Introduction to Databricks Lakehouse Monitoring
Important
This feature is in Public Preview.
This article describes Databricks Lakehouse Monitoring. It covers the benefits of monitoring your data and gives an overview of the components and usage of Databricks Lakehouse Monitoring.
Databricks Lakehouse Monitoring lets you monitor the statistical properties and quality of the data in all of the tables in your account. You can also use it to track the performance of machine learning models and model-serving endpoints by monitoring inference tables that contain model inputs and predictions. The diagram shows the flow of data through data and ML pipelines in Databricks, and how you can use monitoring to continuously track data quality and model performance.
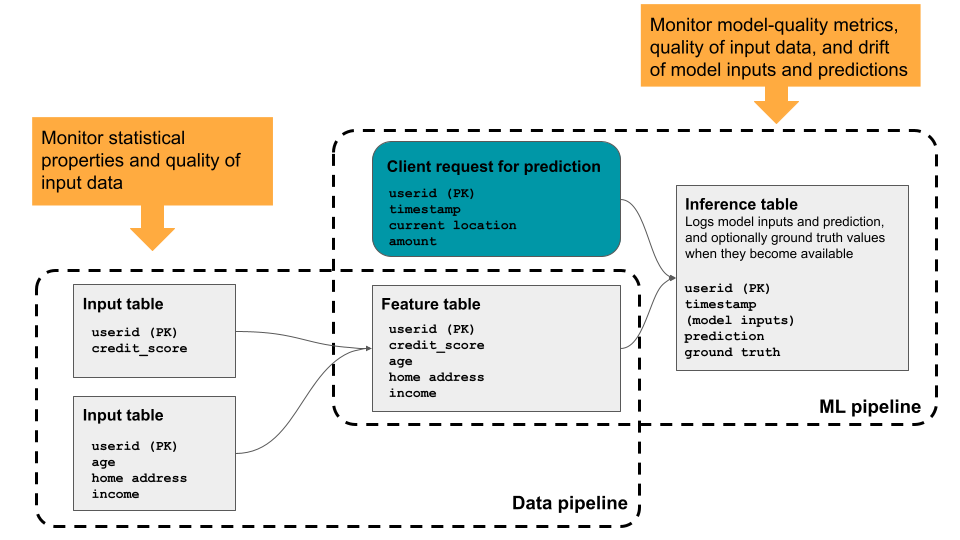
Why use Databricks Lakehouse Monitoring?
To draw useful insights from your data, you must have confidence in the quality of your data. Monitoring your data provides quantitative measures that help you track and confirm the quality and consistency of your data over time. When you detect changes in your table’s data distribution or corresponding model’s performance, the tables created by Databricks Lakehouse Monitoring can capture and alert you to the change and can help you identify the cause.
Databricks Lakehouse Monitoring helps you answer questions like the following:
- What does data integrity look like, and how does it change over time? For example, what is the fraction of null or zero values in the current data, and has it increased?
- What does the statistical distribution of the data look like, and how does it change over time? For example, what is the 90th percentile of a numerical column? Or, what is the distribution of values in a categorical column, and how does it differ from yesterday?
- Is there drift between the current data and a known baseline, or between successive time windows of the data?
- What does the statistical distribution or drift of a subset or slice of the data look like?
- How are ML model inputs and predictions shifting over time?
- How is model performance trending over time? Is model version A performing better than version B?
In addition, Databricks Lakehouse Monitoring lets you control the time granularity of observations and set up custom metrics.
Requirements
The following are required to use Databricks Lakehouse Monitoring:
- Your workspace must be enabled for Unity Catalog and you must have access to Databricks SQL.
- Only Delta tables, including managed tables, external tables, views, materialized views, and streaming tables are supported for monitoring. Monitors created over materialized views and streaming tables do not support incremental processing.
- Not all regions are supported. For regional support, see Azure Databricks regions.
Note
Databricks Lakehouse Monitoring uses serverless compute for workflows. For information about tracking Lakehouse Monitoring expenses, see View Lakehouse Monitoring expenses.
How Lakehouse Monitoring works on Databricks
To monitor a table in Databricks, you create a monitor attached to the table. To monitor the performance of a machine learning model, you attach the monitor to an inference table that holds the model’s inputs and corresponding predictions.
