You can join or union the external table with other data from Azure Data Explorer, SQL servers, or other sources. Use a let( ) statement to assign a shorthand name to an external table reference.
In the example below, Products is an ingested data table and ArchivedProducts is an external table that we've defined:
let T1 = external_table("ArchivedProducts") | where TimeStamp > ago(100d);
let T = Products; //T is an internal table
T1 | join T on ProductId | take 10
Querying hierarchical data formats
Azure Data Explorer allows querying hierarchical formats, such as JSON, Parquet, Avro, and ORC. To map hierarchical data schema to an external table schema (if it's different), use external table mappings commands. For instance, if you want to query JSON log files with the following format:
{
"timestamp": "2019-01-01 10:00:00.238521",
"data": {
"tenant": "aaaabbbb-0000-cccc-1111-dddd2222eeee",
"method": "RefreshTableMetadata"
}
}
{
"timestamp": "2019-01-01 10:00:01.845423",
"data": {
"tenant": "bbbbcccc-1111-dddd-2222-eeee3333ffff",
"method": "GetFileList"
}
}
...
The external table definition looks like this:
.create external table ApiCalls(Timestamp: datetime, TenantId: guid, MethodName: string)
kind=blob
dataformat=multijson
(
h@'https://storageaccount.blob.core.windows.net/container1;StorageSecretKey'
)
Define a JSON mapping that maps data fields to external table definition fields:
.create external table ApiCalls json mapping 'MyMapping' '[{"Column":"Timestamp","Properties":{"Path":"$.timestamp"}},{"Column":"TenantId","Properties":{"Path":"$.data.tenant"}},{"Column":"MethodName","Properties":{"Path":"$.data.method"}}]'
When you query the external table, the mapping is invoked, and relevant data mapped to the external table columns:
external_table('ApiCalls') | take 10
For more info on mapping syntax, see data mappings.
Query TaxiRides external table in the help cluster
Use the test cluster called help to try out different Azure Data Explorer capabilities. The help cluster contains an external table definition for a New York City taxi dataset containing billions of taxi rides.
Create external table TaxiRides
This section shows the query used to create the TaxiRides external table in the help cluster. Since you already created this table, you can skip this section and go directly to query TaxiRides external table data.
.create external table TaxiRides
(
trip_id: long,
vendor_id: string,
pickup_datetime: datetime,
dropoff_datetime: datetime,
store_and_fwd_flag: string,
rate_code_id: int,
pickup_longitude: real,
pickup_latitude: real,
dropoff_longitude: real,
dropoff_latitude: real,
passenger_count: int,
trip_distance: real,
fare_amount: real,
extra: real,
mta_tax: real,
tip_amount: real,
tolls_amount: real,
ehail_fee: real,
improvement_surcharge: real,
total_amount: real,
payment_type: string,
trip_type: int,
pickup: string,
dropoff: string,
cab_type: string,
precipitation: int,
snow_depth: int,
snowfall: int,
max_temperature: int,
min_temperature: int,
average_wind_speed: int,
pickup_nyct2010_gid: int,
pickup_ctlabel: string,
pickup_borocode: int,
pickup_boroname: string,
pickup_ct2010: string,
pickup_boroct2010: string,
pickup_cdeligibil: string,
pickup_ntacode: string,
pickup_ntaname: string,
pickup_puma: string,
dropoff_nyct2010_gid: int,
dropoff_ctlabel: string,
dropoff_borocode: int,
dropoff_boroname: string,
dropoff_ct2010: string,
dropoff_boroct2010: string,
dropoff_cdeligibil: string,
dropoff_ntacode: string,
dropoff_ntaname: string,
dropoff_puma: string
)
kind=blob
partition by (Date:datetime = bin(pickup_datetime, 1d))
dataformat=csv
(
h@'https://storageaccount.blob.core.windows.net/container1;secretKey'
)
You can find the created TaxiRides table by looking at the left pane of the Azure Data Explorer web UI.
