Transform data in the cloud by using a Spark activity in Azure Data Factory
APPLIES TO:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
In this tutorial, you use the Azure portal to create an Azure Data Factory pipeline. This pipeline transforms data by using a Spark activity and an on-demand Azure HDInsight linked service.
You perform the following steps in this tutorial:
- Create a data factory.
- Create a pipeline that uses a Spark activity.
- Trigger a pipeline run.
- Monitor the pipeline run.
If you don't have an Azure subscription, create a free account before you begin.
Prerequisites
Note
We recommend that you use the Azure Az PowerShell module to interact with Azure. To get started, see Install Azure PowerShell. To learn how to migrate to the Az PowerShell module, see Migrate Azure PowerShell from AzureRM to Az.
- Azure storage account. You create a Python script and an input file, and you upload them to Azure Storage. The output from the Spark program is stored in this storage account. The on-demand Spark cluster uses the same storage account as its primary storage.
Note
HdInsight supports only general-purpose storage accounts with standard tier. Make sure that the account is not a premium or blob only storage account.
- Azure PowerShell. Follow the instructions in How to install and configure Azure PowerShell.
Upload the Python script to your Blob storage account
Create a Python file named WordCount_Spark.py with the following content:
import sys from operator import add from pyspark.sql import SparkSession def main(): spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/inputfiles/minecraftstory.txt").rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) counts.saveAsTextFile("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/outputfiles/wordcount") spark.stop() if __name__ == "__main__": main()Replace <storageAccountName> with the name of your Azure storage account. Then, save the file.