Databricks Lakehouse Monitoring provides the following types of analysis: time series, snapshot, and inference.
| Profile type | Description |
|---|---|
| Time series | Use for tables that contain a time series dataset based on a timestamp column. Monitoring computes data quality metrics across time-based windows of the time series. |
| Inference | Use for tables that contain the request log for a model. Each row is a request, with columns for the timestamp , the model inputs, the corresponding prediction, and (optional) ground-truth label. Monitoring compares model performance and data quality metrics across time-based windows of the request log. |
| Snapshot | Use for all other types of tables. Monitoring calculates data quality metrics over all data in the table. The complete table is processed with every refresh. |
This section briefly describes the input tables used by Databricks Lakehouse Monitoring and the metric tables it produces. The diagram shows the relationship between the input tables, the metric tables, the monitor, and the dashboard.
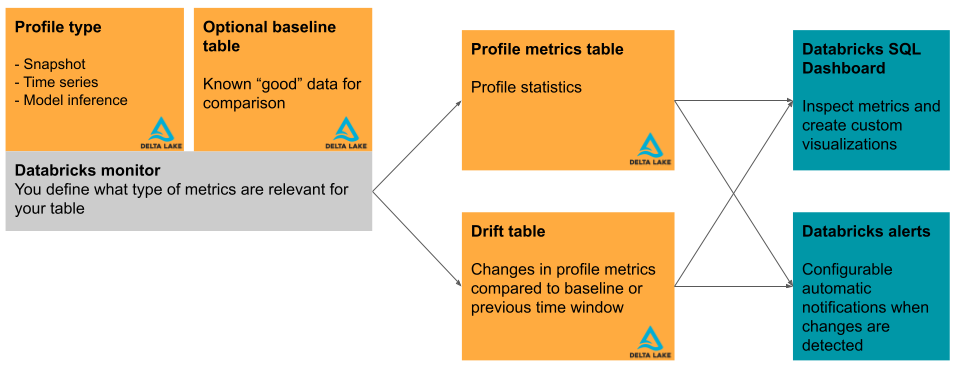
Primary table and baseline table
In addition to the table to be monitored, called the “primary table”, you can optionally specify a baseline table to use as a reference for measuring drift, or the change in values over time. A baseline table is useful when you have a sample of what you expect your data to look like. The idea is that drift is then computed relative to expected data values and distributions.
The baseline table should contain a dataset that reflects the expected quality of the input data, in terms of statistical distributions, individual column distributions, missing values, and other characteristics. It should match the schema of the monitored table. The exception is the timestamp column for tables used with time series or inference profiles. If columns are missing in either the primary table or the baseline table, monitoring uses best-effort heuristics to compute the output metrics.
For monitors that use a snapshot profile, the baseline table should contain a snapshot of the data where the distribution represents an acceptable quality standard. For example, on grade distribution data, one might set the baseline to a previous class where grades were distributed evenly.
For monitors that use a time series profile, the baseline table should contain data that represents time window(s) where data distributions represent an acceptable quality standard. For example, on weather data, you might set the baseline to a week, month, or year where the temperature was close to expected normal temperatures.
For monitors that use an inference profile, a good choice for a baseline is the data that was used to train or validate the model being monitored. In this way, users can be alerted when the data has drifted relative to what the model was trained and validated on. This table should contain the same feature columns as the primary table, and additionally should have the same model_id_col that was specified for the primary table’s InferenceLog so that the data is aggregated consistently. Ideally, the test or validation set used to evaluate the model should be used to ensure comparable model quality metrics.
Metric tables and dashboard
A table monitor creates two metric tables and a dashboard. Metric values are computed for the entire table, and for the time windows and data subsets (or “slices”) that you specify when you create the monitor. In addition, for inference analysis, metrics are computed for each model ID. For more details about the metric tables, see Monitor metric tables.
- The profile metric table contains summary statistics. See the profile metrics table schema.
- The drift metrics table contains statistics related to the data’s drift over time. If a baseline table is provided, drift is also monitored relative to the baseline values. See the drift metrics table schema.
The metric tables are Delta tables and are stored in a Unity Catalog schema that you specify. You can view these tables using the Databricks UI, query them using Databricks SQL, and create dashboards and alerts based on them.
For each monitor, Databricks automatically creates a dashboard to help you visualize and present the monitor results. The dashboard is fully customizable like any other legacy dashboard.
Start using Lakehouse Monitoring on Databricks
See the following articles to get started:
- Create a monitor using the Databricks UI.
- Create a monitor using the API.
- Understand monitor metric tables.
- Work with the monitor dashboard.
- Create SQL alerts based on a monitor.
- Create custom metrics.
- Monitor model serving endpoints.
- Monitor fairness and bias for classification models.
- See the reference material for the Databricks Lakehouse Monitoring API.
- Example notebooks.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for