Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
Azure Data Factory provides a performant, robust, and cost-effective mechanism for migrating data at scale from on-premises HDFS to Azure Blob storage or Azure Data Lake Storage Gen2.
Data Factory offers two basic approaches for migrating data from on-premises HDFS to Azure. You can select the approach based on your scenario.
- Data Factory DistCp mode (recommended): In Data Factory, you can use DistCp (distributed copy) to copy files as-is to Azure Blob storage (including staged copy) or Azure Data Lake Store Gen2. Use Data Factory integrated with DistCp to take advantage of an existing powerful cluster to achieve the best copy throughput. You also get the benefit of flexible scheduling and a unified monitoring experience from Data Factory. Depending on your Data Factory configuration, copy activity automatically constructs a DistCp command, submits the data to your Hadoop cluster, and then monitors the copy status. We recommend Data Factory DistCp mode for migrating data from an on-premises Hadoop cluster to Azure.
- Data Factory native integration runtime mode: DistCp isn't an option in all scenarios. For example, in an Azure Virtual Networks environment, the DistCp tool doesn't support Azure ExpressRoute private peering with an Azure Storage virtual network endpoint. In addition, in some cases, you don't want to use your existing Hadoop cluster as an engine for migrating data so you don't put heavy loads on your cluster, which might affect the performance of existing ETL jobs. Instead, you can use the native capability of the Data Factory integration runtime as the engine that copies data from on-premises HDFS to Azure.
This article provides the following information about both approaches:
- Performance
- Copy resilience
- Network security
- High-level solution architecture
- Implementation best practices
Performance
In Data Factory DistCp mode, throughput is the same as if you use the DistCp tool independently. Data Factory DistCp mode maximizes the capacity of your existing Hadoop cluster. You can use DistCp for large inter-cluster or intra-cluster copying.
DistCp uses MapReduce to effect its distribution, error handling and recovery, and reporting. It expands a list of files and directories into input for task mapping. Each task copies a file partition that's specified in the source list. You can use Data Factory integrated with DistCp to build pipelines to fully utilize your network bandwidth, storage IOPS, and bandwidth to maximize data movement throughput for your environment.
Data Factory native integration runtime mode also allows parallelism at different levels. You can use parallelism to fully utilize your network bandwidth, storage IOPS, and bandwidth to maximize data movement throughput:
- A single copy activity can take advantage of scalable compute resources. With a self-hosted integration runtime, you can manually scale up the machine or scale out to multiple machines (up to four nodes). A single copy activity partitions its file set across all nodes.
- A single copy activity reads from and writes to the data store by using multiple threads.
- Data Factory control flow can start multiple copy activities in parallel. For example, you can use a For Each loop.
For more information, see the copy activity performance guide.
Resilience
In Data Factory DistCp mode, you can use different DistCp command-line parameters (For example, -i, ignore failures or -update, write data when source file and destination file differ in size) for different levels of resilience.
In the Data Factory native integration runtime mode, in a single copy activity run, Data Factory has a built-in retry mechanism. It can handle a certain level of transient failures in the data stores or in the underlying network.
When doing binary copying from on-premises HDFS to Blob storage and from on-premises HDFS to Data Lake Store Gen2, Data Factory automatically performs checkpointing to a large extent. If a copy activity run fails or times out, on a subsequent retry (make sure that retry count is > 1), the copy resumes from the last failure point instead of starting at the beginning.
Network security
By default, Data Factory transfers data from on-premises HDFS to Blob storage or Azure Data Lake Storage Gen2 by using an encrypted connection over HTTPS protocol. HTTPS provides data encryption in transit and prevents eavesdropping and man-in-the-middle attacks.
Alternatively, if you don't want data to be transferred over the public internet, for higher security, you can transfer data over a private peering link via ExpressRoute.