In Azure Blob storage, create a container named adftutorial if it does not exist.
Create a folder named spark.
Create a subfolder named script under the spark folder.
Upload the WordCount_Spark.py file to the script subfolder.
Upload the input file
- Create a file named minecraftstory.txt with some text. The Spark program counts the number of words in this text.
- Create a subfolder named inputfiles in the spark folder.
- Upload the minecraftstory.txt file to the inputfiles subfolder.
Create a data factory
Follow the steps in the article Quickstart: Create a data factory by using the Azure portal to create a data factory if you don't already have one to work with.
Create linked services
You author two linked services in this section:
- An Azure Storage linked service that links an Azure storage account to the data factory. This storage is used by the on-demand HDInsight cluster. It also contains the Spark script to be run.
- An on-demand HDInsight linked service. Azure Data Factory automatically creates an HDInsight cluster and runs the Spark program. It then deletes the HDInsight cluster after the cluster is idle for a preconfigured time.
Create an Azure Storage linked service
On the home page, switch to the Manage tab in the left panel.
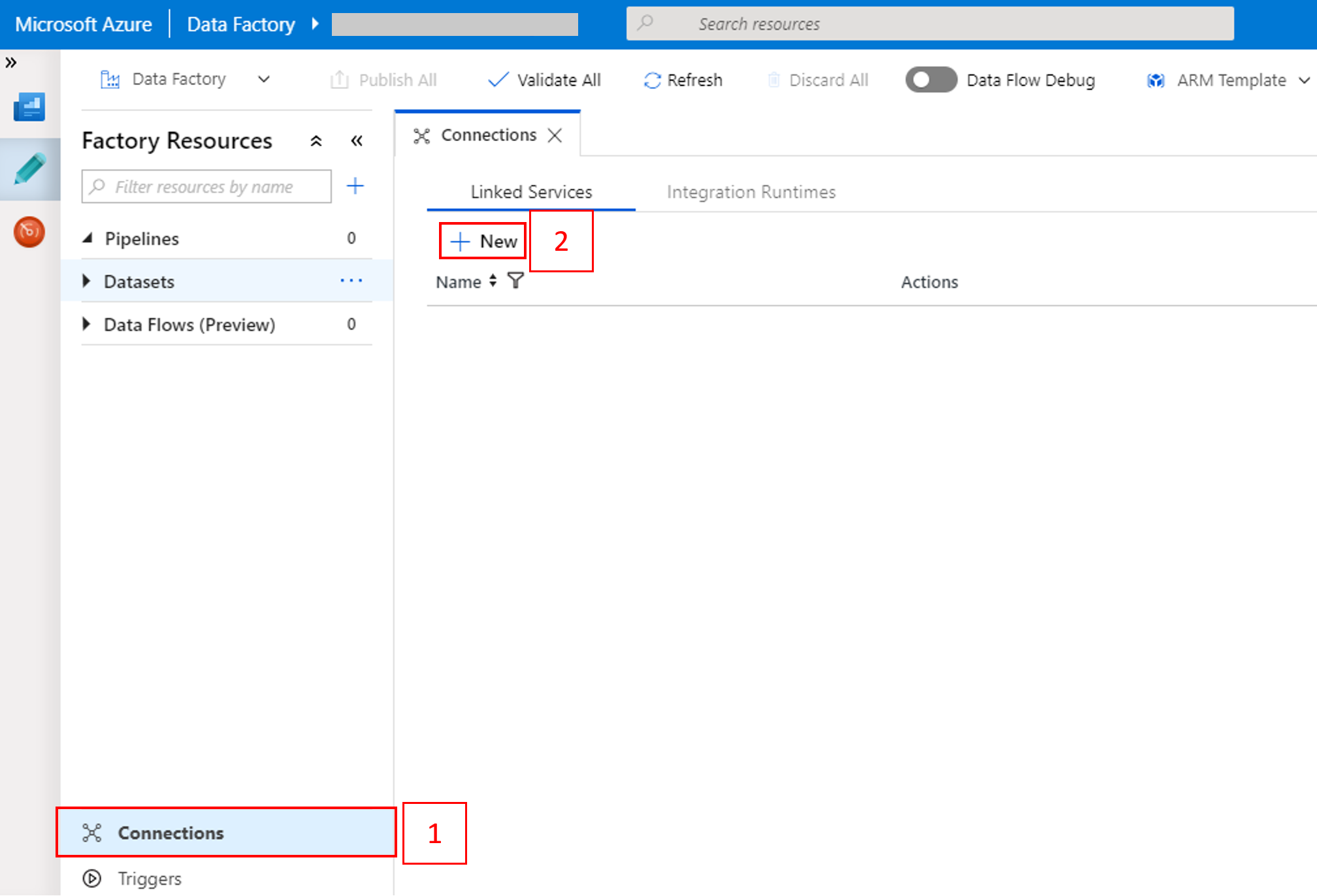
Select Connections at the bottom of the window, and then select + New.
In the New Linked Service window, select Data Store > Azure Blob Storage, and then select Continue.

For Storage account name, select the name from the list, and then select Save.

Create an on-demand HDInsight linked service
Select the + New button again to create another linked service.
In the New Linked Service window, select Compute > Azure HDInsight, and then select Continue.

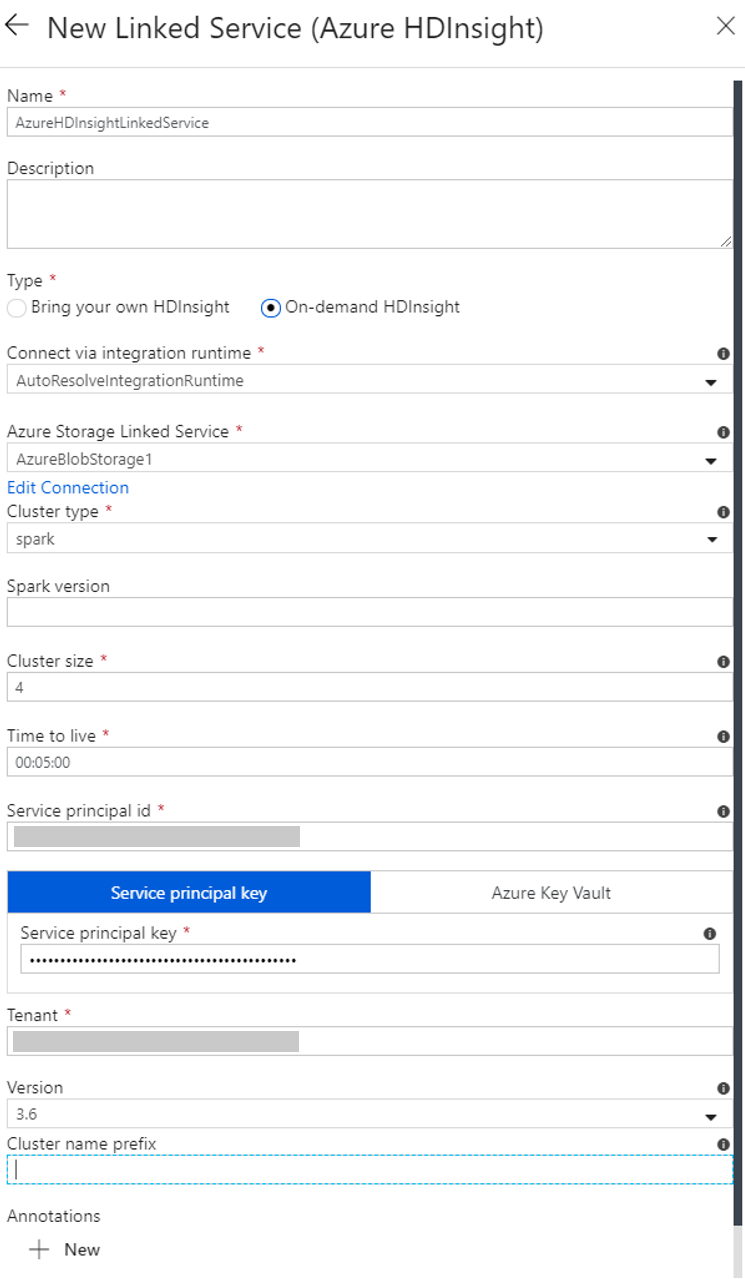
