Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is the next generation of Azure Data Factory, with a simpler architecture, built-in AI, and new features. If you're new to data integration, start with Fabric Data Factory. Existing ADF workloads can upgrade to Fabric to access new capabilities across data science, real-time analytics, and reporting.
Data flows are available in both Azure Data Factory pipelines and Azure Synapse Analytics pipelines. This article applies to mapping data flows. If you're new to transformations, refer to the introductory article Transform data using mapping data flows.
Tip
For the equivalent transformation (Custom functions) in Dataflow Gen2, see A guide to Dataflow Gen2 for mapping data flow users.
Use the flowlet transformation to run a previously created mapping data flow flowlet. For an overview of flowlets see Flowlets in mapping data flow | Microsoft Docs
Note
The flowlet transformation in Azure Data Factory and Synapse Analytics pipelines is currently in public preview
Configuration
The flowlet transformation contains the following configuration settings
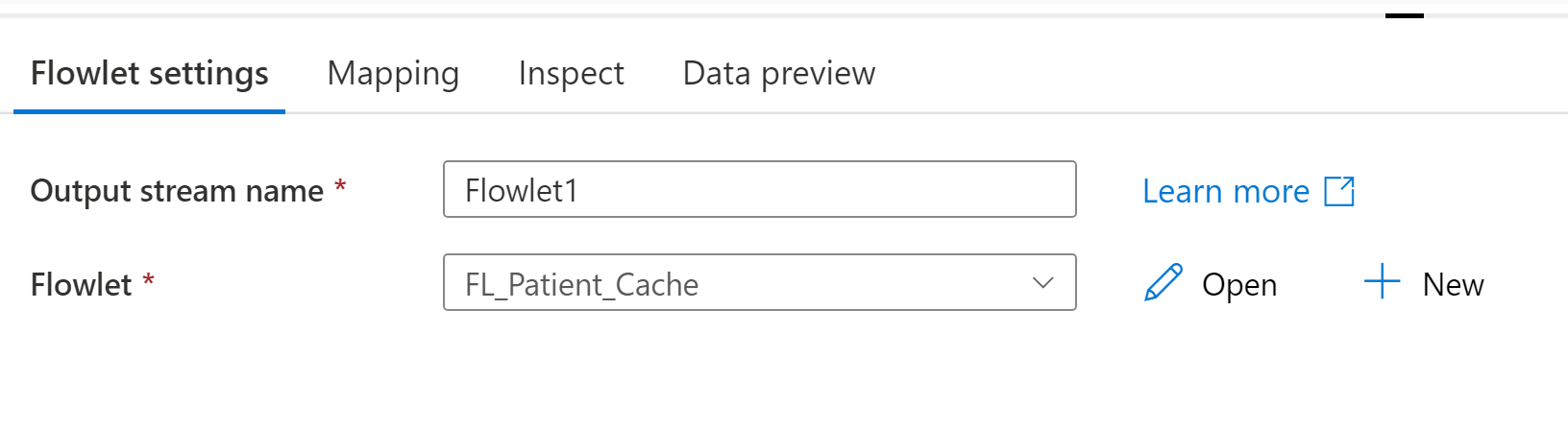
Flowlet
Select the flowlet to run. Once the flowlet is selected you will be able to map input columns, if any, in the mapping tab.
Mapping
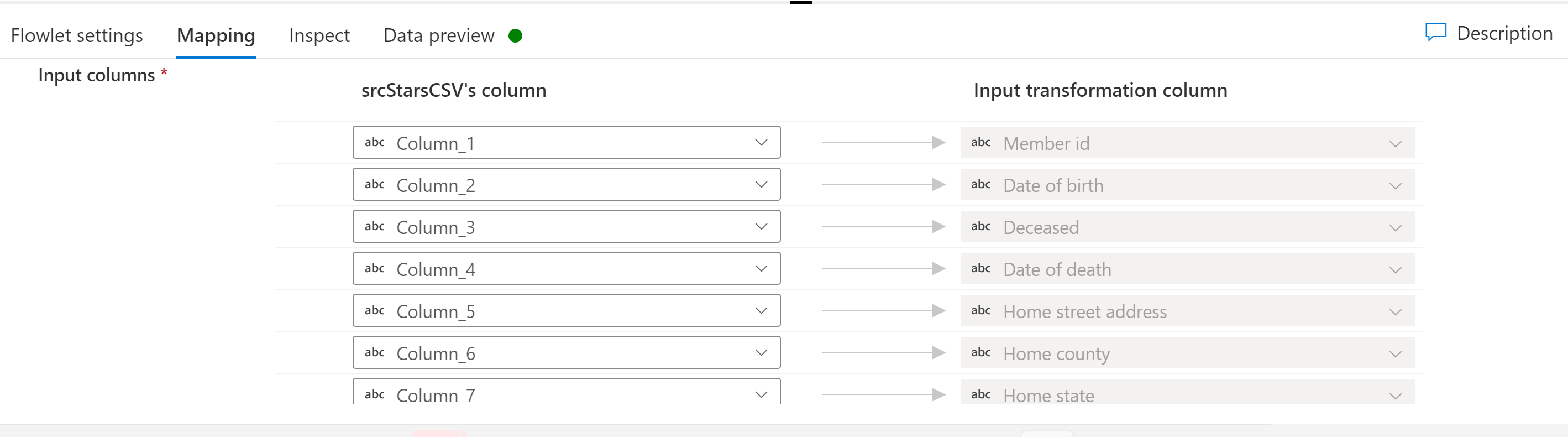
If the selected flowlet has input columns, you can map columns from the input stream to the expected input columns in the flowlet. This mapping of your mapping data flows columns to the flowlet is what enables the flowlets to serve as reusable snippets of mapping data flow logic across potentially many mapping data flows.
Data flow script
Syntax
<incomingStream>
<transformation> ~> <transformationName>
<outputStream>
Example
source1 derive(Test = "test") ~> DerivedColumn1
DerivedColumn1 output() ~> output1