Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is the next generation of Azure Data Factory, with a simpler architecture, built-in AI, and new features. If you're new to data integration, start with Fabric Data Factory. Existing ADF workloads can upgrade to Fabric to access new capabilities across data science, real-time analytics, and reporting.
This article describes a solution template that you can use to extract data from a PDF source using Azure Data Factory and Azure Document Intelligence in Foundry Tools.
About this solution template
This template analyzes data from a PDF URL source using two Document Intelligence calls. Then, it transforms the output to readable tables in a dataflow and outputs the data to a storage sink.
This template contains two activities:
- Web Activity to call Document Intelligence's prebuilt read model API
- Data flow to transform extracted data from PDF
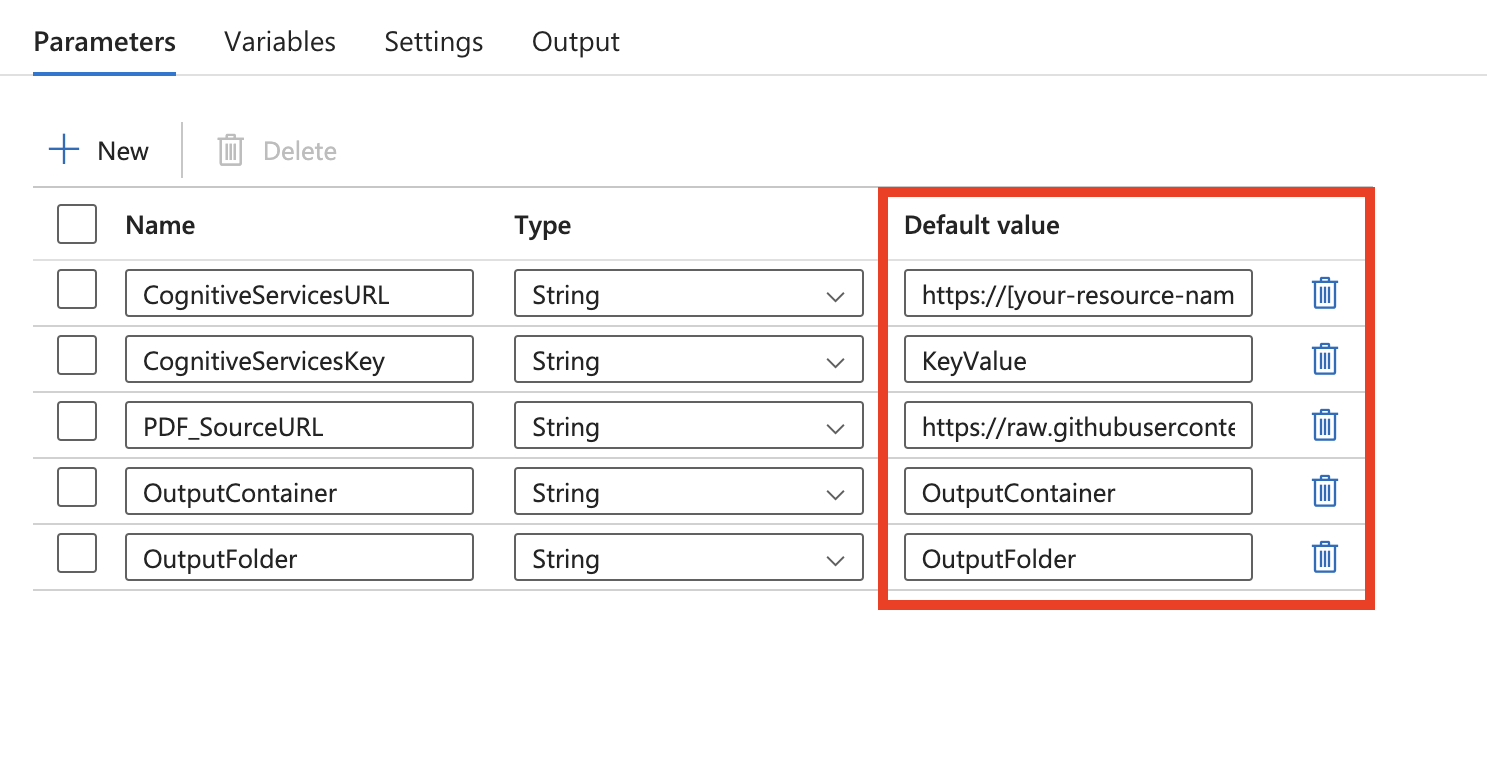
This template defines five parameters:
- CognitiveServicesURL is the Document Intelligence URL ("https://{endpoint}/formrecognizer/v2.1/layout/analyze"). Replace {endpoint} with the endpoint that you obtained with your Document Intelligence subscription. You need to replace the default value with your own URL.
