Choose the right integration runtime configuration for your scenario
The integration runtime is an important part of the infrastructure for the data integration solution provided by Azure Data Factory. This requires you to fully consider how to adapt to the existing network structure and data source at the beginning of designing the solution, as well as consider performance, security, and cost.
Comparison of different types of integration runtimes
In Azure Data Factory, we have three kinds of integration runtimes: the Azure integration runtime, the self-hosted integration runtime and the Azure-SSIS integration runtime. For the Azure integration runtime, you can also enable a managed virtual network, which makes its architecture different than the global Azure integration runtime.
This table lists the differences in some aspects of all integration runtimes. You can choose the appropriate one according to your actual needs. For the Azure-SSIS integration runtime, you can learn more in the article Create an Azure-SSIS integration runtime.
| Feature | Azure integration runtime | Azure integration runtime with managed virtual network | Self-hosted integration runtime |
|---|---|---|---|
| Managed compute | Y | Y | N |
| Autoscale | Y | Y* | N |
| Dataflow | Y | Y | N |
| On-premises data access | N | Y** | Y |
| Private Link/Private Endpoint | N | Y*** | Y |
| Custom component/driver | N | N | Y |
* When time-to-live (TTL) is enabled, the compute size of integration runtime is reserved according to the configuration and can’t be autoscaled.
** On-premises environments must be connected to Azure via Express Route or VPN. Custom components and drivers aren't supported.
*** The private endpoints are managed by the Azure Data Factory service.
It's important to choose an appropriate type of integration runtime. Not only must it be suitable for your existing architecture and requirements for data integration, but you also need to consider how to further meet growing business needs and any future increase in workload. But there's no one-size-fits-all approach. The following consideration can help you navigate the decision:
What are the integration runtime and data store locations?
The integration runtime location defines the location of its back-end compute, and where the data movement, activity dispatching and data transformation are performed. To obtain better performance and transmission efficiency, the integration runtime should be closer to the data source or sink.- The Azure integration runtime automatically detects the most suitable location based on some rules (also known as autoresolve). See details here: Azure IR location.
- The Azure integration runtime with a managed virtual network has the same region as your data factory. It can’t be auto resolved like the Azure integration runtime.
- The self-hosted integration runtime is located in the region of your local machines or Azure virtual machines.
Is the data store publicly accessible?
If the data store is publicly accessible, the difference between the different types of integration runtimes isn't large. If the store is behind a firewall or in a private network such as an on-premises or virtual network, the better choices are the Azure integration runtime with a managed virtual network or the self-hosted integration runtime.- There's some extra setup needed such as Private Link Service and Load Balancer when using the Azure integration runtime with a managed virtual network to access a data store behind a firewall or in a private network. You can refer to this tutorial Access on-premises SQL Server from Data Factory Managed VNet using Private Endpoint as an example. If the data store is in an on-premises environment, then the on-premises must be connected to Azure via Express Route or an S2S VPN.
- The self-hosted integration runtime is more flexible and doesn't require extra settings, Express Route, or VPN. But you need to provide and maintain the machine by yourself.
- You can also add the public IP addresses of the Azure integration runtime to the allowlist of your firewall and allow it to access the data store, but it’s not a desirable solution in highly secure production environments.
What level of security do you require during data transmission?
If you need to process highly confidential data, you want to defend against, for example, man-in-the-middle attacks during data transmission. Then you can choose to use a Private Endpoint and Private Link to ensure data security.- You can create managed private endpoints to your data stores when using the Azure integration runtime with a managed virtual network. The private endpoints are maintained by the Azure Data Factory service within the managed virtual network.
- You can also create private endpoints in your virtual network and the self-hosted integration runtime can use them to access data stores.
- The Azure integration runtime doesn’t support Private Endpoint and Private Link.
What level of maintenance are you able to provide?
Maintaining infrastructure, servers, and equipment is one of the important tasks of the IT department of an enterprise. It usually takes a lot of time and effort.- You don’t need to worry about the maintenance such as update, patch, and version of the Azure integration runtime and the Azure integration runtime with a managed virtual network. The Azure Data Factory service takes care of all the maintenance efforts.
- Because the self-hosted integration runtime is installed on customer machines, the maintenance must be taken care of by end users. You can, however, enable autoupdate to automatically get the latest version of the self-hosted integration runtime whenever there's an update. To learn about how to enable autoupdate and manage version control of the self-hosted integration runtime, you can refer to the article Self-hosted integration runtime autoupdate and expire notification. We also provide a diagnostic tool for the self-hosted integration runtime to health-check some common issues. To learn more about the diagnostic tool, refer to the article Self-hosted integration runtime diagnostic tool. In addition, we recommend using Azure Monitor and Azure Log Analytics specifically to collect that data and enable a single pane of glass monitoring for your self-hosted integration runtimes. Learn more about configuring this in the article Configure the self-hosted integration runtime for log analytics collection for instructions.
