Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is the next generation of Azure Data Factory, with a simpler architecture, built-in AI, and new features. If you're new to data integration, start with Fabric Data Factory. Existing ADF workloads can upgrade to Fabric to access new capabilities across data science, real-time analytics, and reporting.
Data wrangling in data factory allows you to build interactive Power Query mash-ups natively in ADF and then execute those at scale inside of an ADF pipeline.
Create a Power Query activity
There are two ways to create a Power Query in Azure Data Factory. One way is to click the plus icon and select Power Query in the factory resources pane.
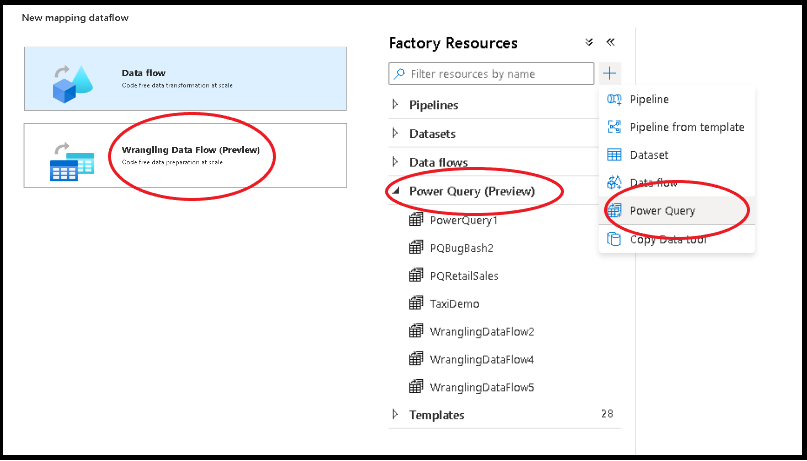
The other method is in the activities pane of the pipeline canvas. Open the Power Query accordion and drag the Power Query activity onto the canvas.
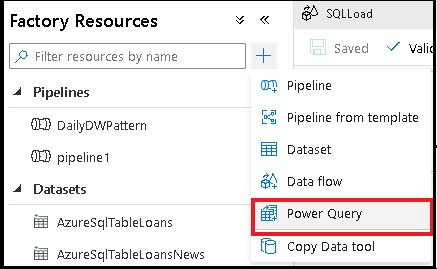
Author a Power Query data wrangling activity
Add a Source dataset for your Power Query mash-up. You can either choose an existing dataset or create a new one. After you have saved your mash-up, you can then create a pipeline, add the Power Query data wrangling activity to your pipeline and select a sink dataset to tell ADF where to land your data. While you can choose one or more source datasets, only one sink is allowed at this time. Choosing a sink dataset is optional, but at least one source dataset is required.
Click Create to open the Power Query Online mashup editor.
First, you will choose a dataset source for the mashup editor.
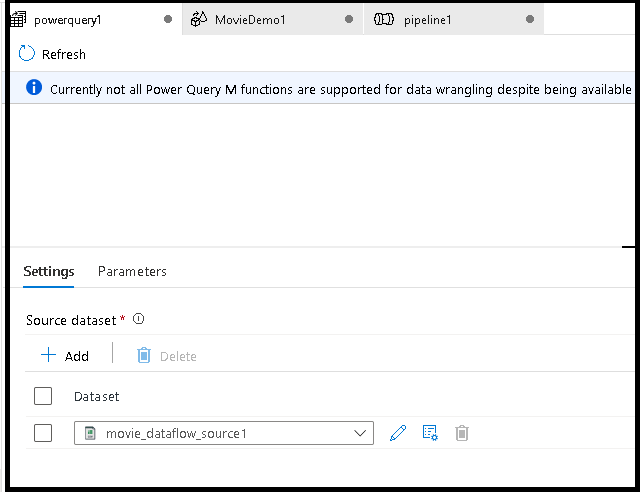
Once you have completed building your Power Query, you can save it and then create a pipeline. You need to add the mashup as an activity to your pipeline. That is when you will create/select the sink dataset to land your data. You can also set the sink dataset properties by clicking on the second button on the right side of the sinked dataset. Remember to change the "partition option" under "Optimize" to "Single partition" if you only want to get a single output file.