- CognitiveServicesKey is the Document Intelligence subscription key. You need to replace the default value with your own subscription key.
- PDF_SourceURL is the URL of your PDF source. You need to replace the default value with your own URL.
- OutputContainer is the name of the container path where you want your files to be in your destination store. You need to replace the default value with your own container.
- OutputFolder is the name of the folder path where you want your files to be in your destination store. You need to replace the default value with your own folder path.
Prerequisites
- Document Intelligence Resource Endpoint URL and Key (create a new resource here)
How to use this solution template
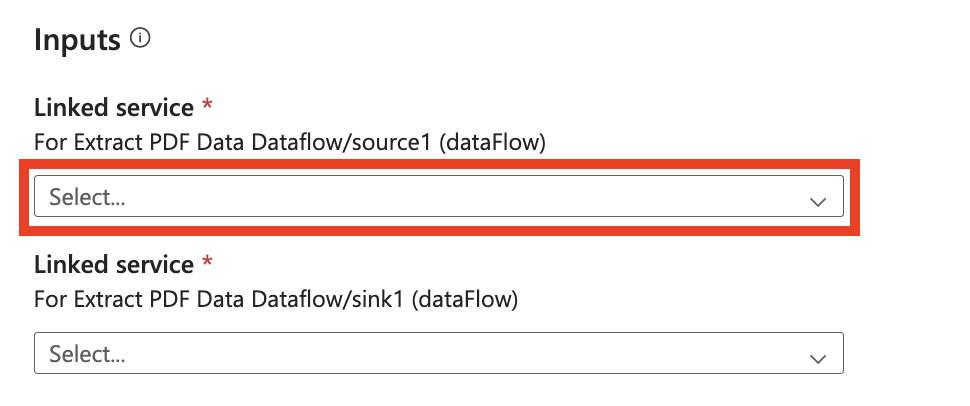
Go to template Extract data from PDF. Create a New connection to your Document Intelligence resource or choose an existing connection.
