Prerequisite: Gather requirements
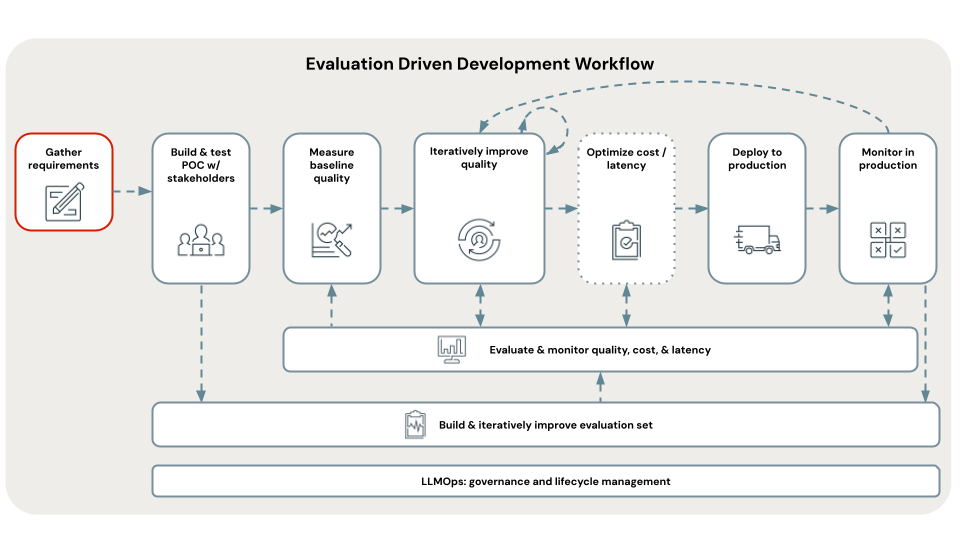
Defining clear and comprehensive use case requirements is a critical first step in developing a successful RAG application. These requirements serve two primary purposes. Firstly, they help determine whether RAG is the most suitable approach for the given use case. If RAG is indeed a good fit, these requirements guide solution design, implementation, and evaluation decisions. Investing time at the outset of a project to gather detailed requirements can prevent significant challenges and setbacks later in the development process, and ensures that the resulting solution meets the needs of end-users and stakeholders. Well-defined requirements provide the foundation for the subsequent stages of the development lifecycle we’ll walk through.
See the GitHub repository for the sample code in this section. You can also use the repository code as a template with which to create your own AI applications.
Is the use case a good fit for RAG?
The first thing you need to establish is whether RAG is even the right approach for your use case. Given the hype around RAG, it’s tempting to view it as a possible solution for any problem. However, there are nuances as to when RAG is suitable versus not.
RAG is a good fit when:
- Reasoning over retrieved information (both unstructured and structured) that doesn’t entirely fit within the LLM’s context window
- Synthesizing information from multiple sources (for example, generating a summary of key points from different articles on a topic)
- Dynamic retrieval based on a user query is necessary (for example, given a user query, determine what data source to retrieve from)
- The use case requires generating novel content based on retrieved information (for example, answering questions, providing explanations, offering recommendations)
RAG may not be the best fit when:
- The task does not require query-specific retrieval. For example, generating call transcript summaries; even if individual transcripts are provided as context in the LLM prompt, the retrieved information remains the same for each summary.
- The entire set of information to retrieve can fit within the LLM’s context window
- Extremely low-latency responses are required (for example, when responses are required in milliseconds)
- Simple rule-based or templated responses are sufficient (for example, a customer support chatbot that provides predefined answers based on keywords)
Requirements to discover
After you have established that RAG is a good fit for your use case, consider the following questions to capture concrete requirements. The requirements are prioritized as follows:
🟢 P0: Must define this requirement before starting your POC.
🟡 P1: Must define before going to production, but can iteratively refine during the POC.
⚪ P2: Nice to have requirement.
This is not an exhaustive list of questions. However, it should provide a solid foundation for capturing the key requirements for your RAG solution.
User experience
Define how users will interact with the RAG system and what kind of responses are expected
🟢 [P0] What will a typical request to the RAG chain look like? Ask stakeholders for examples of potential user queries.
🟢 [P0] What kind of responses will users expect (short answers, long-form explanations, a combination, or something else)?
🟡 [P1] How will users interact with the system? Through a chat interface, search bar, or some other modality?
🟡 [P1] hat tone or style should generated responses take? (formal, conversational, technical?)
🟡 [P1] How should the application handle ambiguous, incomplete, or irrelevant queries? Should any form of feedback or guidance be provided in such cases?
⚪ [P2] Are there specific formatting or presentation requirements for the generated output? Should the output include any metadata in addition to the chain’s response?