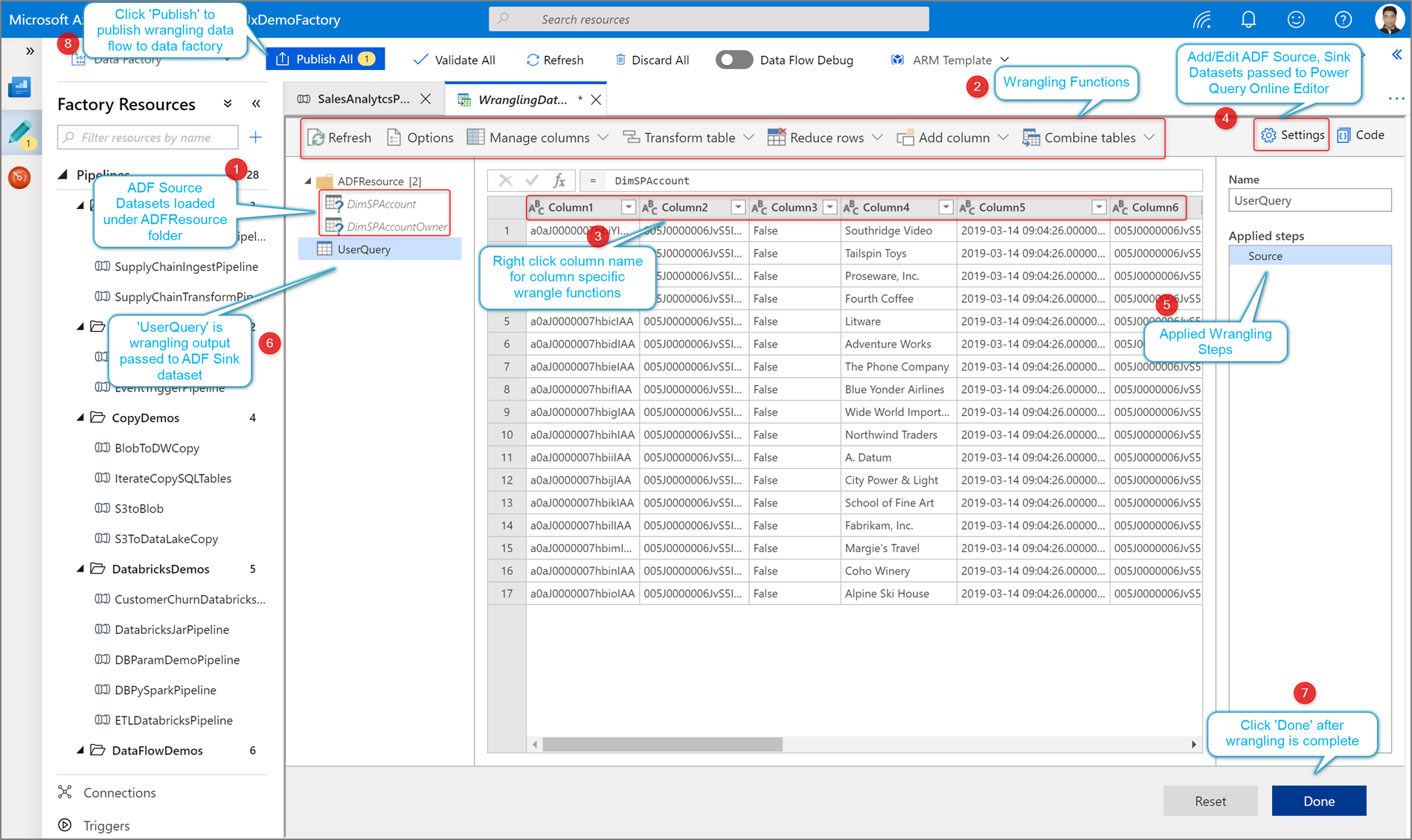
Author your wrangling Power Query using code-free data preparation. For the list of available functions, see transformation functions. ADF translates the M script into a data flow script so that you can execute your Power Query at scale using the Azure Data Factory data flow Spark environment.