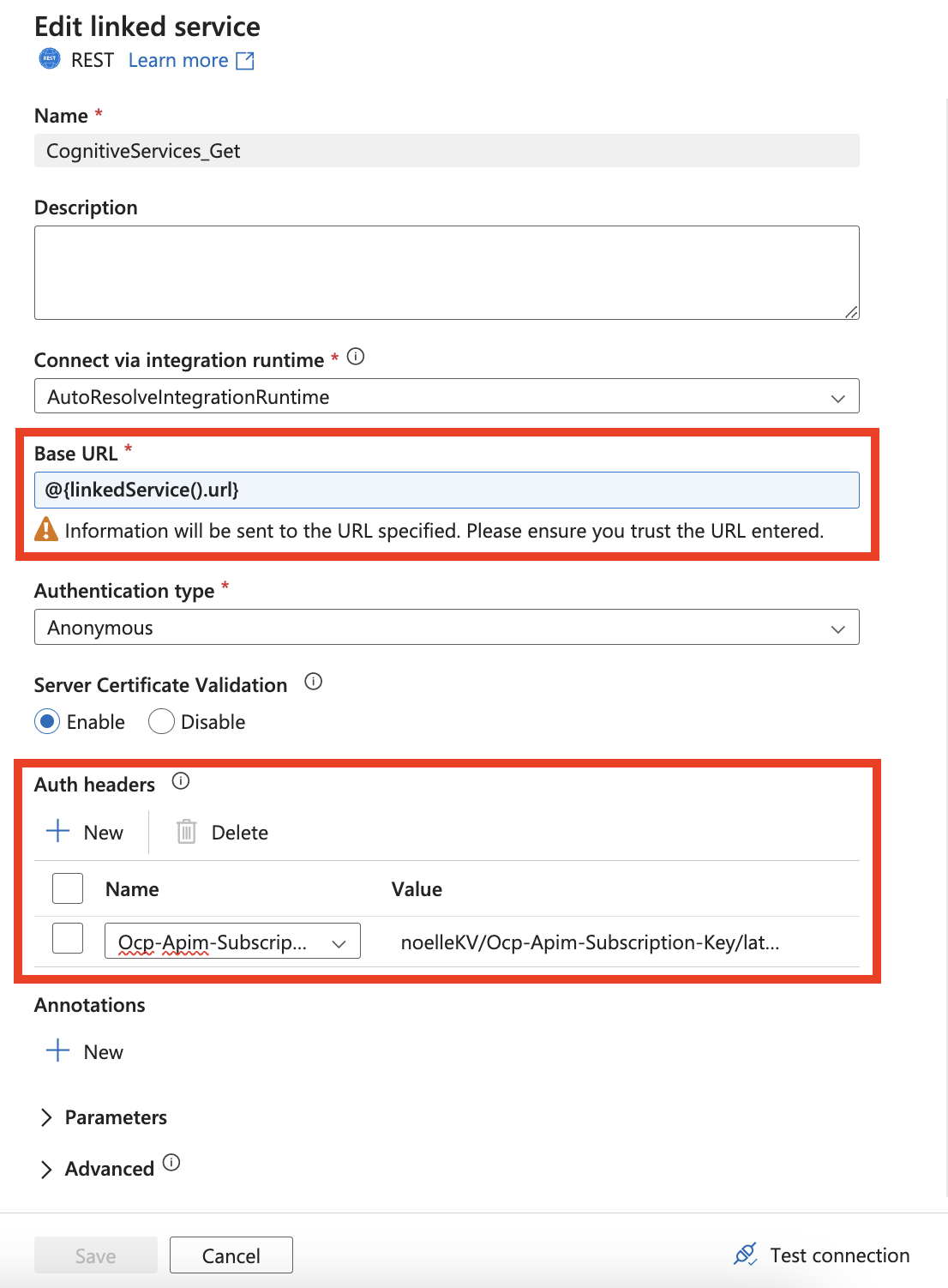
In your connection to Document Intelligence, make sure to add a Linked service Parameter. You'll need to use this url parameter as your dynamic Base URL. You will also need to add a new Auth header under Auth headers. The name should be Ocp-Apim-Subscription-Key and the value should be the key value you find from your Azure Resource.
