Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is the next generation of Azure Data Factory, with a simpler architecture, built-in AI, and new features. If you're new to data integration, start with Fabric Data Factory. Existing ADF workloads can upgrade to Fabric to access new capabilities across data science, real-time analytics, and reporting.
Data flows are available in both Azure Data Factory pipelines and Azure Synapse Analytics pipelines. This article applies to mapping data flows. If you're new to transformations, refer to the introductory article Transform data using mapping data flows.
Tip
If you're new to data integration, start with Fabric Data Factory, the next generation of Azure Data Factory. The Window transformation isn't currently supported in Dataflow Gen2. For a list of supported transformations and their equivalents, see A guide to Dataflow Gen2 for mapping data flow users.
The Window transformation is where you define window-based aggregations of columns in your data streams. In the Expression Builder, you can define different types of aggregations that are based on data or time windows (SQL OVER clause) such as LEAD, LAG, NTILE, CUMEDIST, and RANK. A new field is generated in your output that includes these aggregations. You can also include optional group-by fields.
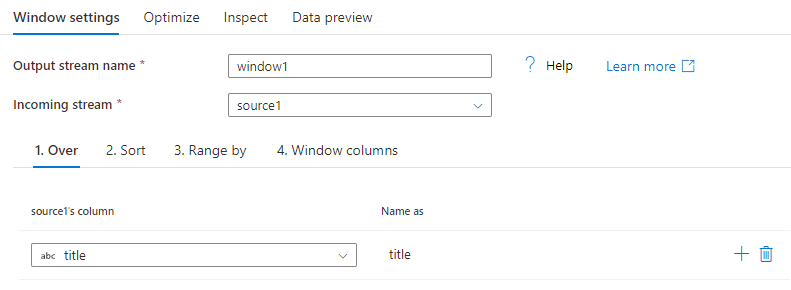
Over
Set the partitioning of column data for your window transformation. The SQL equivalent is the Partition By in the Over clause in SQL. If you wish to create a calculation or create an expression to use for the partitioning, you can do that by hovering over the column name and selecting Computed column.
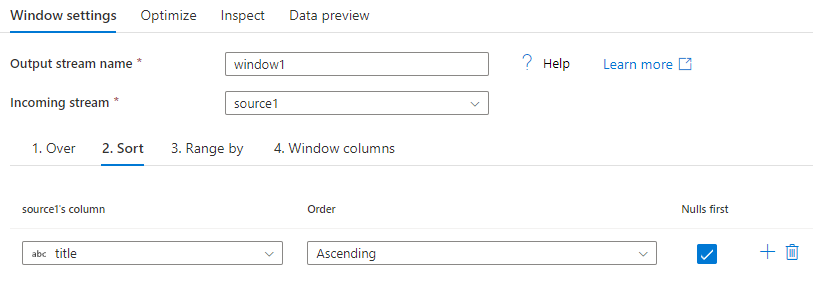
Sort
Another part of the Over clause is setting the Order By. This clause sets the data sort ordering. You can also create an expression for a calculate value in this column field for sorting.
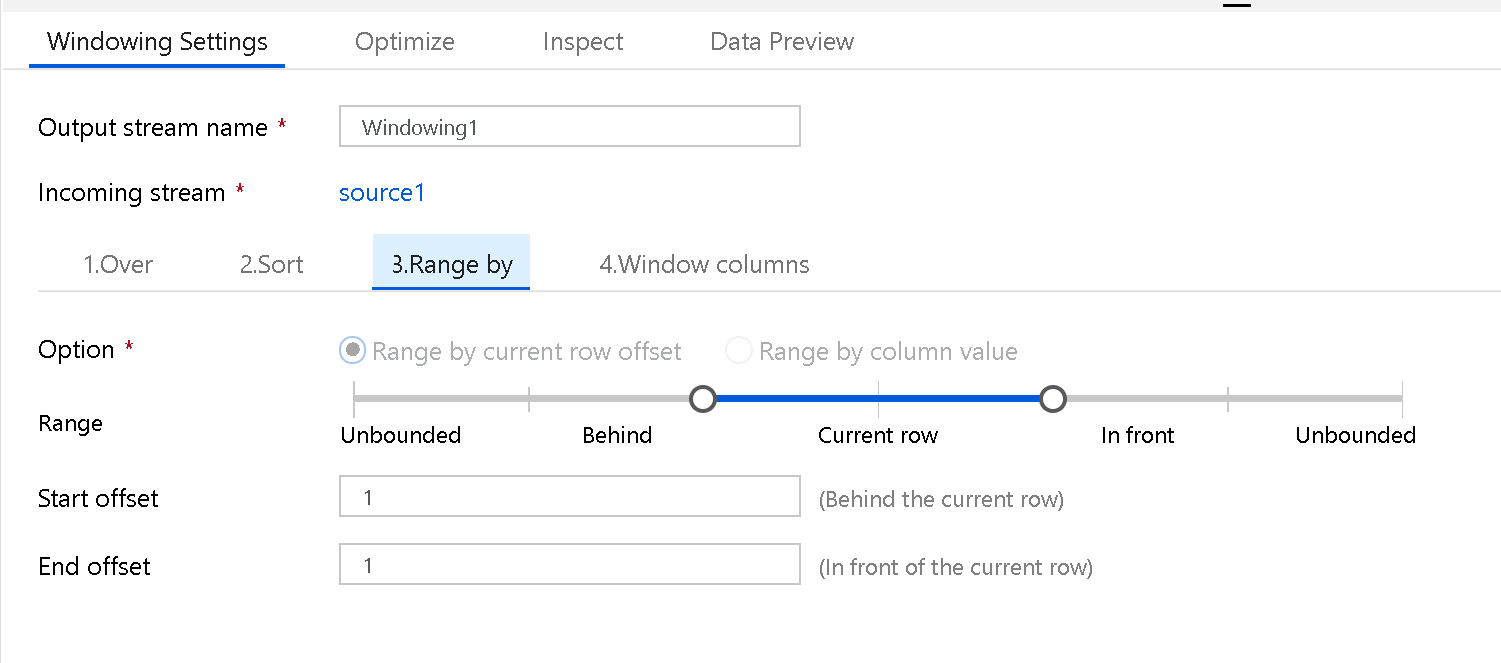
Range By
Next, set the window frame as Unbounded or Bounded. To set an unbounded window frame, set the slider to Unbounded on both ends. If you choose a setting between Unbounded and Current Row, then you must set the Offset start and end values. Both values are positive integers. You can use either relative numbers or values from your data.
The window slider has two values to set: the values before the current row and the values after the current row. The offset between start and end matches the two selectors on the slider.
Window columns
Lastly, use the Expression Builder to define the aggregations you wish to use with the data windows such as RANK, COUNT, MIN, MAX, DENSE RANK, LEAD, LAG, etc.
The full list of aggregation and analytical functions available for you to use in the Data Flow Expression Language via the Expression Builder are listed in Data transformation expressions in mapping data flow.
Related content
If you're looking for a simple group-by aggregation, use the Aggregate transformation