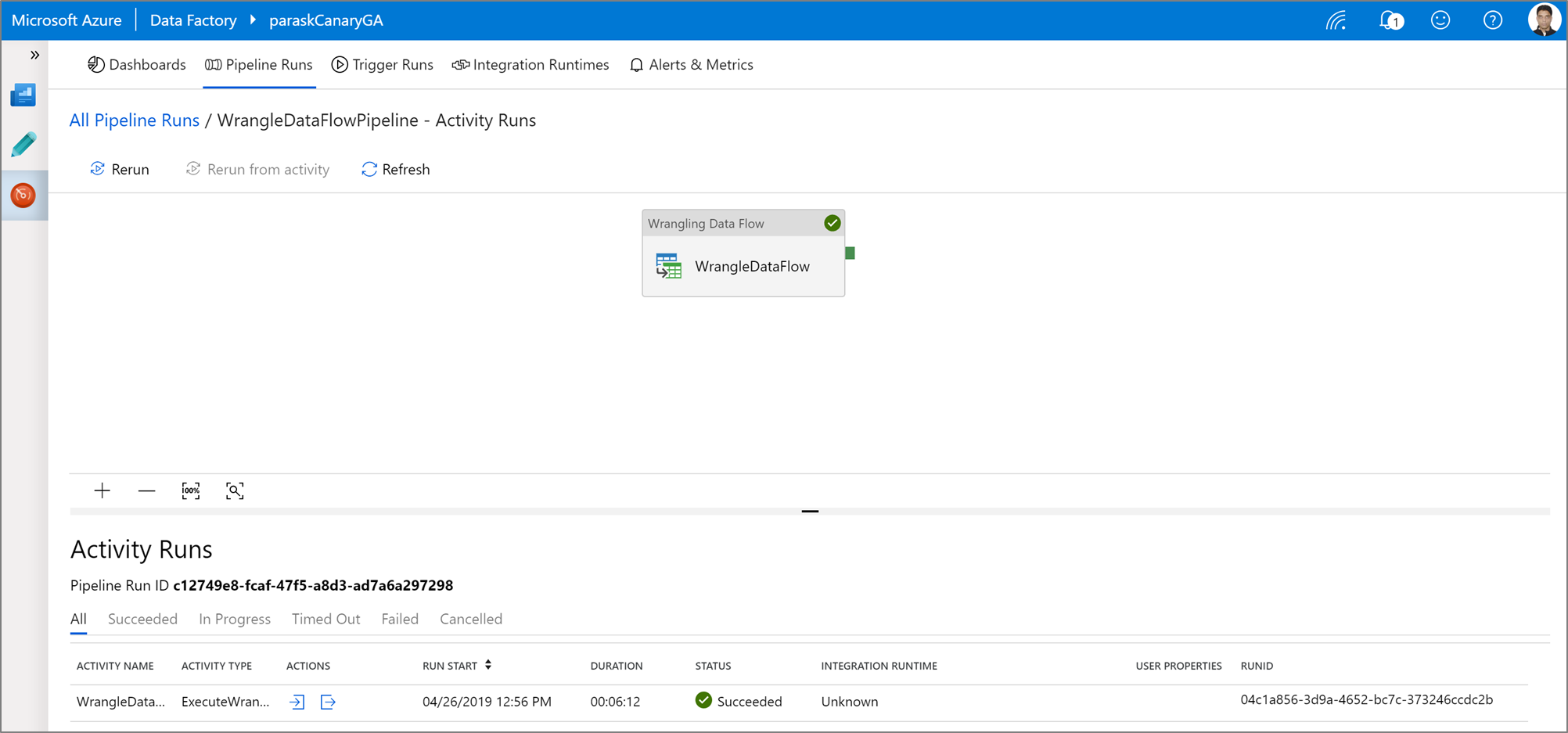
Running and monitoring a Power Query data wrangling activity
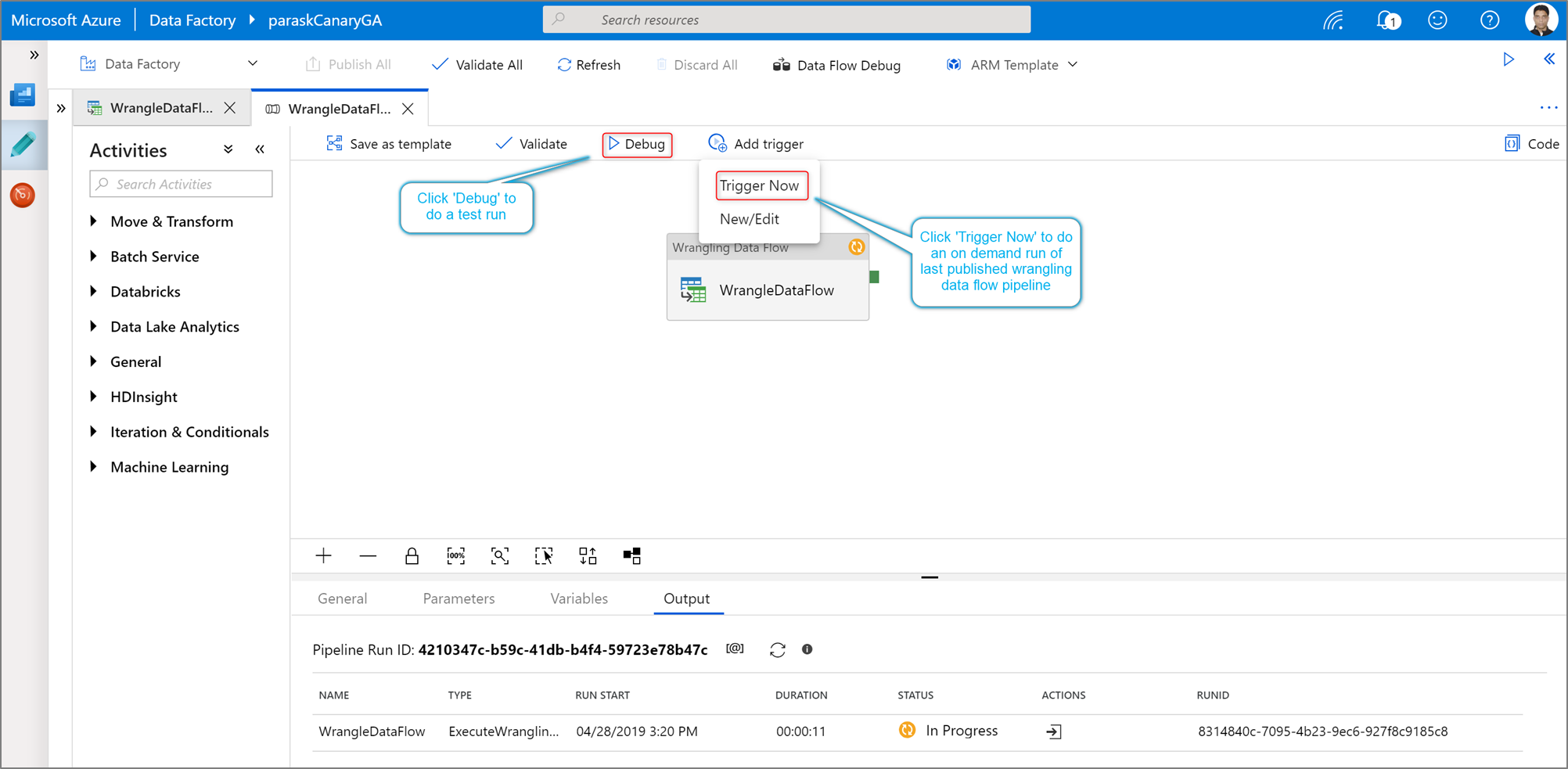
To execute a pipeline debug run of a Power Query activity, click Debug in the pipeline canvas. Once you publish your pipeline, Trigger now executes an on-demand run of the last published pipeline. Power Query pipelines can be schedule with all existing Azure Data Factory triggers.
Go to the Monitor tab to visualize the output of a triggered Power Query activity run.
Related content
Learn how to create a mapping data flow.