Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is the next generation of Azure Data Factory, with a simpler architecture, built-in AI, and new features. If you're new to data integration, start with Fabric Data Factory. Existing ADF workloads can upgrade to Fabric to access new capabilities across data science, real-time analytics, and reporting.
Data flows are available in both Azure Data Factory pipelines and Azure Synapse Analytics pipelines. This article applies to mapping data flows. If you're new to transformations, refer to the introductory article Transform data using mapping data flows.
The exists transformation is a row filtering transformation that checks whether your data exists in another source or stream. The output stream includes all rows in the left stream that either exist or don't exist in the right stream. The exists transformation is similar to SQL WHERE EXISTS and SQL WHERE NOT EXISTS.
Configuration
- Choose which data stream you're checking for existence in the Right stream dropdown.
- Specify whether you're looking for the data to exist or not exist in the Exist type setting.
- Select whether or not your want a Custom expression.
- Choose which key columns you want to compare as your exists conditions. By default, data flow looks for equality between one column in each stream. To compare via a computed value, hover over the column dropdown and select Computed column.
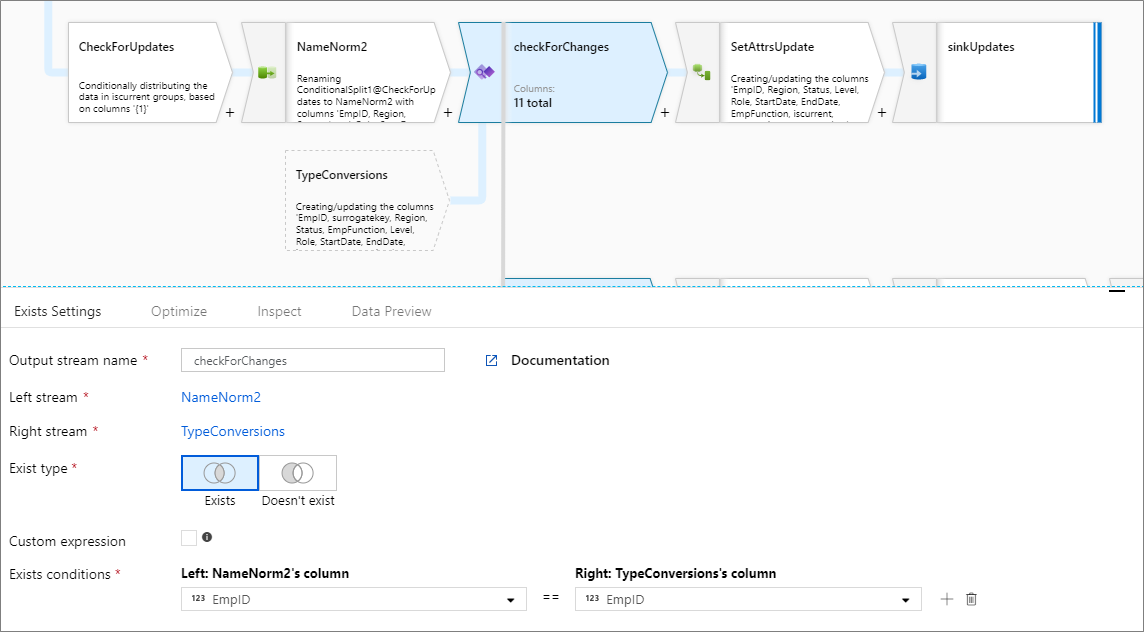
Multiple exists conditions
To compare multiple columns from each stream, add a new exists condition by clicking the plus icon next to an existing row. Each additional condition is joined by an "and" statement. Comparing two columns is the same as the following expression:
source1@column1 == source2@column1 && source1@column2 == source2@column2
Custom expression
To create a free-form expression that contains operators other than "and" and "equals to", select the Custom expression field. Enter a custom expression via the data flow expression builder by clicking on the blue box.