What concurrency requirements do you have?
When processing large-scale data, such as large-scale data migration, we hope to improve the efficiency and speed of processing as much as possible. Concurrency is often a major requirement for data integration.- The Azure integration runtime has the highest concurrency support among all integration runtime types. Data integration unit (DIU) is the unit of capability to run on Azure Data Factory. You can select the desired number of DIU for example, Copy activity. Within the scope of DIU, you can run multiple activities at the same time. For different region groups, we'll have different upper limitations. Learn about the details of these limits in the article Data Factory limits.
- The Azure integration runtime with a managed virtual network has a similar mechanism to the Azure integration runtime, but due to some architectural constraints, the concurrency it can support is less than Azure integration runtime.
- The concurrent activities that the self-hosted integration runtime can run depend on the machine size and cluster size. You can choose a larger machine or use more self-hosted integration nodes in the cluster if you need greater concurrency.
Do you require any specific features?
There are some functional differences between the types of integration runtimes.- Dataflow is supported by the Azure integration runtime and the Azure integration runtime with a managed virtual network. However, you can’t run Dataflow using self-hosted integration runtime.
- If you need to install custom components, such as ODBC drivers, a JVM, or a SQL Server certificate, the self-hosted integration runtime is your only option. Custom components aren't supported by the Azure integration runtime or the Azure integration runtime with a managed virtual network.
Architecture for integration runtime
Based on the characteristics of each integration runtime, different architectures are required to meet the business needs of data integration. The following are some typical architectures that can be used as a reference.
Azure integration runtime
The Azure integration runtime is a fully managed, autoscaled compute that you can use to move data from Azure or non-Azure data sources.
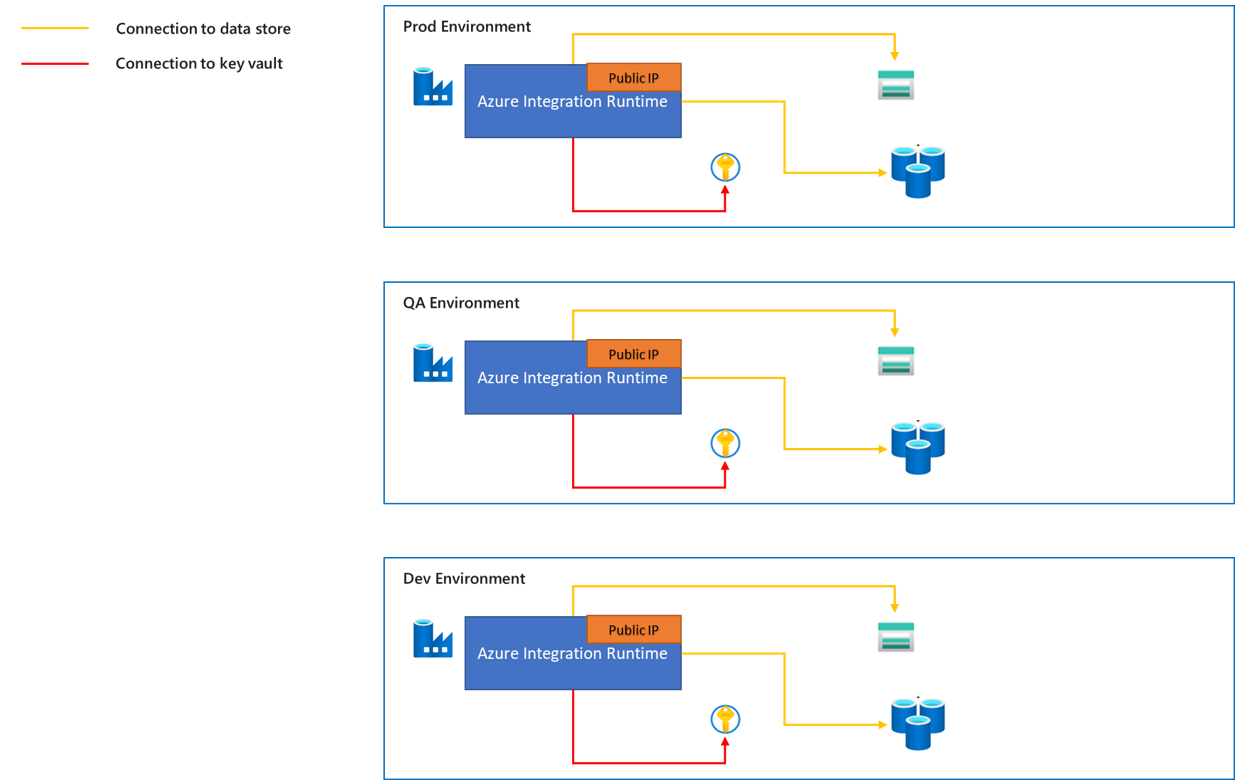
- The traffic from the Azure integration runtime to data stores is through public network.