Solution architecture
This image depicts migrating data over the public internet:
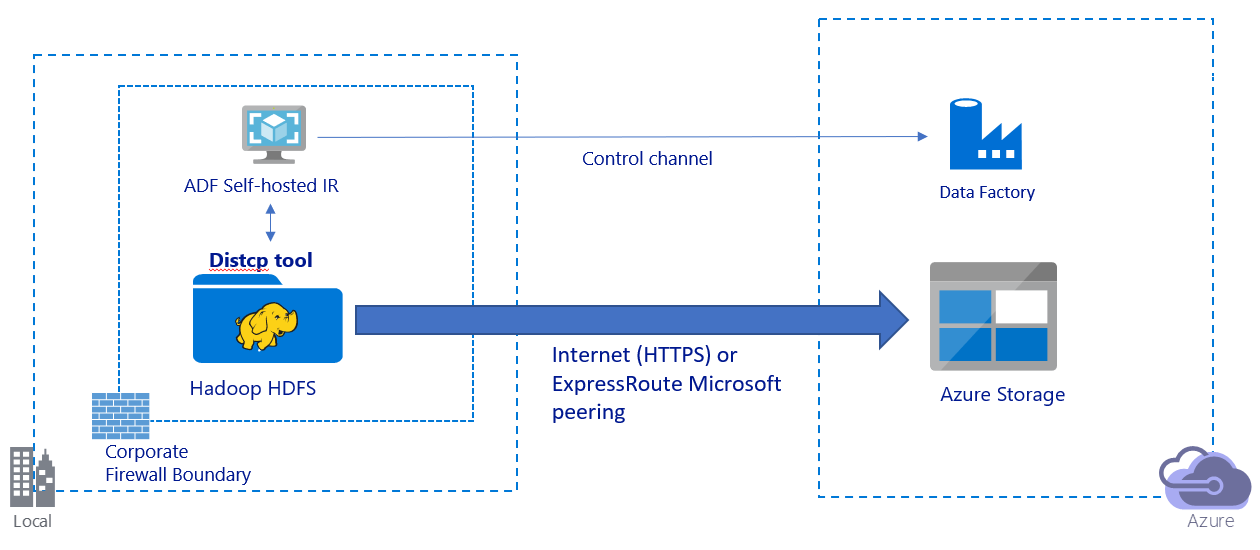
- In this architecture, data is transferred securely by using HTTPS over the public internet.
- We recommend using Data Factory DistCp mode in a public network environment. You can take advantage of a powerful existing cluster to achieve the best copy throughput. You also get the benefit of flexible scheduling and unified monitoring experience from Data Factory.
- For this architecture, you must install the Data Factory self-hosted integration runtime on a Windows machine behind a corporate firewall to submit the DistCp command to your Hadoop cluster and to monitor the copy status. Because the machine isn't the engine that will move data (for control purpose only), the capacity of the machine doesn't affect the throughput of data movement.
- Existing parameters from the DistCp command are supported.
This image depicts migrating data over a private link:
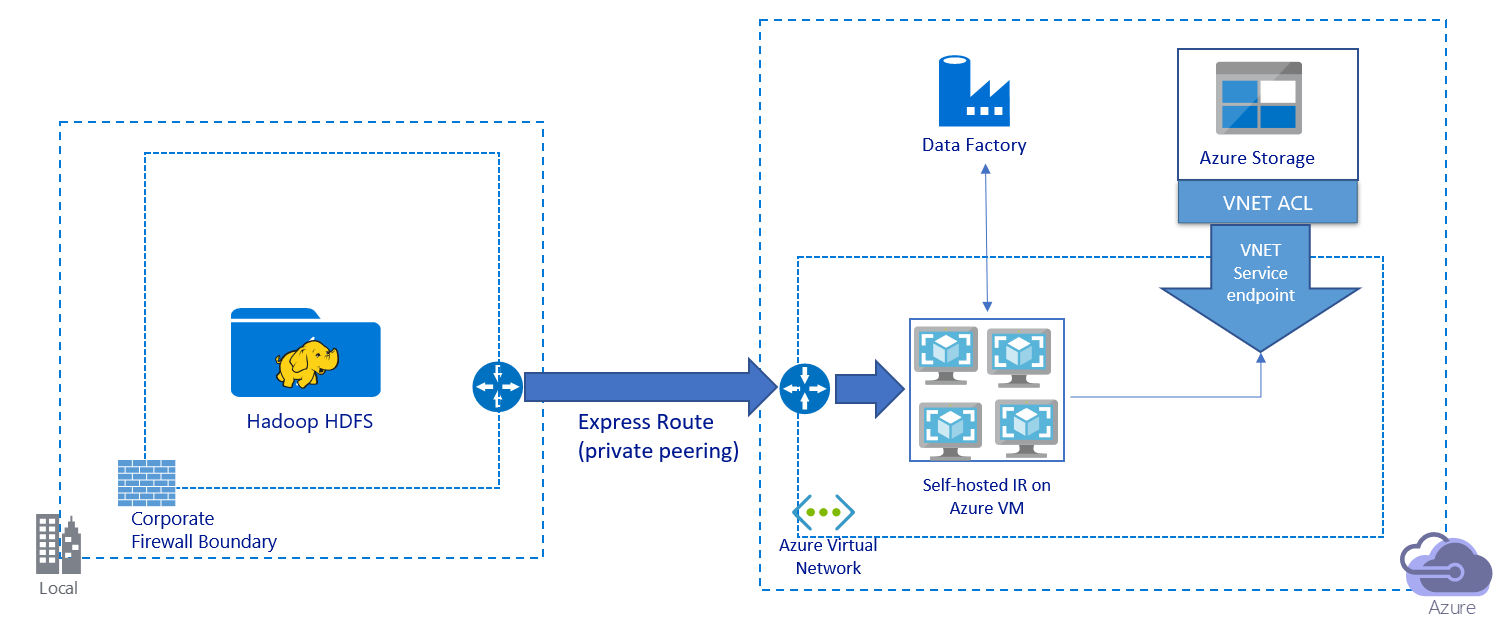
- In this architecture, data is migrated over a private peering link via Azure ExpressRoute. Data never traverses over the public internet.
- The DistCp tool doesn't support ExpressRoute private peering with an Azure Storage virtual network endpoint. We recommend that you use Data Factory's native capability via the integration runtime to migrate the data.
- For this architecture, you must install the Data Factory self-hosted integration runtime on a Windows VM in your Azure virtual network. You can manually scale up your VM or scale out to multiple VMs to fully utilize your network and storage IOPS or bandwidth.
- The recommended configuration to start with for each Azure VM (with the Data Factory self-hosted integration runtime installed) is Standard_D32s_v3 with a 32 vCPU and 128 GB of memory. You can monitor the CPU and memory usage of the VM during data migration to see whether you need to scale up the VM for better performance or to scale down the VM to reduce cost.