In the New Linked Service window, complete the following steps:
a. For Name, enter AzureHDInsightLinkedService.
b. For Type, confirm that On-demand HDInsight is selected.
c. For Azure Storage Linked Service, select AzureBlobStorage1. You created this linked service earlier. If you used a different name, specify the right name here.
d. For Cluster type, select spark.
e. For Service principal id, enter the ID of the service principal that has permission to create an HDInsight cluster.
This service principal needs to be a member of the Contributor role of the subscription or the resource group in which the cluster is created. For more information, see Create a Microsoft Entra application and service principal. The Service principal id is equivalent to the Application ID, and a Service principal key is equivalent to the value for a Client secret.
f. For Service principal key, enter the key.
g. For Resource group, select the same resource group that you used when you created the data factory. The Spark cluster is created in this resource group.
h. Expand OS type.
i. Enter a name for Cluster user name.
j. Enter the Cluster password for the user.
k. Select Finish.
Note
Azure HDInsight limits the total number of cores that you can use in each Azure region that it supports. For the on-demand HDInsight linked service, the HDInsight cluster is created in the same Azure Storage location that's used as its primary storage. Ensure that you have enough core quotas for the cluster to be created successfully. For more information, see Set up clusters in HDInsight with Hadoop, Spark, Kafka, and more.
Create a pipeline
Select the + (plus) button, and then select Pipeline on the menu.
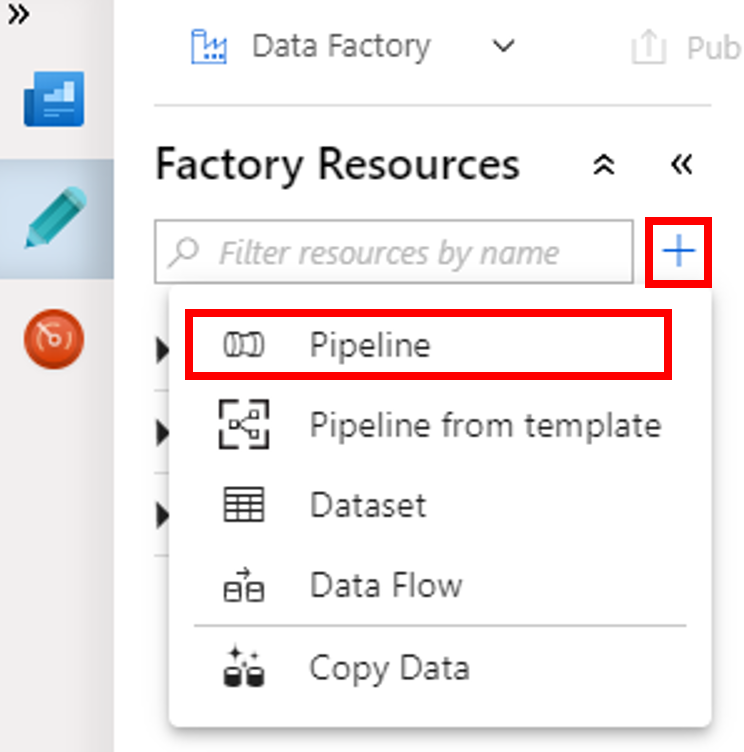
In the Activities toolbox, expand HDInsight. Drag the Spark activity from the Activities toolbox to the pipeline designer surface.