- We provide a range of static public IP addresses for the Azure integration runtime and these IP addresses can be added to the allowlist of the target data store firewall. To learn more about how to get public IP addresses of the Azure Integration runtime, refer to the article Azure Integration Runtime IP addresses.
- The Azure integration runtime can be autoresolved according to the region of the data source and data sink. Or you can choose a specific region. We recommend you choose the region closest to your data source or sink, which can provide better execution performance. Learn more about performance considerations in the article Troubleshoot copy activity on Azure IR.
Azure integration runtime with managed virtual network
When using the Azure integration runtime with a managed virtual network, you should use managed private endpoints to connect your data sources to ensure data security during transmission. With some extra settings such as Private Link Service and Load Balancer, managed private endpoints can also be used to access on-premises data sources.
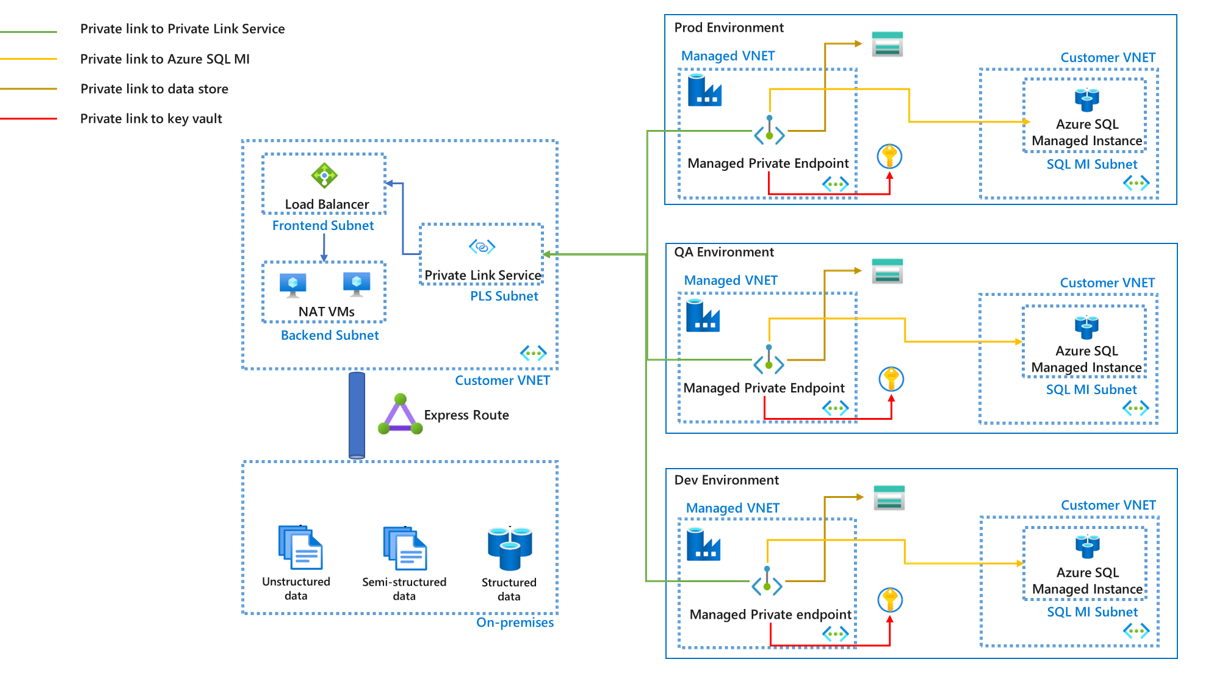
- A managed private endpoint can’t be reused across different environments. You need to create a set of managed private endpoints for each environment. For all data sources supported by managed private endpoints, refer to the article Supported data sources and services.
- You can also use managed private endpoints for connections to external compute resources that you want to orchestrate such as Azure Databricks and Azure Functions. To see the full list of supported external compute resources, refer to the article Supported data sources and services.
- Managed virtual network is managed by the Azure Data Factory service. VNET peering isn't supported between a managed virtual network and a customer virtual network.