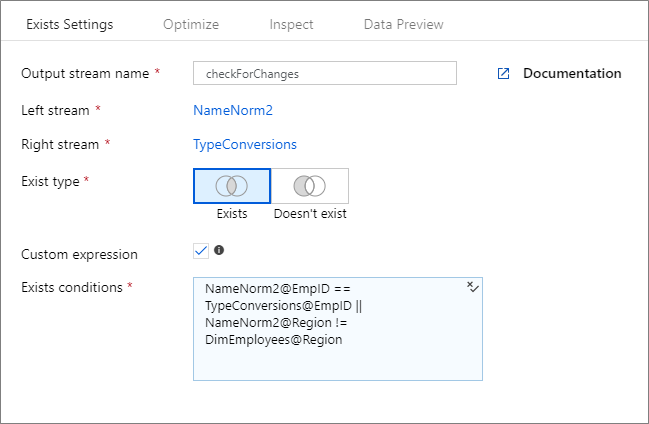
If you are building dynamic patterns in your data flows by using "late binding" of columns via schema drift, you can use the byName() expression function to use the exists transformation without hardcoding (i.e. early binding) the column names. Example: toString(byName('ProductNumber','source1')) == toString(byName('ProductNumber','source2'))
Broadcast optimization
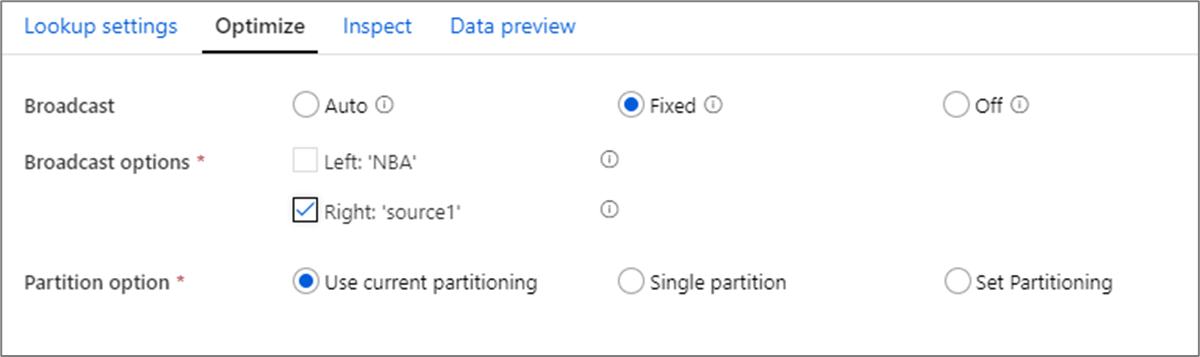
In joins, lookups and exists transformation, if one or both data streams fit into worker node memory, you can optimize performance by enabling Broadcasting. By default, the spark engine will automatically decide whether or not to broadcast one side. To manually choose which side to broadcast, select Fixed.
It's not recommended to disable broadcasting via the Off option unless your joins are running into timeout errors.
Data flow script
Syntax
<leftStream>, <rightStream>
exists(
<conditionalExpression>,
negate: { true | false },
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <existsTransformationName>
Example
The below example is an exists transformation named checkForChanges that takes left stream NameNorm2 and right stream TypeConversions. The exists condition is the expression NameNorm2@EmpID == TypeConversions@EmpID && NameNorm2@Region == DimEmployees@Region that returns true if both the EMPID and Region columns in each stream matches. As we're checking for existence, negate is false. We aren't enabling any broadcasting in the optimize tab so broadcast has value 'none'.
In the UI experience, this transformation looks like the below image:
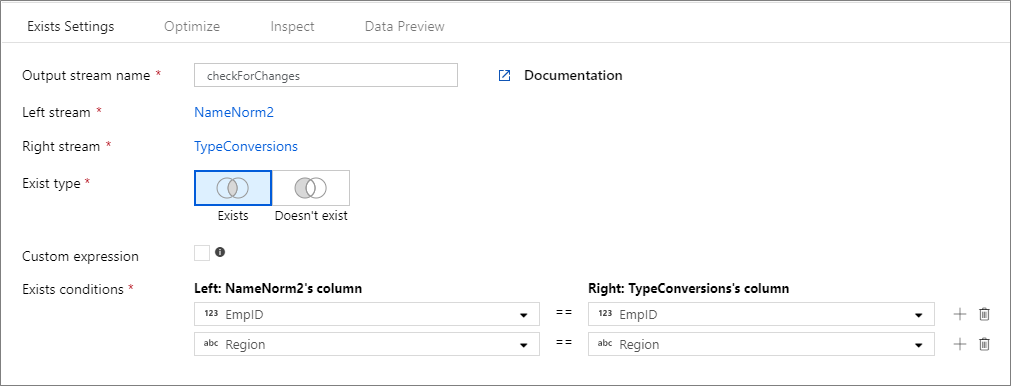
The data flow script for this transformation is in the snippet below:
NameNorm2, TypeConversions
exists(
NameNorm2@EmpID == TypeConversions@EmpID && NameNorm2@Region == DimEmployees@Region,
negate:false,
broadcast: 'auto'
) ~> checkForChanges