Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is the next generation of Azure Data Factory, with a simpler architecture, built-in AI, and new features. If you're new to data integration, start with Fabric Data Factory. Existing ADF workloads can upgrade to Fabric to access new capabilities across data science, real-time analytics, and reporting.
Data flows are available in both Azure Data Factory pipelines and Azure Synapse Analytics pipelines. This article applies to mapping data flows. If you're new to transformations, refer to the introductory article Transform data using mapping data flows.
Tip
For the equivalent transformation (Unpivot columns) in Dataflow Gen2, see A guide to Dataflow Gen2 for mapping data flow users.
Use Unpivot in a mapping data flow as a way to turn an unnormalized dataset into a more normalized version by expanding values from multiple columns in a single record into multiple records with the same values in a single column.

Ungroup By
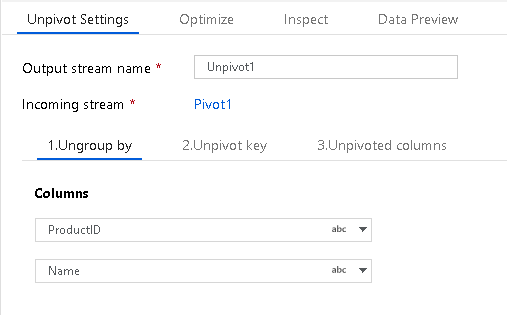
First, set the columns that you wish to ungroup by for your unpivot aggregation. Set one or more columns for ungrouping with the + sign next to the column list.
Unpivot Key
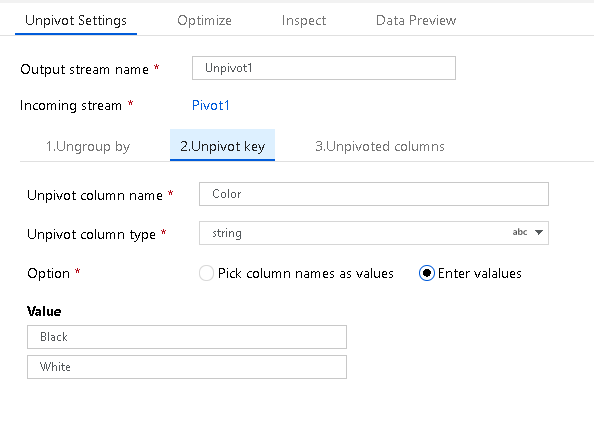
The Unpivot Key is the column that the service will pivot from column to row. By default, each unique value in the dataset for this field will pivot to a row. However, you can optionally enter the values from the dataset that you wish to pivot to row values.
Unpivoted Columns
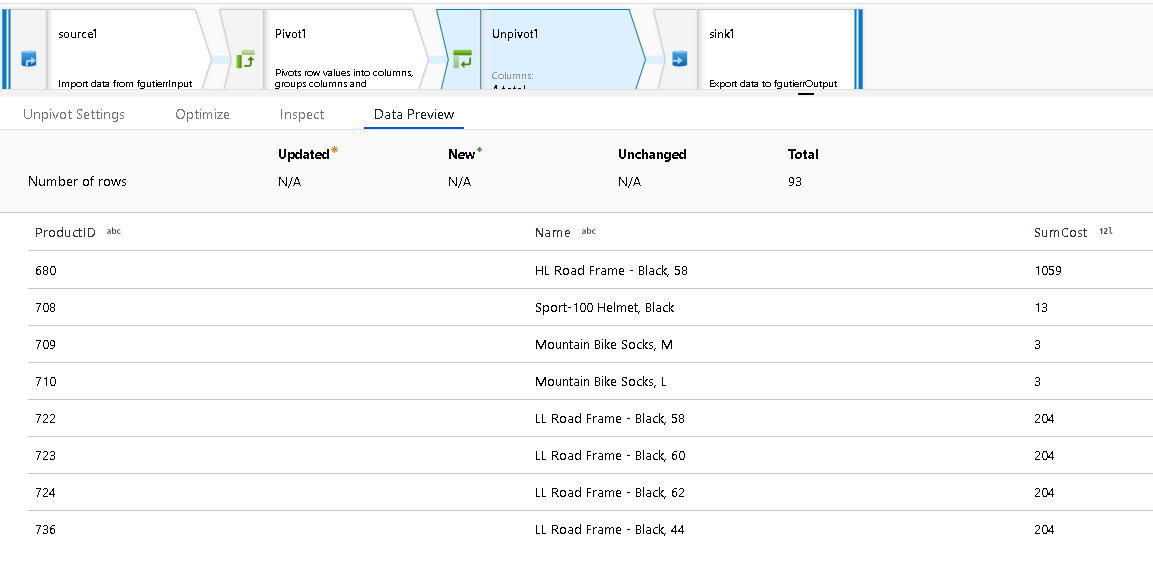
Lastly, choose the column name for storing the values for unpivoted columns that are transformed into rows.
(Optional) You can drop rows with Null values.
For instance, SumCost is the column name that is chosen in the example shared above.

Setting the Column Arrangement to "Normal" will group together all of the new unpivoted columns from a single value. Setting the columns arrangement to "Lateral" will group together new unpivoted columns generated from an existing column.
The final unpivoted data result set shows the column totals now unpivoted into separate row values.
Related content
Use the Pivot transformation to pivot rows to columns.