In the properties for the Spark activity window at the bottom, complete the following steps:
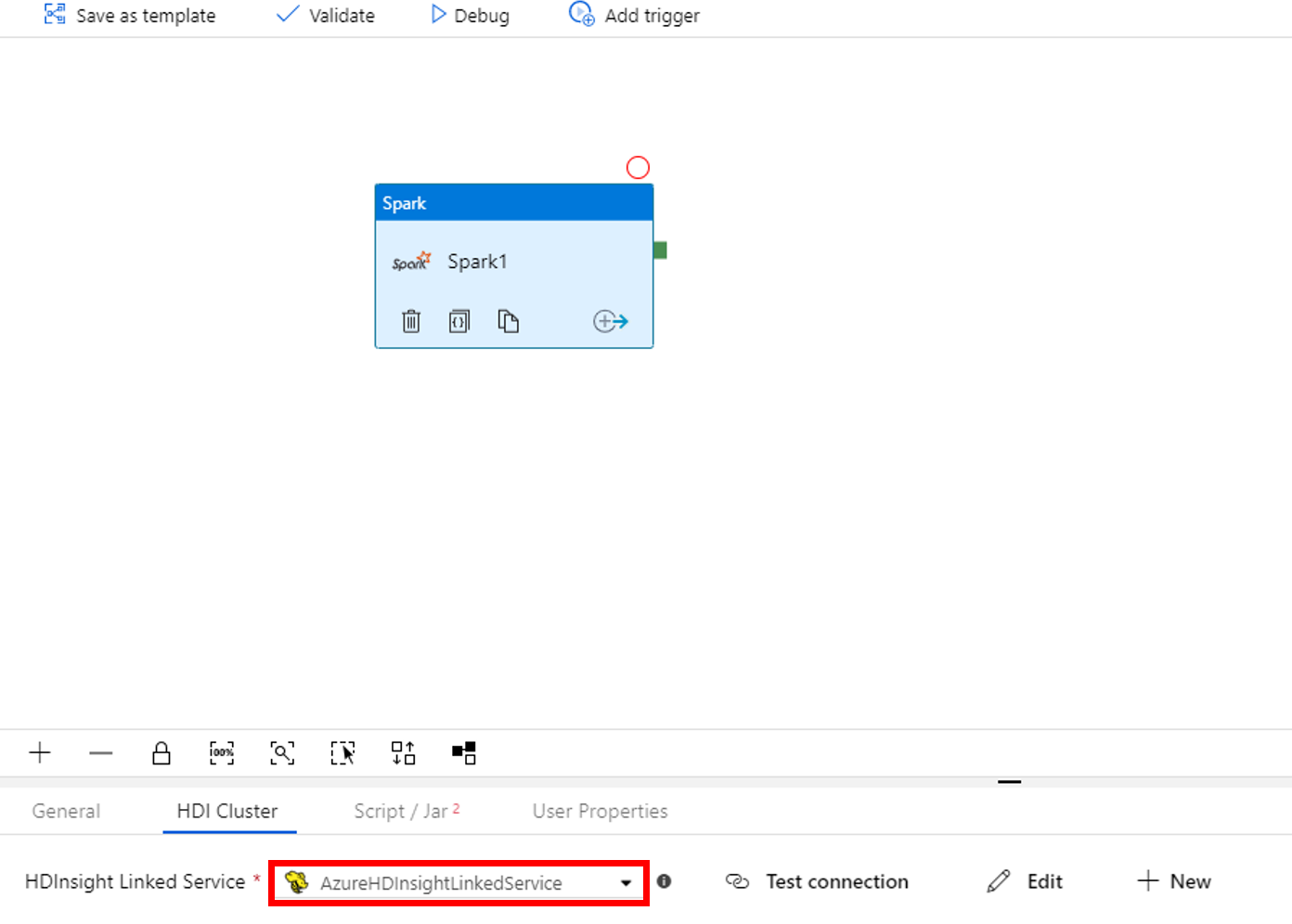
a. Switch to the HDI Cluster tab.
b. Select AzureHDInsightLinkedService (which you created in the previous procedure).