Create a New connection to your destination storage store or choose an existing connection. The chosen destination is where the extracted PDF data is stored.

Select Use this template.

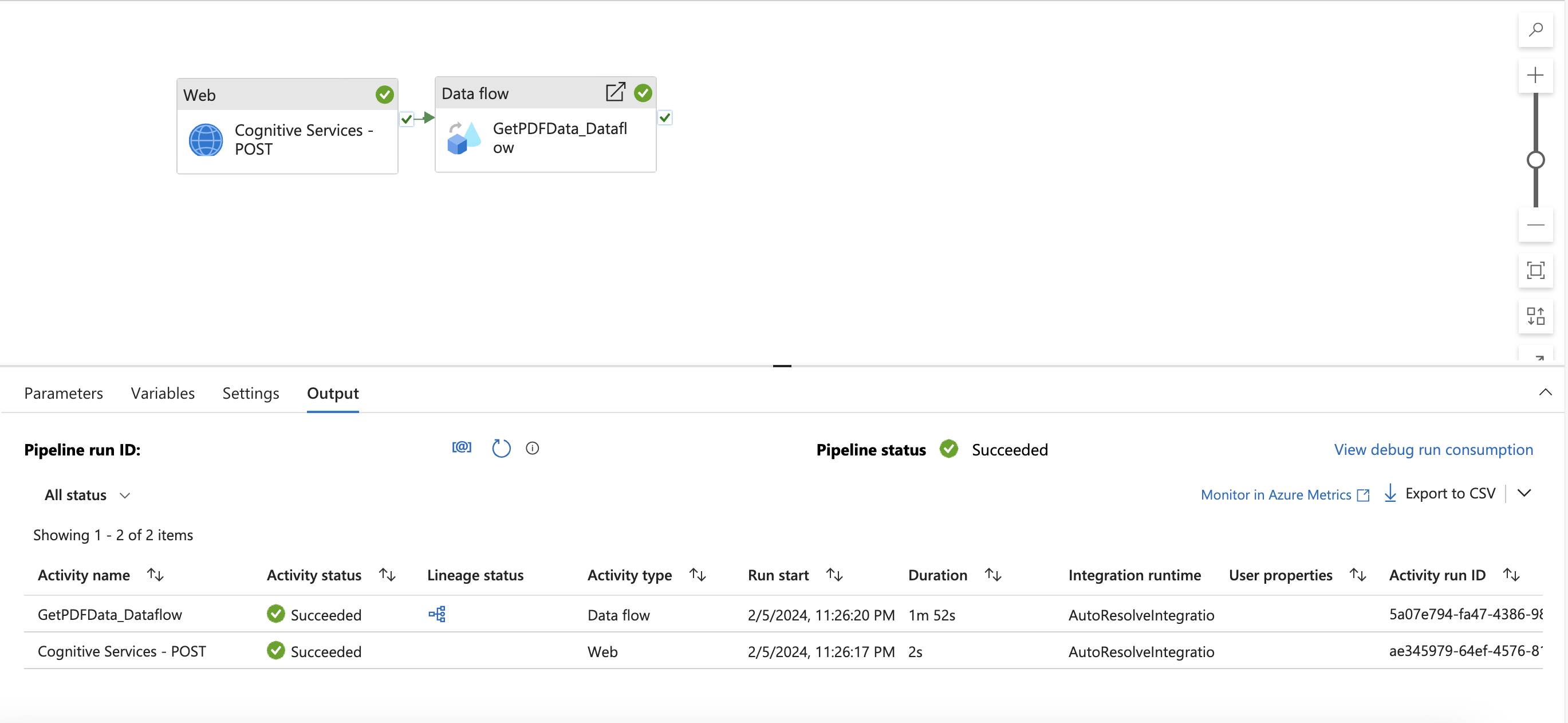
You should see the following pipeline.
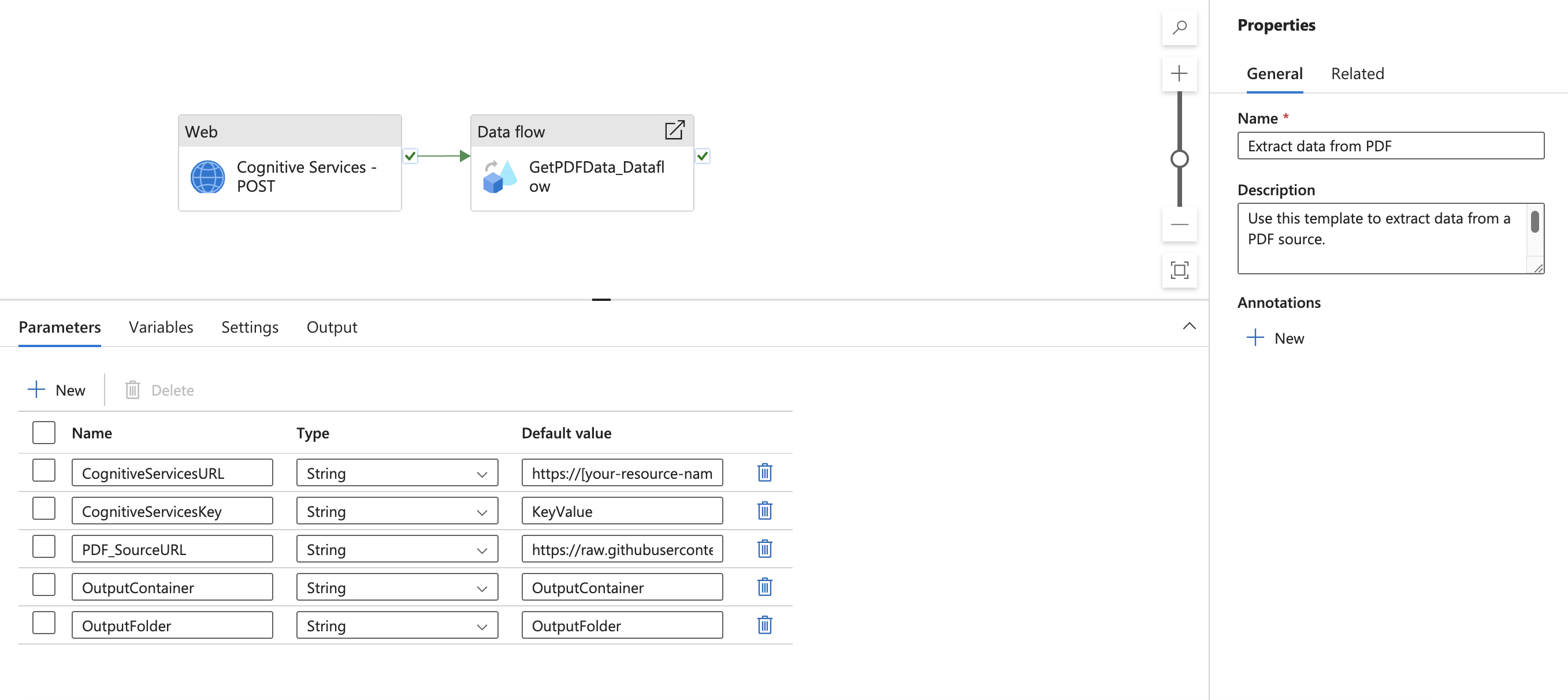
Navigate to the Data flow activity and find Settings. Here you need to add dynamic content for your linked service url parameter. After clicking Add dynamic content, the Pipeline