- Customers can’t directly change configurations such as the NSG rule on a managed virtual network.
- If any property of a managed private endpoint is different between environments, you can override it by parameterizing that property and providing the respective value during deployment. See details in the article Best practices for CI/CD.
Self-hosted integration runtime
To prevent data from different environments from interfering with each other and ensure the security of the production environment, we need to create a corresponding self-hosted integration runtime for each environment. This ensures sufficient isolation between different environments.
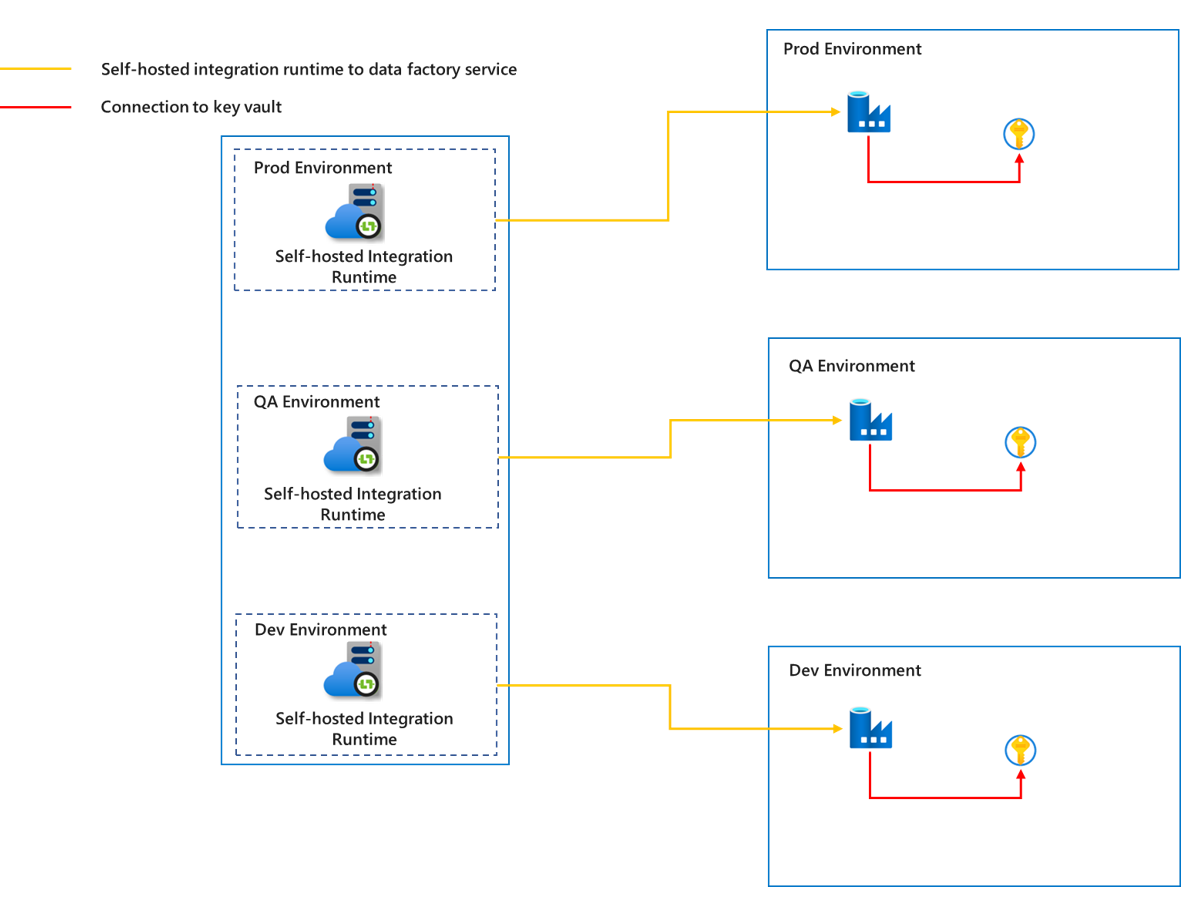
Since the self-hosted integration runtime runs on a customer managed machine, in order to reduce the cost, maintenance, and upgrade efforts as much as possible, we can make use of the shared functions of the self-hosted integration runtime for different projects in the same environment. For details on self-hosted integration runtime sharing, refer to the article Create a shared self-hosted integration runtime in Azure Data Factory. At the same time, to make the data more secure during transmission, we can choose to use a private link to connect the data sources and key vault, and connect the communication between the self-hosted integration runtime and the Azure Data Factory service.