Switch to the Script/Jar tab, and complete the following steps:
a. For Job Linked Service, select AzureBlobStorage1.
b. Select Browse Storage.

c. Browse to the adftutorial/spark/script folder, select WordCount_Spark.py, and then select Finish.
To validate the pipeline, select the Validate button on the toolbar. Select the >> (right arrow) button to close the validation window.
Select Publish All. The Data Factory UI publishes entities (linked services and pipeline) to the Azure Data Factory service.
Trigger a pipeline run
Select Add Trigger on the toolbar, and then select Trigger Now.
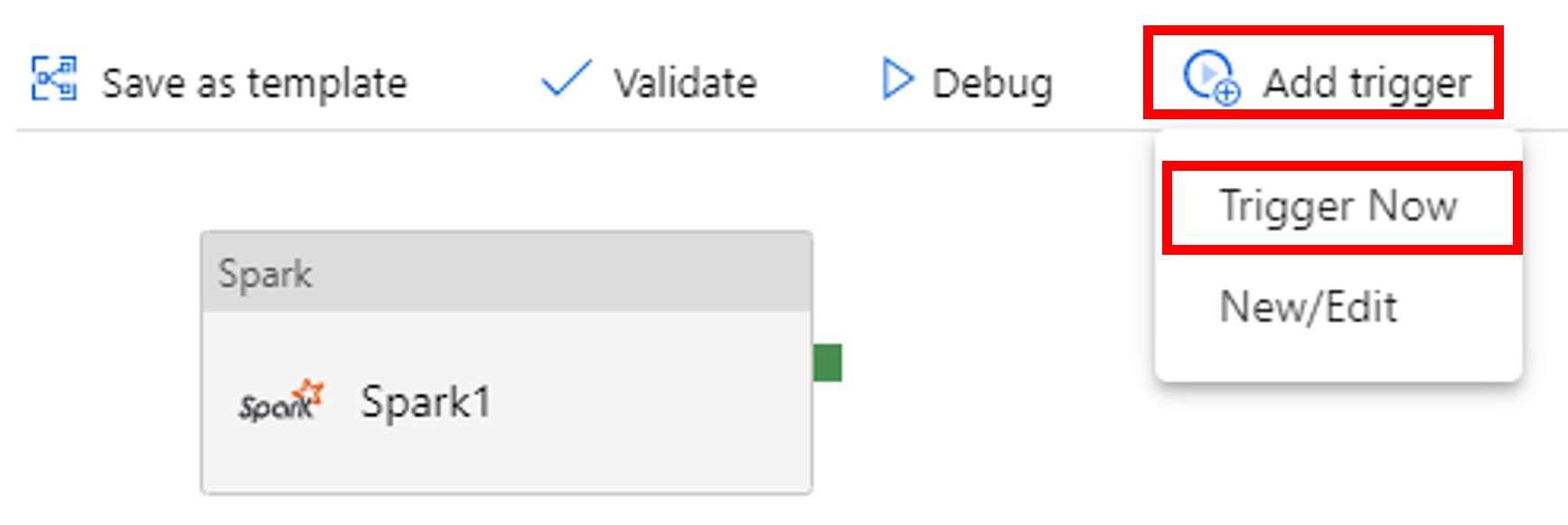
Monitor the pipeline run
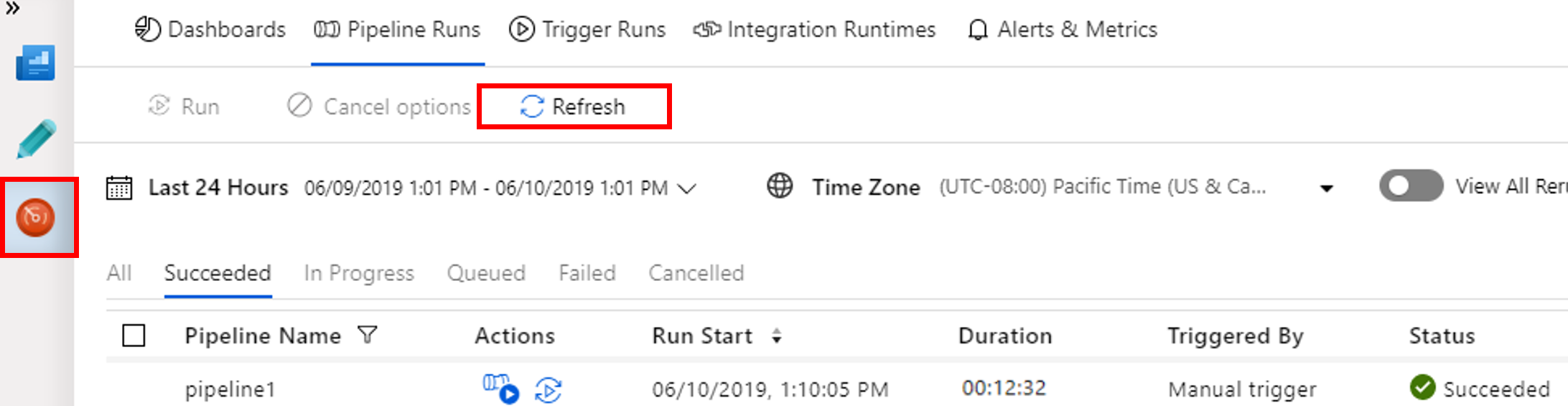
Switch to the Monitor tab. Confirm that you see a pipeline run. It takes approximately 20 minutes to create a Spark cluster.
