Connect to OneLake Storage
Important
This feature is currently in preview. The Supplemental Terms of Use for Microsoft Azure Previews include more legal terms that apply to Azure features that are in beta, in preview, or otherwise not yet released into general availability. For information about this specific preview, see Azure HDInsight on AKS preview information. For questions or feature suggestions, please submit a request on AskHDInsight with the details and follow us for more updates on Azure HDInsight Community.
This tutorial shows how to connect to OneLake with a Jupyter notebook from an Azure HDInsight on AKS cluster.
Create an HDInsight on AKS cluster with Apache Spark™. Follow these instructions: Set up clusters in HDInsight on AKS.
While providing cluster information, remember your Cluster login Username and Password, as you need them later to access the cluster.
Create a user assigned managed identity (UAMI): Create for Azure HDInsight on AKS - UAMI and choose it as the identity in the Storage screen.

Give this UAMI access to the Fabric workspace that contains your items. Learn more about Fabric role-based access control (RBAC): Workspace roles to decide what role is suitable.
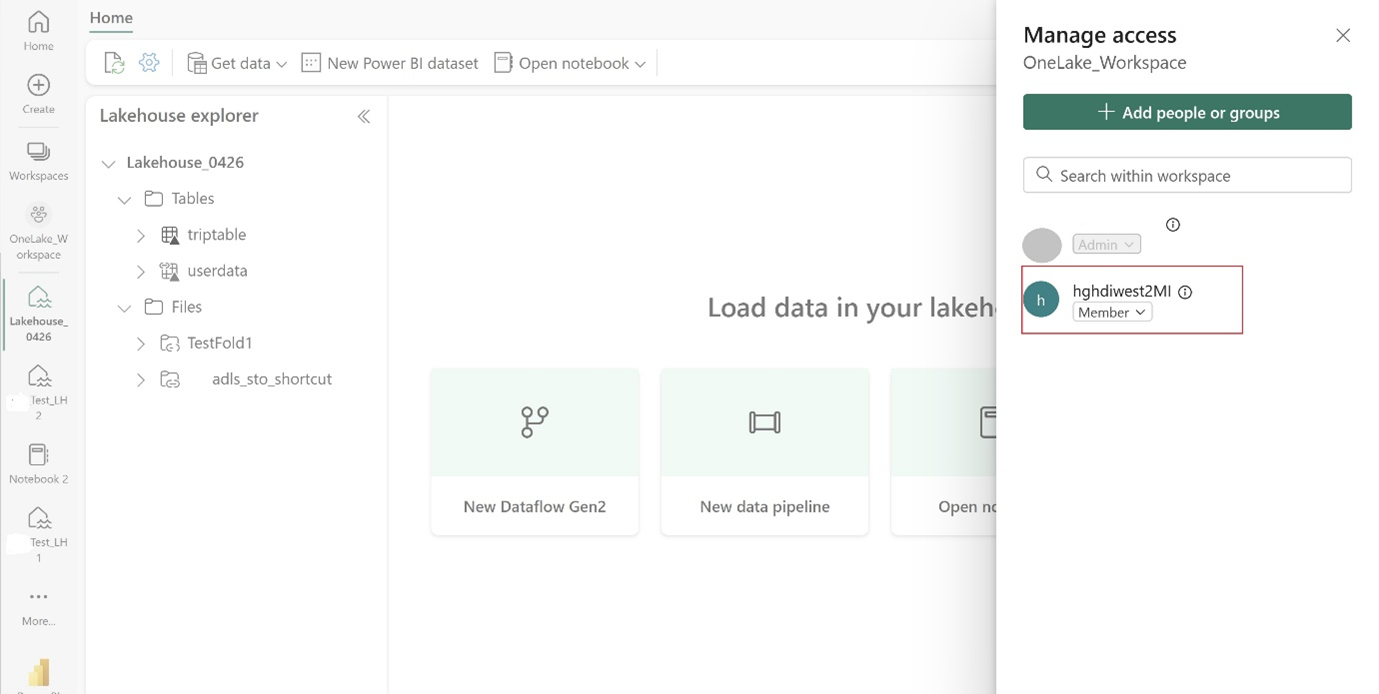
Navigate to your Lakehouse and find the Name for your workspace and Lakehouse. You can find them in the URL of your Lakehouse or the Properties pane for a file.
In the Azure portal, look for your cluster and select the notebook.
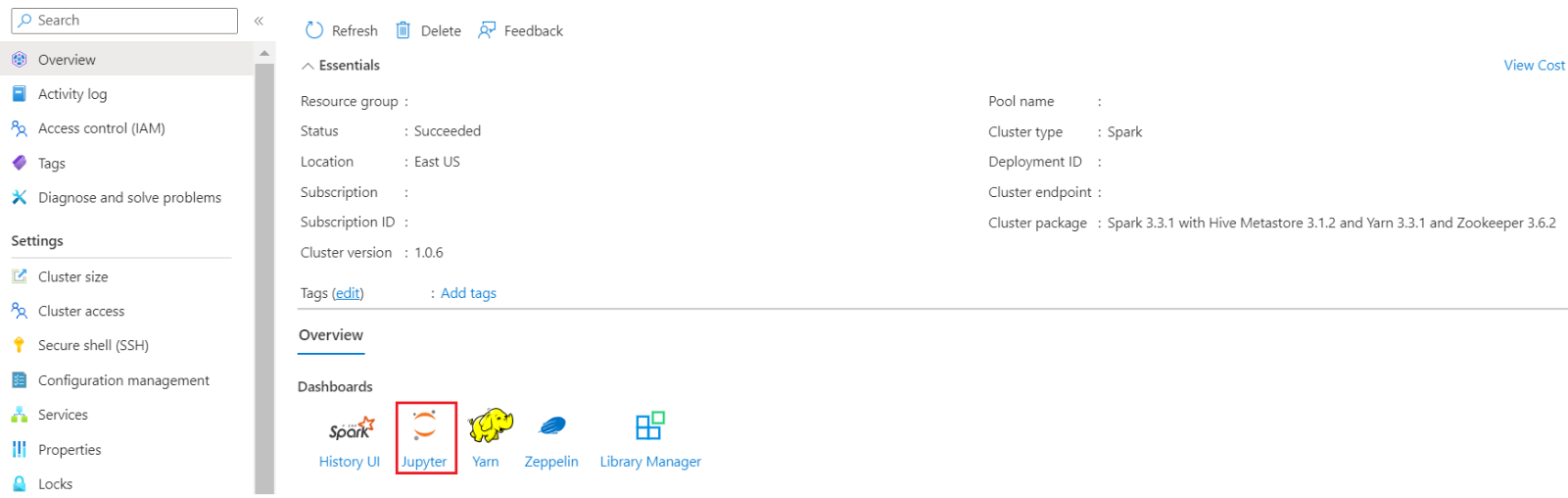
Create a new Notebook and select type as pyspark.
Copy the workspace and Lakehouse names into your notebook and build your OneLake URL for your Lakehouse. Now you can read any file from this file path.
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' 1df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") 1df.show()Try to write some data into the Lakehouse.
writecsvdf = df.write.format("csv").save(fp + "out.csv")Test that your data was successfully written by checking in your Lakehouse or by reading your newly loaded file.



Reference
- Apache, Apache Spark, Spark, and associated open source project names are trademarks of the Apache Software Foundation (ASF).
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for