Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Learn how to use Apache Spark to stream data into or out of Apache Kafka on HDInsight using DStreams. This example uses a Jupyter Notebook that runs on the Spark cluster.
Note
The steps in this document create an Azure resource group that contains both a Spark on HDInsight and a Kafka on HDInsight cluster. These clusters are both located within an Azure Virtual Network, which allows the Spark cluster to directly communicate with the Kafka cluster.
When you are done with the steps in this document, remember to delete the clusters to avoid excess charges.
Important
This example uses DStreams, which is an older Spark streaming technology. For an example that uses newer Spark streaming features, see the Spark Structured Streaming with Apache Kafka document.
Create the clusters
Apache Kafka on HDInsight doesn't provide access to the Kafka brokers over the public internet. Anything that talks to Kafka must be in the same Azure virtual network as the nodes in the Kafka cluster. For this example, both the Kafka and Spark clusters are located in an Azure virtual network. The following diagram shows how communication flows between the clusters:
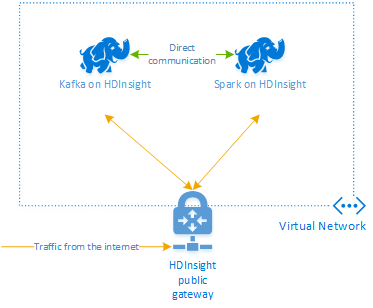
Note
Though Kafka itself is limited to communication within the virtual network, other services on the cluster such as SSH and Ambari can be accessed over the internet. For more information on the public ports available with HDInsight, see Ports and URIs used by HDInsight.
While you can create an Azure virtual network, Kafka, and Spark clusters manually, it's easier to use an Azure Resource Manager template. Use the following steps to deploy an Azure virtual network, Kafka, and Spark clusters to your Azure subscription.
Use the following button to sign in to Azure and open the template in the Azure portal.

Warning
To guarantee availability of Kafka on HDInsight, your cluster must contain at least four worker nodes. This template creates a Kafka cluster that contains four worker nodes.
This template creates an HDInsight 4.0 cluster for both Kafka and Spark.
Use the following information to populate the entries on the Custom deployment section:
Property Value Resource group Create a group or select an existing one. Location Select a location geographically close to you. Base Cluster Name This value is used as the base name for the Spark and Kafka clusters. For example, entering hdistreaming creates a Spark cluster named spark-hdistreaming and a Kafka cluster named kafka-hdistreaming. Cluster Login User Name The admin user name for the Spark and Kafka clusters. Cluster Login Password The admin user password for the Spark and Kafka clusters. SSH User Name The SSH user to create for the Spark and Kafka clusters. SSH Password The password for the SSH user for the Spark and Kafka clusters. 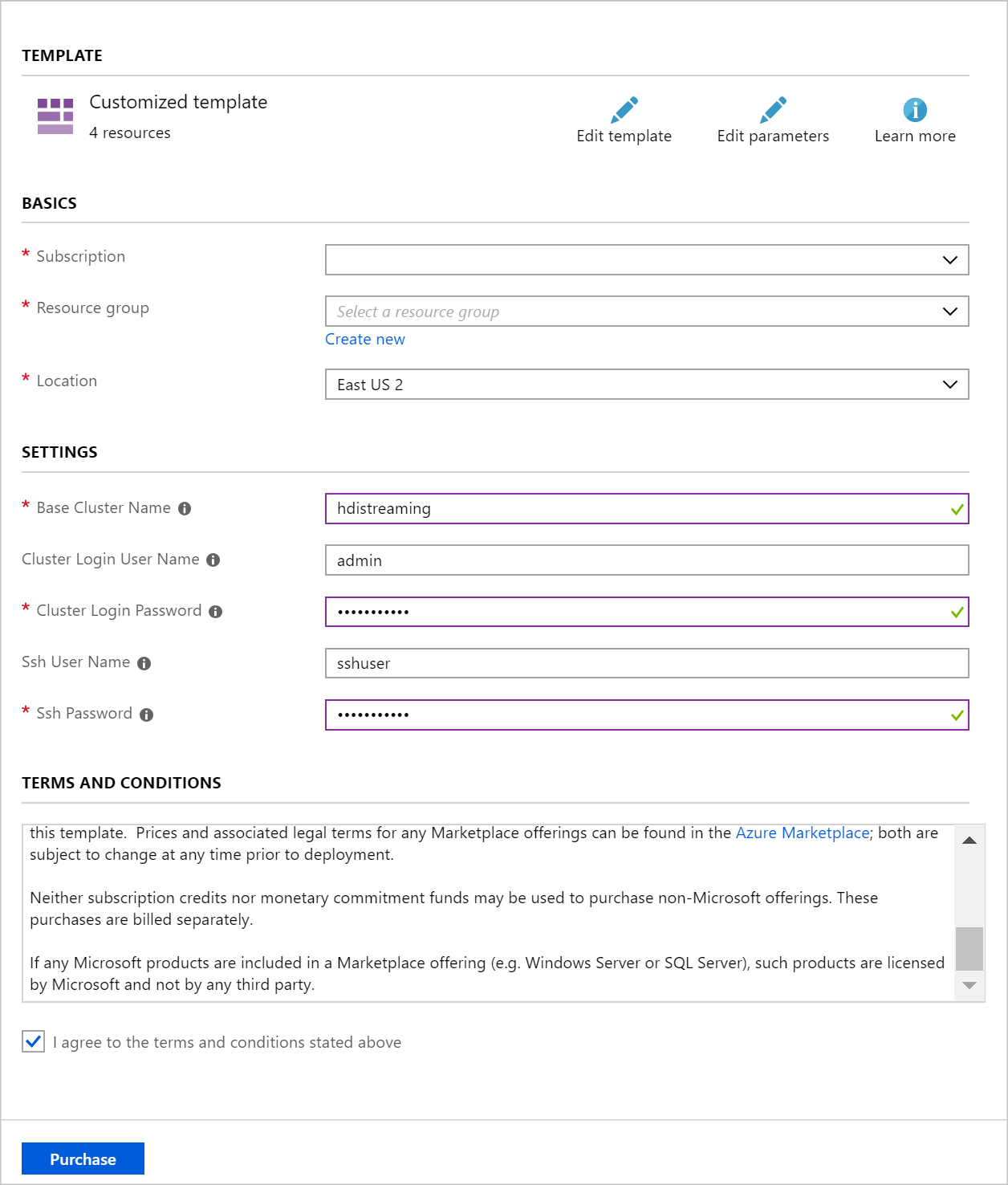
Read the Terms and Conditions, and then select I agree to the terms and conditions stated above.