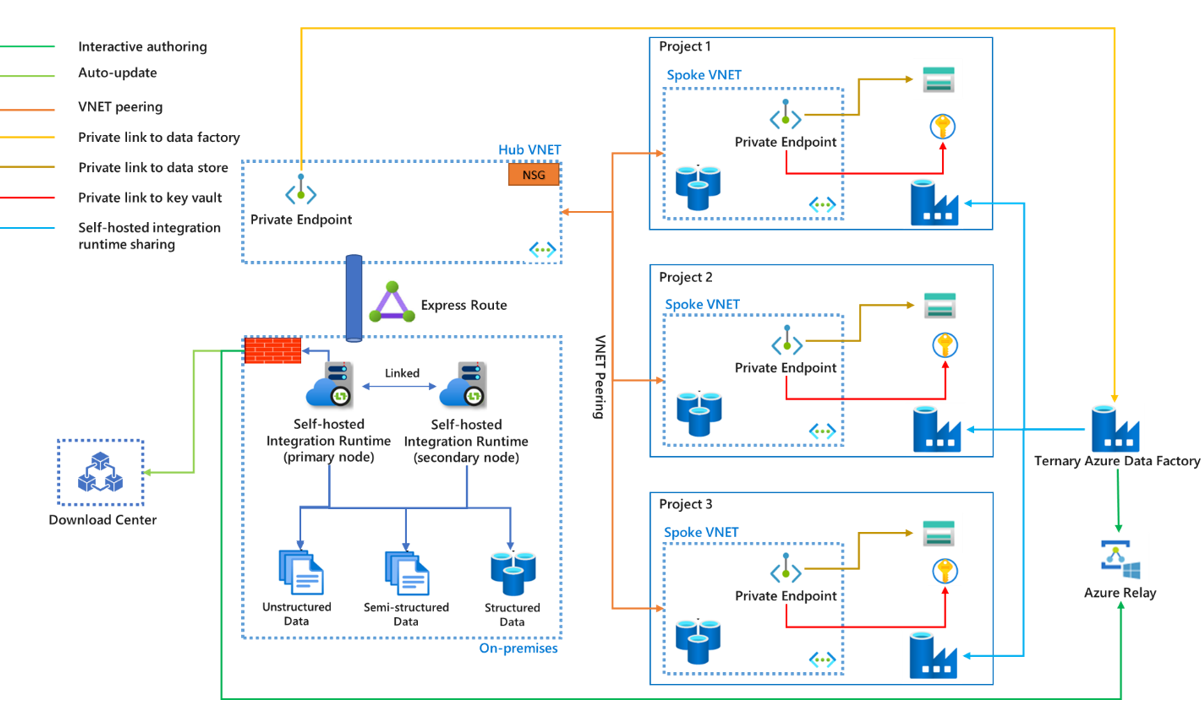
- Express Route isn't mandatory. Without Express Route, the data won't reach the sink through private networks such as a virtual network or a private link, but through the public network.
- If the on-premises network is connected to the Azure virtual network via Express Route or VPN, then the self-hosted integration runtime can be installed on virtual machines in a Hub VNET.
- The hub-spoke virtual network architecture can be used not only for different projects but also for different environments (Prod, QA, and Dev).
- The self-hosted integration runtime can be shared with multiple data factories. The primary data factory references it as a shared self-hosted integration runtime and others refer to it as a linked self-hosted integration runtime. A physical self-hosted integration runtime can have multiple nodes in a cluster. Communication only happens between the primary self-hosted integration runtime and primary node, with work being distributed to secondary nodes from the primary node.
- Credentials of on-premises data stores can be stored either in the local machine or an Azure Key Vault. Azure Key Vault is highly recommended.
- Communication between the self-hosted integration runtime and data factory can go through a private link. But currently, interactive authoring via Azure Relay and automatically updating to the latest version from the download center don’t support private link. The traffic goes through the firewall of on-premises environment. For more information, see the article Azure Private Link for Azure Data Factory.
- The private link is only required for the primary data factory. All traffic goes through primary data factory, then to other data factories.
- The same name of the self-hosted integration runtime across all stages of CI/CD is expected. You can consider using a ternary factory just to contain the shared self-hosted integration runtimes and use linked self-hosted integration runtime in the various production stages. For more information, see the article Continuous integration and delivery.
- You can control how the traffic goes to the download center and Azure Relay using configurations of your on-premises network and Express Route, either through an on-premises proxy or hub virtual network. Make sure the traffic is allowed by proxy or NSG rules.
- If you want to secure communication between self-hosted integration runtime nodes, you can enable remote access from the intranet with a TLS/SSL certificate. For more information, see the article Enable remote access from intranet with TLS/SSL certificate (Advanced).