Select Refresh periodically to check the status of the pipeline run.
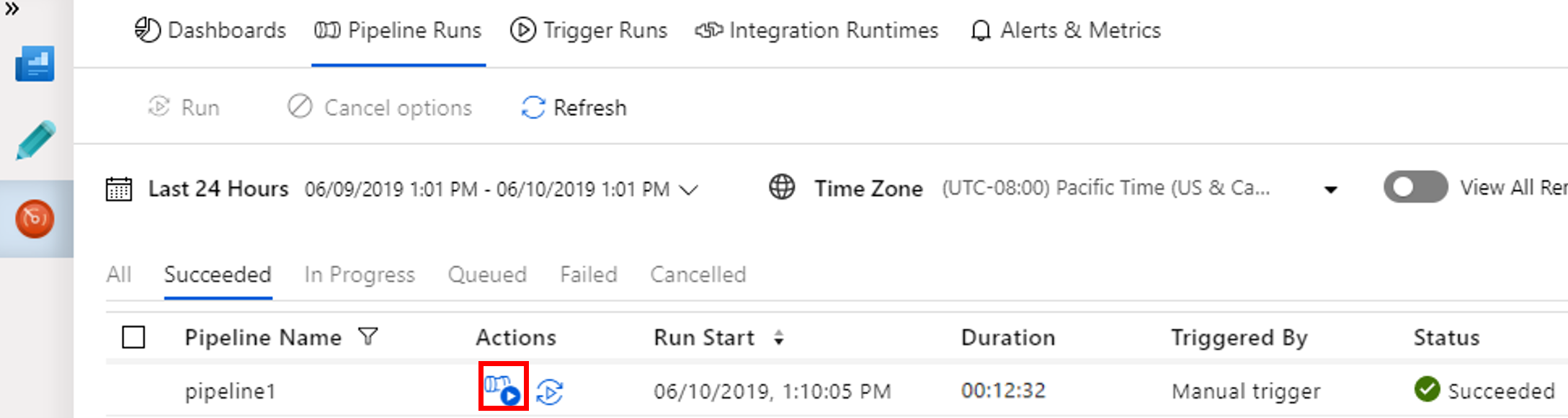
To see activity runs associated with the pipeline run, select View Activity Runs in the Actions column.