Query TaxiRides external table data
Sign in to https://dataexplorer.azure.com/clusters/help/databases/Samples.
Query TaxiRides external table without partitioning
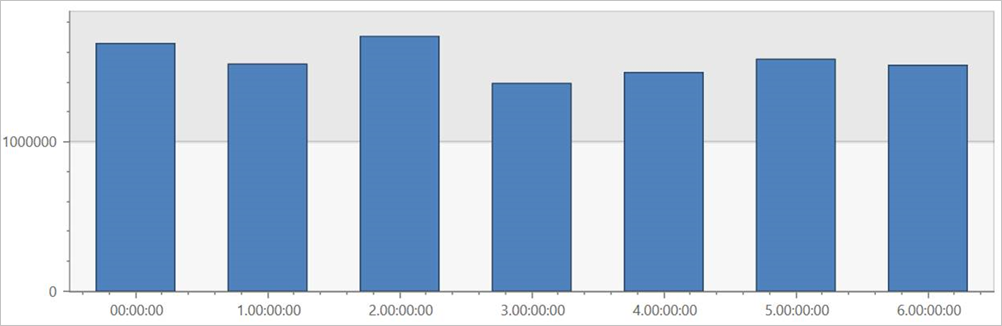
Run this query on the external table TaxiRides to show rides for each day of the week, across the entire dataset.
external_table("TaxiRides")
| summarize count() by dayofweek(pickup_datetime)
| render columnchart
This query shows the busiest day of the week. Since the data isn't partitioned, the query may take up to several minutes to return results.
Query TaxiRides external table with partitioning
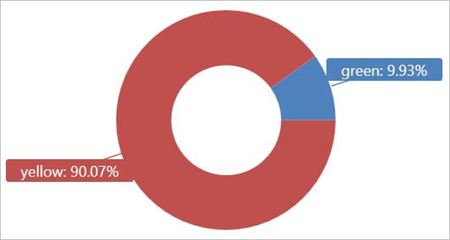
Run this query on the external table TaxiRides to show taxi cab types (yellow or green) used in January of 2017.
external_table("TaxiRides")
| where pickup_datetime between (datetime(2017-01-01) .. datetime(2017-02-01))
| summarize count() by cab_type
| render piechart
This query uses partitioning, which optimizes query time and performance. The query filters on a partitioned column (pickup_datetime) and returns results in a few seconds.
You can write other queries to run on the external table TaxiRides and learn more about the data.
Optimize your query performance
Optimize your query performance in the lake by using the following best practices for querying external data.
Data format
- Use a columnar format for analytical queries, for the following reasons:
- Only the columns relevant to a query can be read.
- Column encoding techniques can reduce data size significantly.
- Azure Data Explorer supports Parquet and ORC columnar formats. Parquet format is suggested because of optimized implementation.
Azure region
Check that external data is in the same Azure region as your Azure Data Explorer cluster. This setup reduces cost and data fetch time.
File size
The optimal file size is hundreds of Mb (up to 1 GB) per file. Avoid many small files that require unneeded overhead, such as slower file enumeration process and limited use of columnar format. The number of files should be greater than the number of CPU cores in your Azure Data Explorer cluster.
Compression
Use compression to reduce the amount of data being fetched from the remote storage. For Parquet format, use the internal Parquet compression mechanism that compresses column groups separately, allowing you to read them separately. To validate use of compression mechanism, check that the files are named as follows: <filename>.gz.parquet or <filename>.snappy.parquet and not <filename>.parquet.gz.
Partitioning
Organize your data using "folder" partitions that enable the query to skip irrelevant paths. When planning partitioning, consider file size and common filters in your queries such as timestamp or tenant ID.
VM size
Select VM SKUs with more cores and higher network throughput (memory is less important). For more information, see Select the correct VM SKU for your Azure Data Explorer cluster.