- You can also scale out by associating up to four VM nodes with a single self-hosted integration runtime. A single copy job running against a self-hosted integration runtime automatically partitions the file set and makes use of all VM nodes to copy the files in parallel. For high availability, we recommend that you start with two VM nodes to avoid a single-point-of-failure scenario during data migration.
- When you use this architecture, initial snapshot data migration and delta data migration are available to you.
Implementation best practices
We recommend that you follow these best practices when you implement your data migration.
Authentication and credential management
- To authenticate to HDFS, you can use either Windows (Kerberos) or Anonymous.
- Multiple authentication types are supported for connecting to Azure Blob storage. We highly recommend using managed identities for Azure resources. Built on top of an automatically managed Data Factory identity in Microsoft Entra ID, managed identities allow you to configure pipelines without supplying credentials in the linked service definition. Alternatively, you can authenticate to Blob storage by using a service principal, a shared access signature, or a storage account key.
- Multiple authentication types also are supported for connecting to Data Lake Storage Gen2. We highly recommend using managed identities for Azure resources, but you also can use a service principal or a storage account key.
- When you're not using managed identities for Azure resources, we highly recommend storing the credentials in Azure Key Vault to make it easier to centrally manage and rotate keys without modifying Data Factory linked services. This is also a best practice for CI/CD.
Initial snapshot data migration
In Data Factory DistCp mode, you can create one copy activity to submit the DistCp command and use different parameters to control initial data migration behavior.
In Data Factory native integration runtime mode, we recommend data partition, especially when you migrate more than 10 TB of data. To partition the data, use the folder names on HDFS. Then, each Data Factory copy job can copy one folder partition at a time. You can run multiple Data Factory copy jobs concurrently for better throughput.
If any of the copy jobs fail due to network or data store transient issues, you can rerun the failed copy job to reload that specific partition from HDFS. Other copy jobs that are loading other partitions aren't affected.
Delta data migration
In Data Factory DistCp mode, you can use the DistCp command-line parameter -update, write data when source file and destination file differ in size, for delta data migration.
In Data Factory native integration mode, the most performant way to identify new or changed files from HDFS is by using a time-partitioned naming convention. When your data in HDFS has been time-partitioned with time slice information in the file or folder name (for example, /yyyy/mm/dd/file.csv), your pipeline can easily identify which files and folders to copy incrementally.
Alternatively, if your data in HDFS isn't time-partitioned, Data Factory can identify new or changed files by using their LastModifiedDate value. Data Factory scans all the files from HDFS and copies only new and updated files that have a last modified timestamp that's greater than a set value.
If you have a large number of files in HDFS, the initial file scanning might take a long time, regardless of how many files match the filter condition. In this scenario, we recommend that you first partition the data by using the same partition you used for the initial snapshot migration. Then, file scanning can occur in parallel.
Estimate price
Consider the following pipeline for migrating data from HDFS to Azure Blob storage:
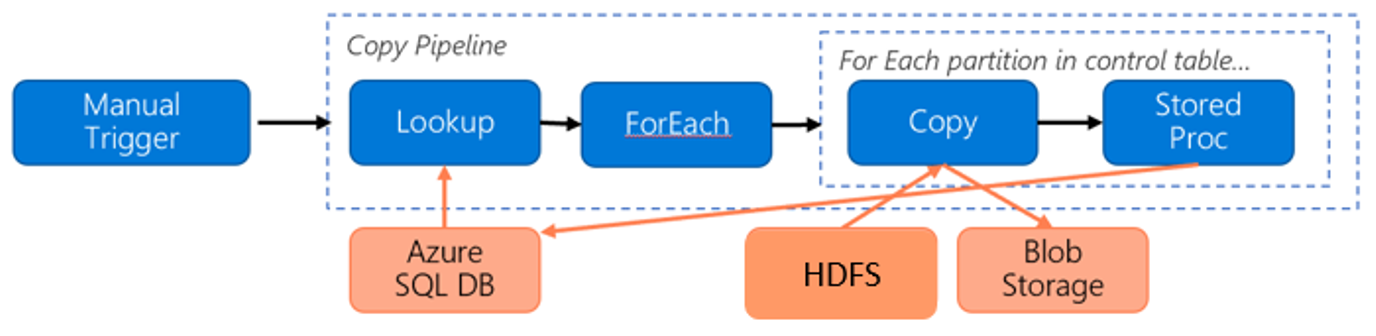
Let's assume the following information:
- Total data volume is 1 PB.
- You migrate data by using the Data Factory native integration runtime mode.
- 1 PB is divided into 1,000 partitions and each copy moves one partition.
- Each copy activity is configured with one self-hosted integration runtime that's associated with four machines and which achieves 500-MBps throughput.
- ForEach concurrency is set to 4 and aggregate throughput is 2 GBps.
- In total, it takes 146 hours to complete the migration.
Here's the estimated price based on our assumptions:

Note
This is a hypothetical pricing example. Your actual pricing depends on the actual throughput in your environment. The price for an Azure Windows VM (with self-hosted integration runtime installed) isn't included.
Additional references
- HDFS connector
- Azure Blob storage connector
- Azure Data Lake Storage Gen2 connector
- Copy activity performance tuning guide
- Create and configure a self-hosted integration runtime
- Self-hosted integration runtime high availability and scalability
- Data movement security considerations
- Store credentials in Azure Key Vault
- Copy a file incrementally based on a time-partitioned file name
- Copy new and changed files based on LastModifiedDate
- Data Factory pricing page