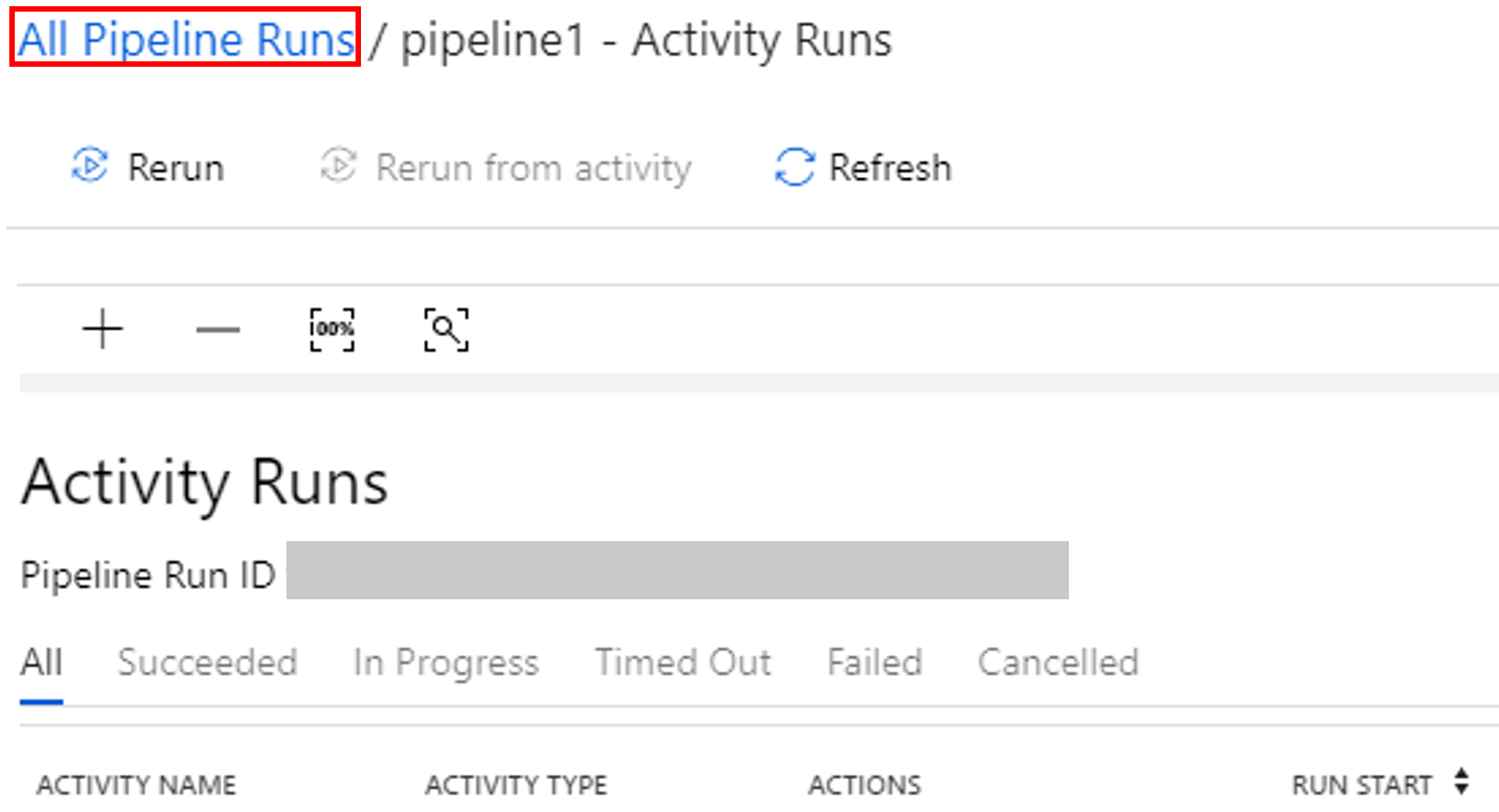
You can switch back to the pipeline runs view by selecting the All Pipeline Runs link at the top.
Verify the output
Verify that the output file is created in the spark/otuputfiles/wordcount folder of the adftutorial container.
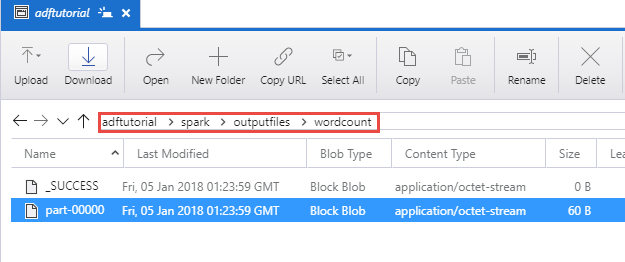
The file should have each word from the input text file and the number of times the word appeared in the file. For example:
(u'This', 1)
(u'a', 1)
(u'is', 1)
(u'test', 1)
(u'file', 1)
Related content
The pipeline in this sample transforms data by using a Spark activity and an on-demand HDInsight linked service. You learned how to:
- Create a data factory.
- Create a pipeline that uses a Spark activity.
- Trigger a pipeline run.
- Monitor the pipeline run.
To learn how to transform data by running a Hive script on an Azure HDInsight cluster that's in a virtual network, advance to the next tutorial:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for