Data
Determine the nature, source(s), and quality of the data that will be used in the RAG solution.
🟢 [P0] What are the available sources to use?
For each data source:
- 🟢 [P0] Is data structured or unstructured?
- 🟢 [P0] What is the source format of the retrieval data (e.g., PDFs, documentation with images/tables, structured API responses)?
- 🟢 [P0] Where does that data reside?
- 🟢 [P0] How much data is available?
- 🟡 [P1] How frequently is the data updated? How should those updates be handled?
- 🟡 [P1] Are there any known data quality issues or inconsistencies for each data source?
Consider creating an inventory table to consolidate this information, for example:
| Data source | Source | File type(s) | Size | Update frequency |
|---|---|---|---|---|
| Data source 1 | Unity Catalog volume | JSON | 10GB | Daily |
| Data source 2 | Public API | XML | NA (API) | Real-time |
| Data source 3 | SharePoint | PDF, .docx | 500MB | Monthly |
Performance constraints
Capture performance and resource requirements for the RAG application.
🟡 [P1] What is the maximum acceptable latency for generating the responses?
🟡 [P1] What is the maximum acceptable time to first token?
🟡 [P1] If the output is being streamed, is higher total latency acceptable?
🟡 [P1] Are there any cost limitations on compute resources available for inference?
🟡 [P1] What are the expected usage patterns and peak loads?
🟡 [P1] How many concurrent users or requests should the system be able to handle? Databricks natively handles such scalability requirements, through the ability to scale automatically with Model Serving.
Evaluation
Establish how the RAG solution will be evaluated and improved over time.
🟢 [P0] What is the business goal / KPI you want to impact? What is the baseline value and what is the target?
🟢 [P0] Which users or stakeholders will provide initial and ongoing feedback?
🟢 [P0] What metrics should be used to assess the quality of generated responses? Mosaic AI Agent Evaluation provides a recommended set of metrics to use.
🟡 [P1] What is the set of questions the RAG app must be good at to go to production?
🟡 [P1] Does an [evaluation set] exist? Is it possible to get an evaluation set of user queries, along with ground-truth answers and (optionally) the correct supporting documents that should be retrieved?
🟡 [P1] How will user feedback be collected and incorporated into the system?
Security
Identify any security and privacy considerations.
🟢 [P0] Are there sensitive/confidential data that needs to be handled with care?
🟡 [P1] Do access controls need to be implemented in the solution (for example, a given user can only retrieve from a restricted set of documents)?
Deployment
Understanding how the RAG solution will be integrated, deployed, and maintained.
🟡 How should the RAG solution integrate with existing systems and workflows?
🟡 How should the model be deployed, scaled, and versioned? This tutorial covers how the end-to-end lifecycle can be handled on Databricks using MLflow, Unity Catalog, Agent SDK, and Model Serving.
Example
As an example, consider how these questions apply to this example RAG application used by a Databricks customer support team:
| Area | Considerations | Requirements |
|---|---|---|
| User experience | - Interaction modality. - Typical user query examples. - Expected response format and style. - Handling ambiguous or irrelevant queries. |
- Chat interface integrated with Slack. - Example queries: “How do I reduce cluster startup time?” “What kind of support plan do I have?” - Clear, technical responses with code snippets and links to relevant documentation where appropriate. - Provide contextual suggestions and escalate to support engineers when needed. |
| Data | - Number and type of data sources. - Data format and location. - Data size and update frequency. - Data quality and consistency. |
- Three data sources. - Company documentation (HTML, PDF). - Resolved support tickets (JSON). - Community forum posts (Delta table). - Data stored in Unity Catalog and updated weekly. - Total data size: 5GB. - Consistent data structure and quality maintained by dedicated docs and support teams. |
| Performance | - Maximum acceptable latency. - Cost constraints. - Expected usage and concurrency. |
- Maximum latency requirement. - Cost constraints. - Expected peak load. |
| Evaluation | - Evaluation dataset availability. - Quality metrics. - User feedback collection. |
- Subject matter experts from each product area help review outputs and adjust incorrect answers to create the evaluation dataset. - Business KPIs. - Increase in support ticket resolution rate. - Decrease in user time spent per support ticket. - Quality metrics. - LLM-judged answer correctness and relevance. - LLM judges retrieval precision. - User upvote or downvote. - Feedback collection. - Slack will be instrumented to provide a thumbs up / down. |
| Security | - Sensitive data handling. - Access control requirements. |
- No sensitive customer data should be in the retrieval source. - User authentication through Databricks Community SSO. |
| Deployment | - Integration with existing systems. - Deployment and versioning. |
- Integration with support ticket system. - Chain deployed as a Databricks Model Serving endpoint. |
Next step
Get started with Step 1. Clone code repository and create compute.