Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Build and deploy your first AI agent using Databricks Apps templates. In this tutorial you:
- Build and deploy agent from the Databricks Apps UI.
- Chat with the agent using a pre-built chat interface.
Prerequisites
Enable Databricks Apps in your workspace. See Set up your Databricks Apps workspace and development environment.
Deploy the agent template
Get started by using a pre-built agent template from the Databricks app templates repository.
This tutorial uses the agent-openai-agents-sdk template, which includes:
- An agent created using OpenAI Agent SDK
- Starter code for an agent application with a conversational REST API and an interactive chat UI
- Code to evaluate the agent using MLflow
Install the app template using the Workspace UI. This installs the app and deploys it to a compute resource in your workspace.
In your Databricks workspace, click + New > App.
Click Agents > Agent - OpenAI Agents SDK.
Create a new MLflow experiment with the name
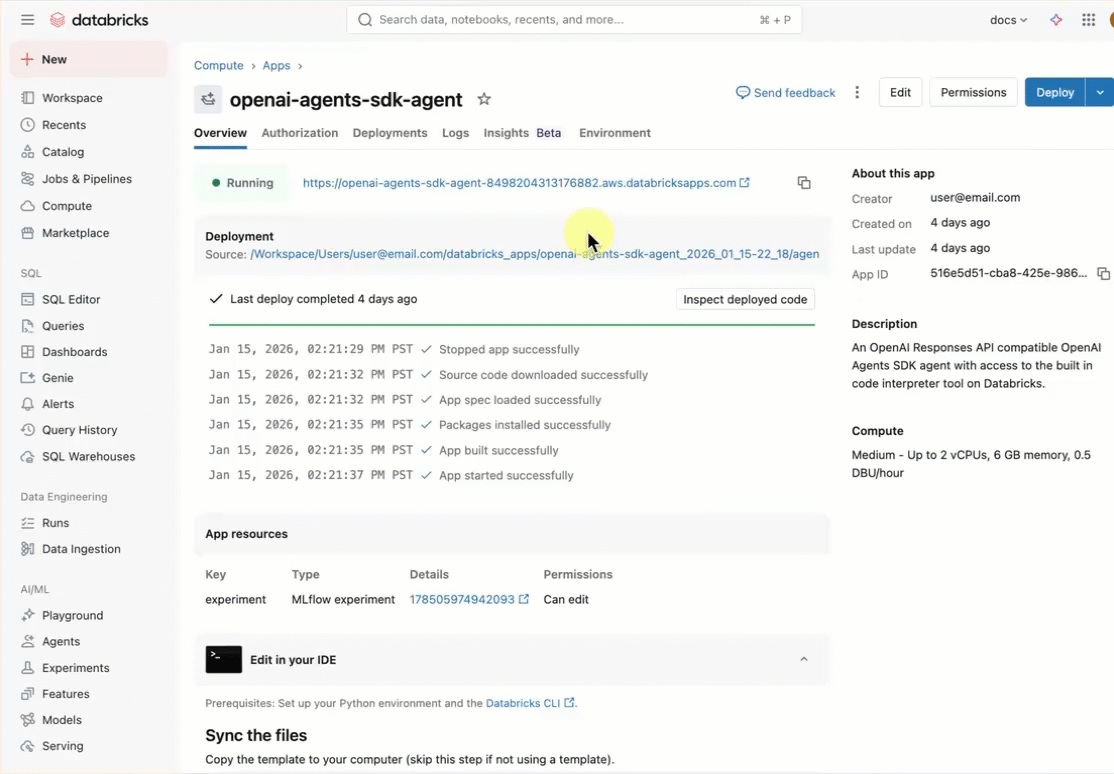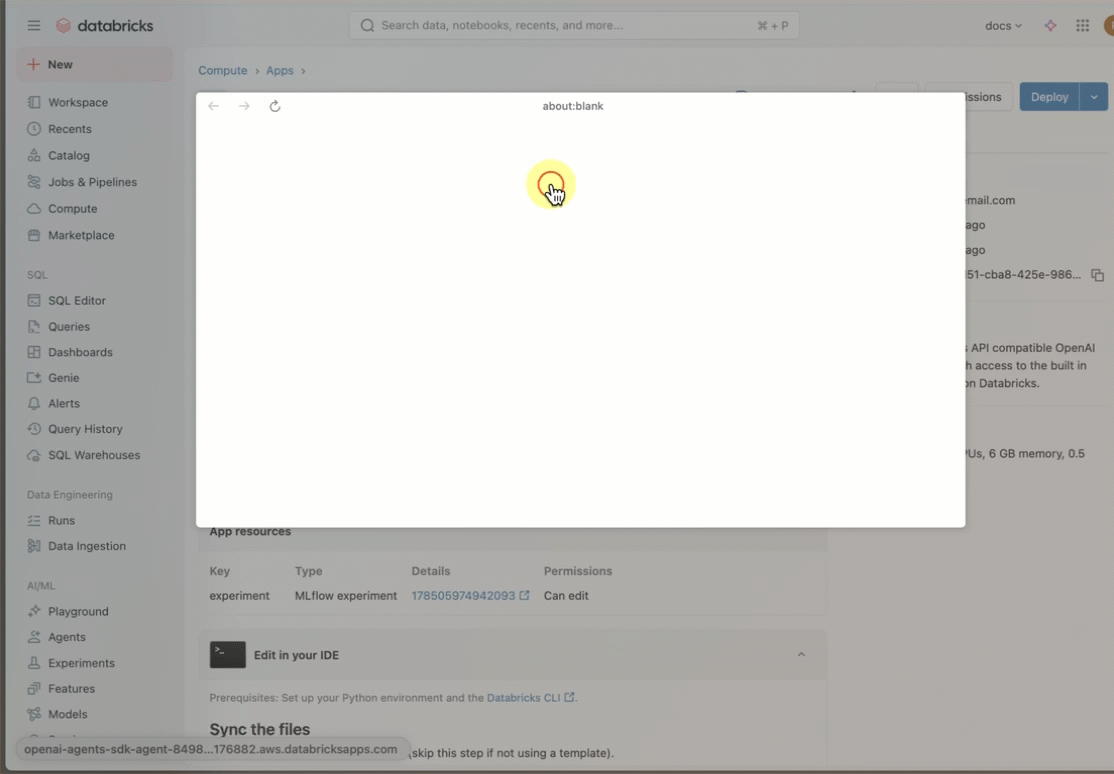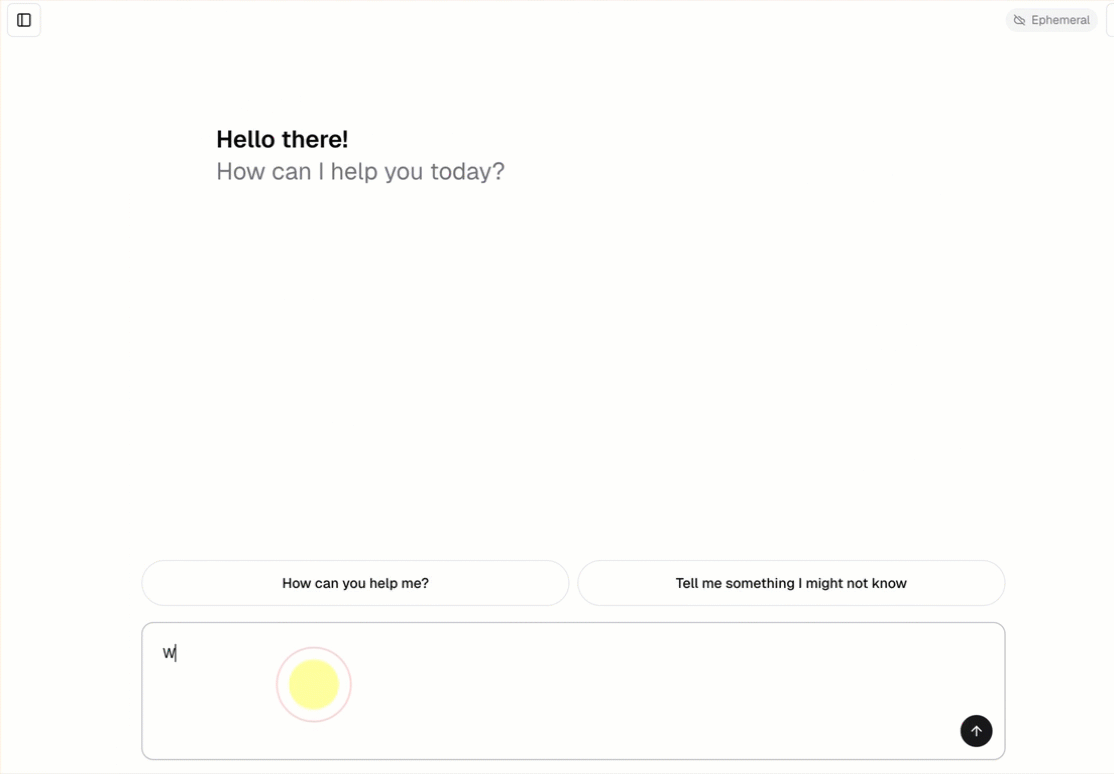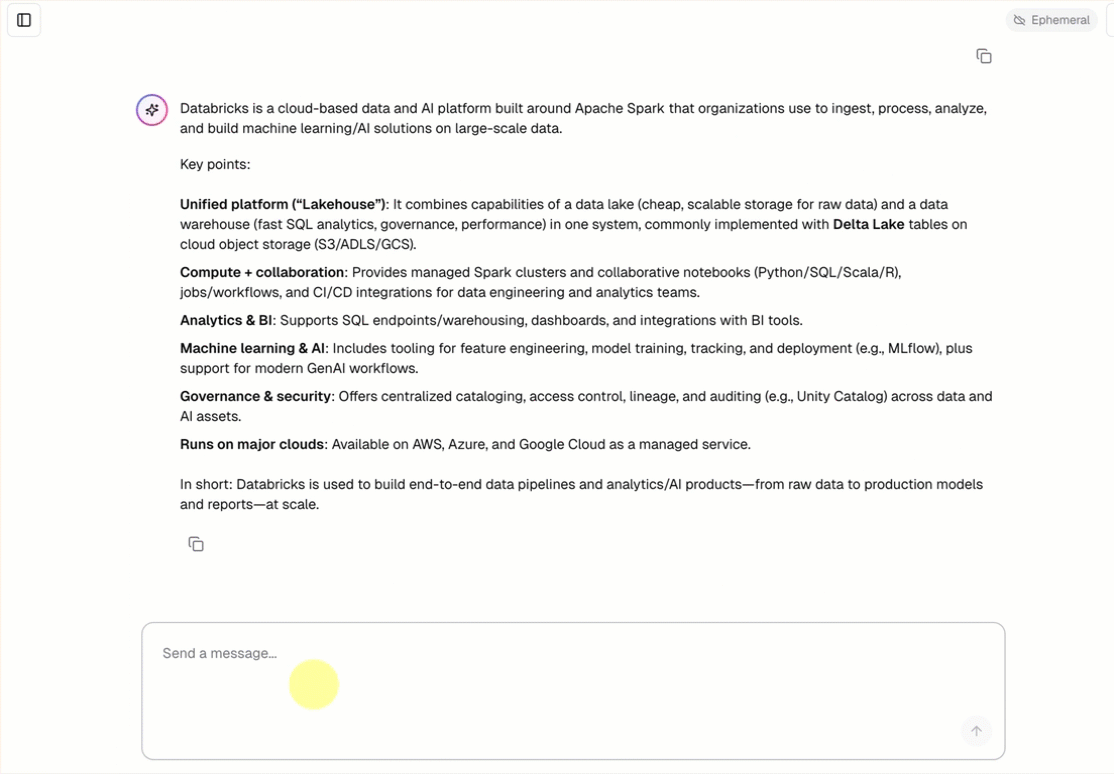
openai-agents-templateand complete the rest of the set up to install the template.After you create the app, click the app URL to open the chat UI.
Understand the agent application
The agent template demonstrates a production-ready architecture with these key components:
MLflow AgentServer: An async FastAPI server that handles agent requests with built-in tracing and observability. The AgentServer provides the /invocations endpoint for querying your agent and automatically manages request routing, logging, and error handling.
OpenAI Agents SDK: The template uses the OpenAI Agents SDK as the agent framework for conversation management and tool orchestration. You can author agents using any framework. The key is wrapping your agent with MLflow ResponsesAgent interface.
ResponsesAgent interface: This interface ensures your agent works across different frameworks and integrates with Databricks tools. Build your agent using OpenAI SDK, LangGraph, LangChain, or pure Python, then wrap it with ResponsesAgent to get automatic compatibility with AI Playground, Agent Evaluation, and Databricks Apps deployment.
MCP (Model Context Protocol) servers: The template connects to Databricks MCP servers to access agents to tools and data sources. See Model Context Protocol (MCP) on Azure Databricks.

Next steps
Learn how to author a custom agent:Author an AI agent and deploy it on Databricks Apps