expression builder will open. Select Cognitive Services - POST activity output. Then, type or copy and paste ".output.ADFWebActivityResponseHeaders['Operation-Location']." You should see the following expression in your expression builder.
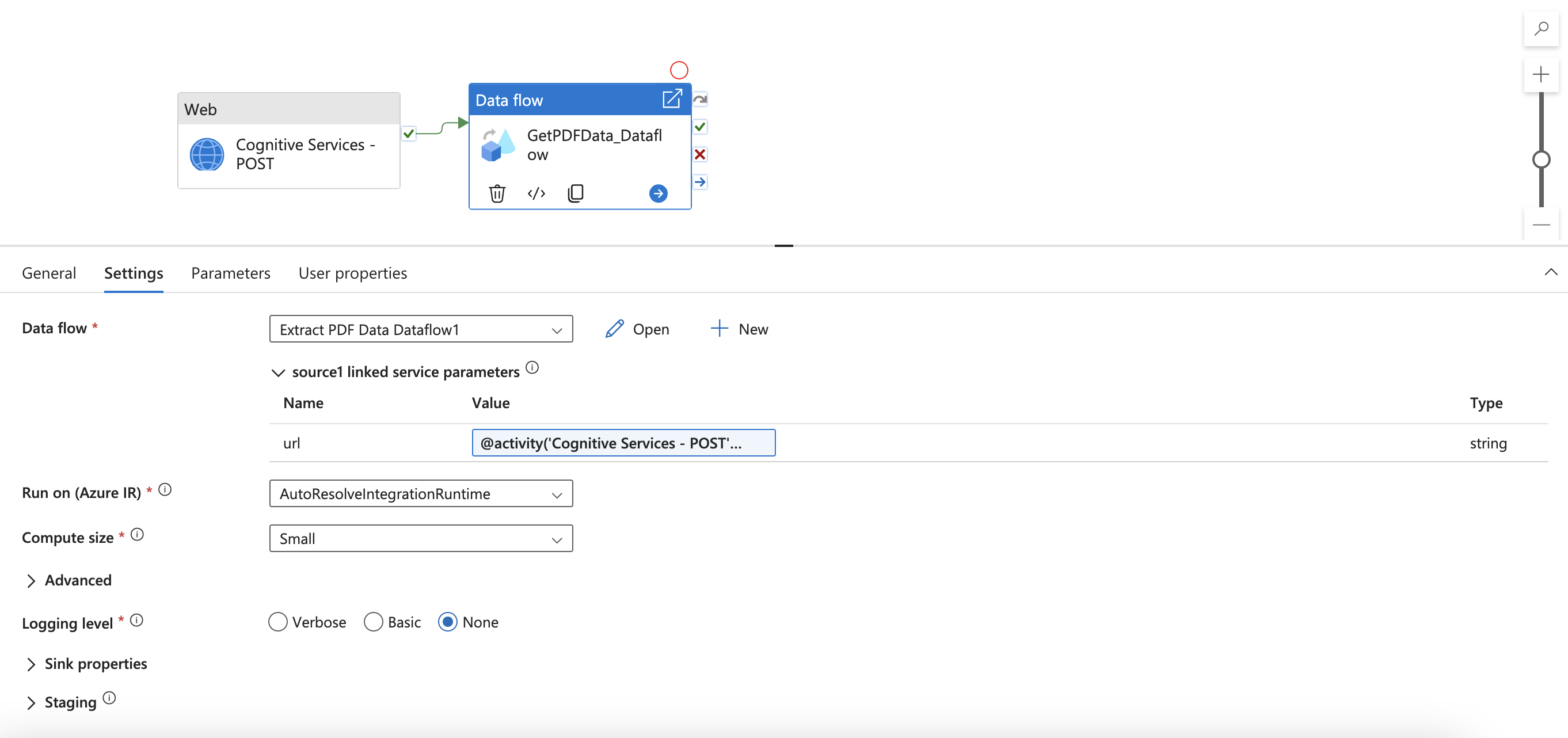
Click OK to return back to the pipeline.
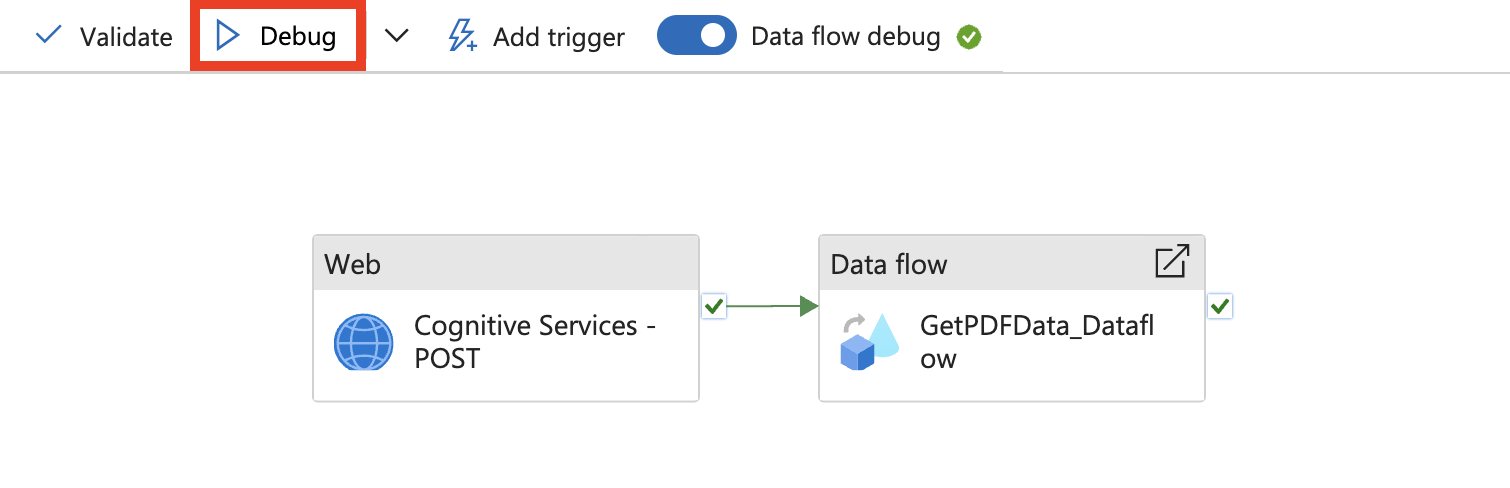
Next, select Debug.
Enter parameter values, review results, and publish.