Finally, select Purchase. It takes about 20 minutes to create the clusters.
Once the resources have been created, a summary page appears.
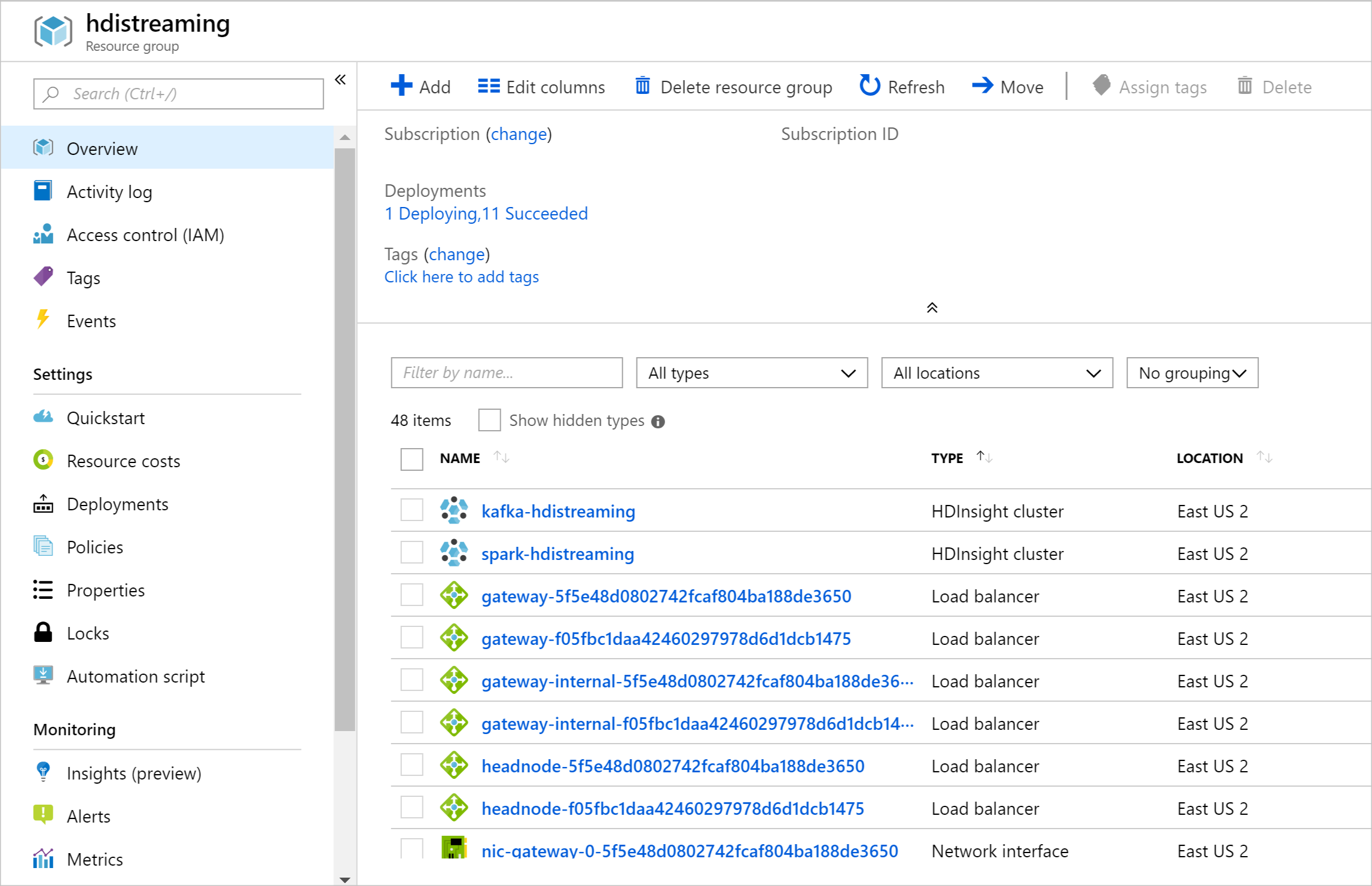
Important
Notice that the names of the HDInsight clusters are spark-BASENAME and kafka-BASENAME, where BASENAME is the name you provided to the template. You use these names in later steps when connecting to the clusters.
Use the notebooks
The code for the example described in this document is available at https://github.com/Azure-Samples/hdinsight-spark-scala-kafka.
Delete the cluster
Warning
Billing for HDInsight clusters is prorated per minute, whether you use them or not. Be sure to delete your cluster after you finish using it. See how to delete an HDInsight cluster.
Since the steps in this document create both clusters in the same Azure resource group, you can delete the resource group in the Azure portal. Deleting the group removes all resources created by following this document, the Azure Virtual Network, and storage account used by the clusters.
Next steps
In this example, you learned how to use Spark to read and write to Kafka. Use the following links to discover other ways to work with Kafka: