Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is the next generation of Azure Data Factory, with a simpler architecture, built-in AI, and new features. If you're new to data integration, start with Fabric Data Factory. Existing ADF workloads can upgrade to Fabric to access new capabilities across data science, real-time analytics, and reporting.
A common scenario in Data Factory when using mapping data flows, is to write your transformed data to a database in Azure SQL Database. In this scenario, a common error condition that you must prevent against is possible column truncation.
There are two primary methods to graceful handle errors when writing data to your database sink in ADF data flows:
- Set the sink error row handling to "Continue on Error" when processing database data. This is an automated catch-all method that doesn't require custom logic in your data flow.
- Alternatively, use the following steps to provide logging of columns that don't fit into a target string column, allowing your data flow to continue.
Note
When enabling automatic error row handling, as opposed to the following method of writing your own error handling logic, there will be a small performance penalty incurred by and additional step taken by the data factory to perform a 2-phase operation to trap errors.
Scenario
We have a target database table that has an
nvarchar(5)column called "name".Inside of our data flow, we want to map movie titles from our sink to that target "name" column.
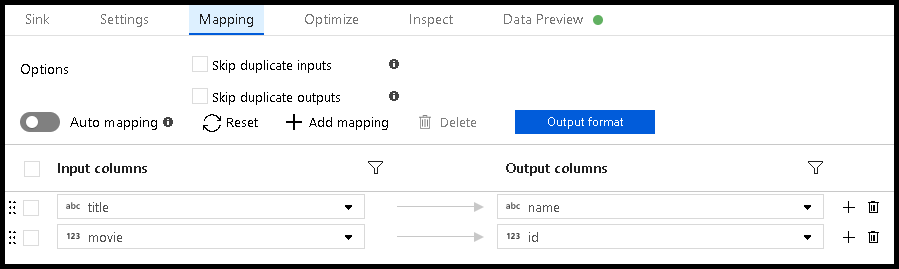
The problem is that the movie title doesn't all fit within a sink column that can only hold five characters. When you execute this data flow, you receive an error like this one:
"Job failed due to reason: DF-SYS-01 at Sink 'WriteToDatabase': java.sql.BatchUpdateException: String or binary data would be truncated. java.sql.BatchUpdateException: String or binary data would be truncated."
This video walks through an example of setting-up error row handling logic in your data flow:
How to design around this condition
In this scenario, the maximum length of the "name" column is five characters. So, let's add a conditional split transformation that allows us to log rows with "titles" that are longer than five characters while also allowing the rest of the rows that can fit into that space to write to the database.
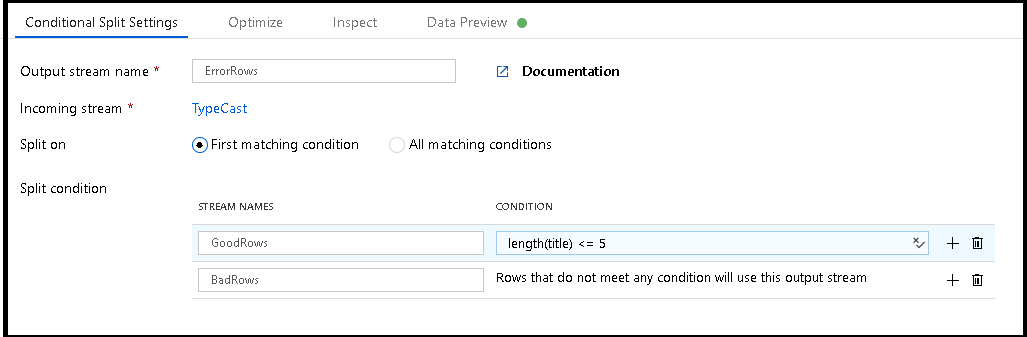
This conditional split transformation defines the maximum length of "title" to be five. Any row that is less than or equal to five goes into the
GoodRowsstream. Any row that is larger than five goes into theBadRowsstream.Now we need to log the rows that failed. Add a sink transformation to the
BadRowsstream for logging. Here, we "automap" all of the fields so that we have logging of the complete transaction record. This is a text-delimited CSV file output to a single file in Blob Storage. We call the log file "badrows.csv".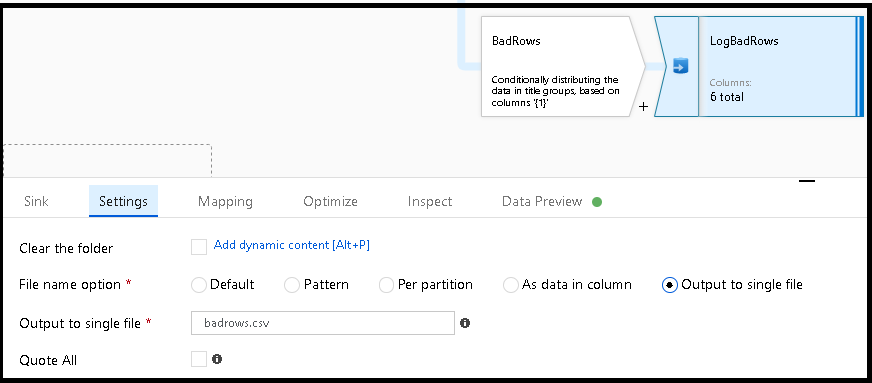
The completed data flow is shown here. We're now able to split off error rows to avoid the SQL truncation errors and put those entries into a log file. Meanwhile, successful rows can continue to write to our target database.
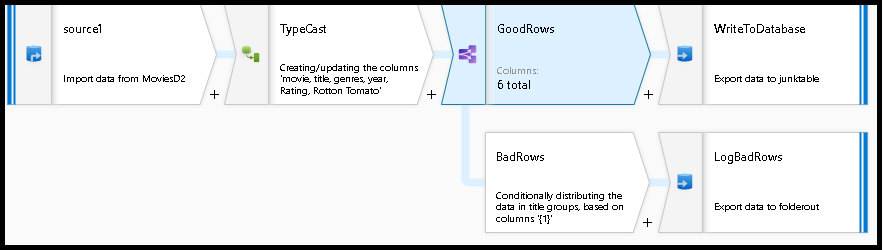
If you choose the error row handling option in the sink transformation and set "Output error rows", Azure Data Factory automatically generates a CSV file output of your row data along with the driver-reported error messages. You don't need to add that logic manually to your data flow with that alternative option. You incur a small performance penalty with this option so that ADF can implement a 2-phase methodology to trap errors and log them.

Related content
- Build the rest of your data flow logic by using mapping data flows transformations.